

SQLチューニング 基礎

こちらは、公式アドベントカレンダー2024【A】IT技術関連トピック Day.7 の記事です。
公式アドベントカレンダー2024【B】仕事術・キャリア・体験記も毎日記事を公開していますので、ぜひあわせてご覧下さい。
★Day6のアドベントカレンダー記事
エンジニアと共創するDevRelのこだわり(DevRelグループ長 あやなる (チャンドラー彩奈))
この記事を読むとできるようになること
SQLチューニングの全体像がわかるようになる
SQLチューニングの方針の立て方がわかるようになる
SQLチューニングに必要なコマンドの意味がわかるようになる
SQLチューニングに実行計画を利用するときのコツがわかるようになる
はじめに
最近SQLチューニングの仕事をしているので、ネットで参考になる記事を検索することがあるのですが、こういうのがあったらいいなと日頃思っている記事があまり無かったので、自分で書いてみようと思います。
どういうのがあったらいいなと思っているのかと言うと、以下のような事を説明している記事です。
どういう風に方針を立てているのか
実際にどういう手順でやっているのか
どんなコマンドを使っているのか
コマンドの実行結果を見て何を考えているのか
今回は理論的な解説はなるべくなくし、絵や動画を使って、初心者の方でもおおまかな感覚をつかんでもらえるように解説していきたいと思います。
今回のテーマ
今回のテーマはSQLチューニングです。
ユーザーはSQL(※1)を実行し、データベースが結果を返します。この時間を調整(チューニング)することがSQLチューニング(※2)です。
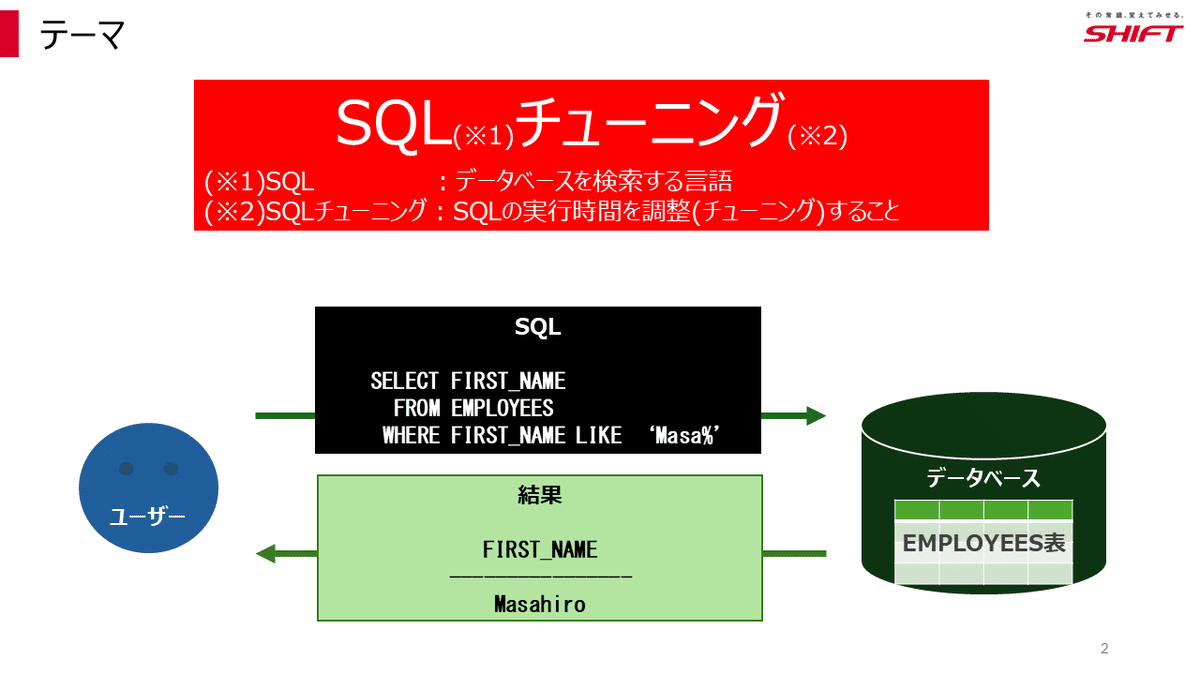
(※1)SQL:データベースを検索する言語
(※2)SQLチューニング:SQLの実行時間を調整すること
事前準備
チューニングをやっていく前に検証環境を説明します。
今回使う表
今回はORACLEが提供しているサンプルスキーマ(※3)を使います。
HR(Human Resources; 人事部)スキーマ(※4)のEMPLOYEES(従業員)表とDEPARTMENTS(部門)表(※5)を使います。
検証用にこれらの表データを増幅し、レコード件数を増やしています。
従業員表は増幅して約350万レコードにしました。EMPLOYEE_IDがPrimary Key(主キー)(※6)と言って、レコードを一意に特定するIDです。
FIRST_NAMEは「姓名」の「名」です。今回はFIRST_NAMEがMasaで始まる従業員を検索します。LAST_NAMEは「姓」です。DEPARTMENT_IDは部門IDで、部門表への外部キー(※7)と言って、部門表のDEPARTMENT_IDを参照するIDです。
部門表も増幅して3,456レコードにしました。DEPARTMENT_IDが部門表の主キーで、従業員表のDEPARTMENT_IDから参照されています。DEPARTMENT_NAMEが部門名です。

(※3)サンプルスキーマ:https://github.com/oracle-samples/db-sample-schemas/releases サンプルスキーマのインストール方法については別の記事で説明していこうと思います。
(※4)HR(Human Resources; 人事部)スキーマ:ORACLEが以前から提供しているサンプルスキーマです。ORACLEエンジニアの方にはおなじみですね。
(※5)EMPLOYEES(従業員)表とDEPARTMENTS(部門)表:やはりHRスキーマを検索したことがある方にはおなじみですね。SQLを習う時に使うことが多いのではないでしょうか。
(※6)Primary Key(主キー):例えばEMPLOYEE_IDが27492のレコードは1つしかありません。
(※7)外部キー:例えばEMPLOYEE_IDが27492のDEPARTMENT_ID: 90は部門表のDEPARTMENT_ID: 90の行につながっています。外部キーを使って従業員表と部門表を結合して一緒に検索することができます。主キーや外部キー、表結合については別の記事で説明していこうと思います。
今回チューニングするSQL文
今回チューニングするのはSELECT文と言って、テーブルを検索してデータを取ってくる文です。レコードを検索して取ってきますが、レコードの変更や削除はしません。
今回のSQL文は以下のような形をしています。(※8)

FROMの後の"EMPLOYEES EMP, DEPARTMENTS DEPT"で従業員表と部門表を検索することを表現しています。
WHEREの後の"EMP.DEPARTMENT_ID = DEPT.DEPARTMENT_ID"が従業員表と部門表を結合する条件です。従業員表のDEPARTMENT_IDは部門表のDEPARTMENT_IDを参照する外部キーになっているのでこのように2つの表を結合して値が一緒の行だけを検索することができます。
"EMP.FIRST_NAME LIKE 'Masa%'"は従業員表の「名」がMasaで始まる(※9)レコードを検索するということです。直前に"AND"が付いているので「2つの表を結合して値が一緒、かつ、従業員表の名がMasaで始まるレコードを検索する」という意味になります。
(※8)今回はORACLEが定めた構文で書いています。これとは別にANSI(米国規格協会)とISO(国際標準化機構)が定めた構文もあります。
(※9)LIKE 'Masa%'はMasaで始まり、その後ろはなんでも良い(%はワイルドカード)という意味です。これで前方一致検索になります。前方一致検索をすると文字列検索でインデックスを使うことができます。'%sahi%'のような中間一致や'%hiro'のような後方一致については単にFIRST_NAMEにインデックスを付けても速い検索になりません。これについては別の記事で説明していこうと思います。
遅い例
後でデモを見ていくのですが、最初は以下のような遅い例のようになります。


約350万レコードある従業員表を全て取り出します。データベースのメモリに何もレコードがない時(※10)は約350万の従業員表のレコード全てをディスクからメモリにいったん取り出します。(※11)この、「ディスクから約350万レコードを取ってくる」ような「大量のレコードをテーブルから全件取ってくる処理」はSQLチューニング的には非常に遅い処理です。今回のSQLチューニングではこれを改善します。
メモリに取り出した約350万レコードのFIRST_NAMEをチェックし、"Masa"で始まるレコードに絞り込みます。
絞り込んだレコードのDEPARTMENT_IDを見て、同じDEPARTMENT_IDを持つ部門表のレコードを取り出します。
処理した結果を整理してユーザーに返します。
(※10)今回はSQLを実行する直前にキャッシュをクリアするので、SQLを実行する時はメモリに何もレコードがない状態になっています。メモリにレコードがある状態で実行時間を測定すると、処理方式に問題があっても実行時間は短く見えてしまうことがあるので、業務でSQLチューニングをする時は、なるべくキャッシュをクリアしてから実行時間を測定するようにしましょう。
(※11)データベースアーキテクチャやSQLの処理の仕方を知っていた方が理解しやすいのですが、また別の機会に説明します。今回はざっくりと「表のレコードはディスクからメモリに取り出し、メモリ上で処理する」というイメージでいてください。
速い例
先ほどの遅い例では「ディスクから約350万件レコードを取ってくる」ような「大量のレコードをテーブルから全件取ってくる処理」が良くないのでした。
速くするには「ディスクから必要なレコードだけを取ってくる」のような処理が必要です。インデックス(索引)(※12)と言うものを使うとそのようなことができます。従業員表のFIRST_NAMEにインデックスを作ると下の図のような木構造のデータが出来上がります。FIRST_NAMEが"Masa"で始まる名を検索すると次のように検索します。


最初に"A..Z"のデータ(※13)を読みます。インデックスはアルファベット順に並んでいるので、"M"で始まるFIRST_NAMEは枝分かれした先の"K..Q"(※14)の下にあるとわかります。
"K..Q"のデータを読みます。次は"M"のデータを読めば良いとわかります。
"M"のデータを読みます。ここで枝分かれは終わっていて、FIRST_NAMEの文字列とROWIDと言う「表の中のレコードの位置がズバリわかるデータ」があります(※15)。
今回はインデックスを検索するとFIRST_NAMEが"Masa"で始まる「名」が1件だけ見つかり、ROWID(従業員表のレコード位置がわかるデータ)が取れます。
このROWIDで従業員表の1レコードをズバリ取り出すことができます。
仮に図のように検索を進めた場合、インデックスの読み取りで"A..Z"のデータ、"K..Q"のデータ、"M"のデータ、表の読み取りでROWIDに対応するデータ、と4つほどデータを読み取るだけで350万レコードもある従業員表から欲しいデータを取り出せるということです。今回の例のように、大量のレコードを含む表の特定の列を前方一致検索する場合は、インデックスを使うとテーブルを全件取ってくるよりも相当速く検索できるケースが多いので認識しておきましょう。
(※12)インデックス(索引):インデックスについては別のブログ記事 で説明しています。
(※13)木の根なので「ルート」と言います。また、データは「ブロック」という単位で保存されています。合わせて「ルートブロック」のように言います。
(※14)枝分かれした途中のデータ(ブロック)を「ブランチ」と言います。つまり「ブランチブロック」のように言います。
(※15)インデックスを作った列の値とROWIDを保存しているブロックを「リーフブロック」のように言います。
デモ
ここからは実際にSQLチューニングをやっていきます。
アプリユーザーでログインする
sqlplusはORACLEでSQLを実行するためのクライアントです。 今回は"hr"というユーザーがアプリユーザーです。(※16)

(※16)"/"の後の"hr"がパスワードです。この環境は検証用に単純なパスワードにしていますが、業務で使うデータベースでは複雑で見破られにくい文字列にしましょう。"@orclpdb"は接続文字列と言い、ORACLEに接続するための名前です。この辺はマニュアルやネットで記事が出ているので検索してみてください。
アプリユーザーで前準備をする
SQLを実行する前に、コマンドの結果を見やすくしたり、SQLチューニングに役立つ情報を表示したりといった設定をしています。(※17)


(※17)詳しいことは別の記事で説明しようと思います。今は「おまじないが必要」くらいに考えておいてください。
管理者ユーザーでログインする
アプリユーザーはキャッシュをする権限を持っておらず(※18)キャッシュをクリアできないため、別画面で管理者ユーザーとしてログインします。"sys"というのが管理者ユーザーで、「SYSDBA権限」を持っているのでキャッシュをクリアできます。"sys"ユーザーでログインする時は、最後に"as sysdba"という指定が必要です。

(※18)アプリユーザーに「SYSDBA権限」か「ALTER SYSTEM権限」というものを付与すればできなくはないのですが、今回の環境では付与していません。業務で使うデータベースでも、アプリユーザーはアプリケーションン開発者が使えるようにするものの、「SYSDBA権限」や「ALTER SYSTEM権限」はDBA(データベース管理者)だけが使えるようにして、権限分離するのが一般的だと思います。
管理者ユーザーでキャッシュをクリアする(1回目)
共有プールというのはSQLを解析した結果や実行計画が含まれているメモリ領域です。このメモリ領域はSQLの実行時間に影響するのでいったんクリアしています。
バッファキャッシュというのは従業員表や部門表から取ったデータをキャッシュしているメモリ領域です。ここにデータが残っていると全部ディスクからデータを取ってくる時と実行時間が違ってしまうのでクリアしておきます。(※19)


(※19)ORACLEのアーキテクチャについて理解したほうが良いのですが、別の記事にしようと思います。今は「おまじない」の認識で良いです。
アプリユーザーで従業員表と部門表を検索する(1回目)
従業員表と部門表を検索するSQLを実行します。

今回は全体で1.91秒かかりました。この時間には、データベース側で処理している時間だけでなくsqlplusクライアントで結果を受け取って表示するまでの時間が含まれています。 実行統計の欄を見るとgetsが41,723個あったことがわかります。getsというのはデータを取るためにディスクとメモリから読み込んだ量が含まれています。getsが多いとメモリ上で処理するデータ量が多くなり、処理が遅くなってしまいます。「getsをできるだけ少なくする」というのがSQLを速くするためのセオリーです。
アプリユーザーで実行計画を表示する(1回目)
実行計画を表示します。

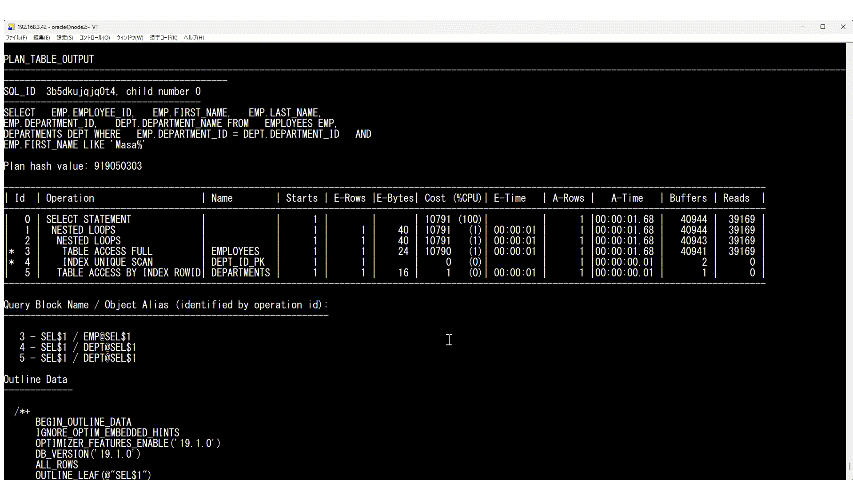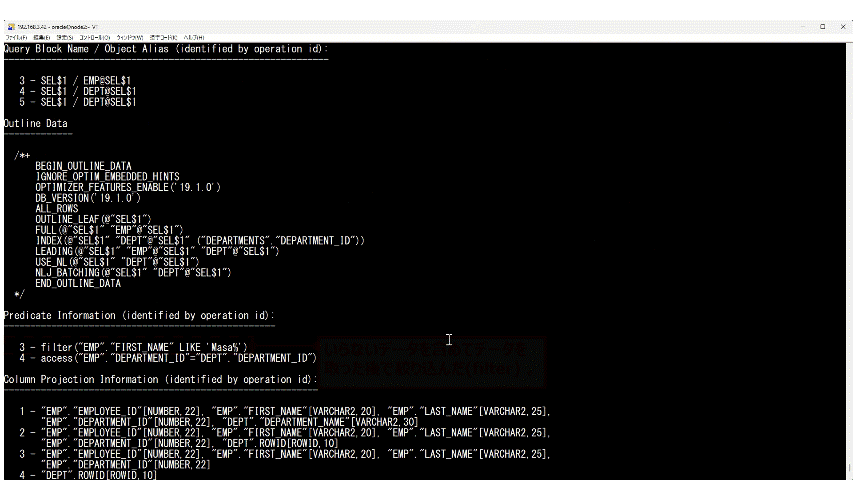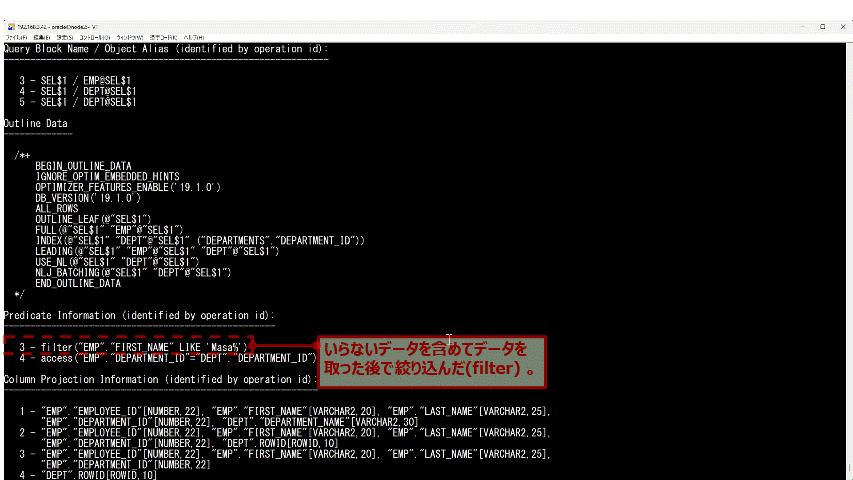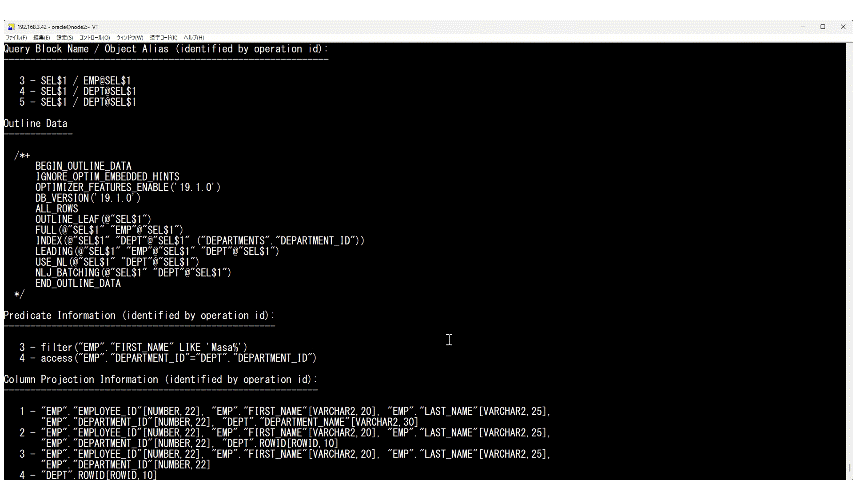
表のように出ているところが実行計画です。
"A-Time"がその処理でかかった時間、"Buffers"がディスクとメモリから読み込んだ量です。"Buffers"というのは"gets"と同じと考えてください。
"Id: 3"の行を見ると、従業員表の検索だけで1.68秒かかっていることがわかります。 また、Buffers(Gets)が従業員表の検索だけで40,491個あったことがわかります。
下の方を見ていくと"Predicate Information"(※20)という欄があります。 WHERE句を処理する時にどの条件でレコードを取りに行ったのかがわかります。
"3 -"で始まる行が実行計画の"Id: 3"に対応しています。"Id: 3"で"TABLE ACCESS FULL"という"Operation"をして"EMPLOYEES"という"Name"(名前)のテーブルの全レコードを取った時に"FIRST_NAME LIKE ’Masa%'"という条件でフィルタ(filter)したことがわかります。
最初のうちはあまり必要ないかもしれませんが、"Predicate Information"を見るとテーブルやインデックスをどの条件で検索していたのかがわかります。
(※20)"Predicate"というのは「述語」という意味です。"Predicate Information"を見ると、どのような条件式で処理したのかがわかります。
アプリユーザーでインデックスを作成する
アプリユーザーでインデックスを作成します。 "EMPLOYEES"表の"FIRST_NAME"列に"EMP_FIRST_NAME_IX"という名前でインデックスを作成しました。

管理者ユーザーでキャッシュをクリアする(2回目)
インデックスを作成したので、もう一度SQLを実行してみます。
キャッシュにデータが残っていると実行時間が違ってしまうので今回も忘れずにクリアします。

アプリユーザーで従業員表と部門表を検索する(2回目)
先ほどのSQLを実行します。

今回は全体で0.37秒でした。前回の1.91秒から速くなりました。
getsは前回の41,723個から882個に減りました。
実行時間にして5倍以上、getsの回数は約50分の1に削減できました。
絶対ではありませんが、今回のような「大量レコードの表から少数のレコードを取ってくるSQL」の場合はgetsが減れば実行時間が短くなります。
アプリユーザーで実行計画を表示する(2回目)
実行計画を見ていきます。


今回はインデックスを検索する処理に変わったので実行計画の形が少し変わりました。
"Id: 4"のところでインデックスを検索しています。"INDEX RANGE SCAN"という"Operation"で"EMP_FIRST_NAME_IX"を検索しており、"A-Time"が0.01秒、"Buffers"(Gets)が3個と出ています。先ほどは1.68秒と40,491個だったので正に「桁違いの改善」ですね。
"Predicate Information"も見てみます。 "4 -"で始まる行が実行計画の"Id: 4"に対応しているのでした。
"Id: 4"で"INDEX RANGE SCAN"で"EMP_FIRST_NAME_IX"を検索した時に"FIRST_NAME LIKE ’Masa%'"という条件でアクセス(access)したことがわかります。インデックスをディスクから取り出す時に必要なデータだけを探していることがわかります。
まとめ
大量データの表から少しのデータを検索する場合は以下がセオリーです。
インデックスで検索する
つながっている表を検索する
(1+2の合計でgetsが少ないほど速くなります)
SQLチューニングの手順は以下のようになります。(※21)
SQL文を見る。どのくらいの実行時間でどのような実行計画が良いかをイメージする
アプリユーザーで前準備(おまじない)をする
管理者ユーザーでキャッシュをクリアする
アプリユーザーでSQLを実行する
アプリユーザーで実行計画を表示する。A-Time、Buffersを見て遅い原因を見つける
遅い原因に対処する
2から5を繰り返す。良い実行計画になったり実行時間が短くなったりしたら完了
以上でSQLチューニングの基礎は終わりです。
別の機会に、今回触れなかった内容についても説明していこうと思います。 皆さんの現場でも試してみていただければ幸いです。
ここまで読んでいただきありがとうございました。
(※21)筆者の場合です。「絶対こうしなければならない」というものはありません。人や関わっているプロジェクトによって少しずつアレンジしていくと良いと思います。
執筆者プロフィール:小澤 雅弘
DBMSベンダー、ISPなどでDB関連のプロジェクトを20数年経験。得意領域はDBのパフォーマンスチューニング。
初心者の方にもわかりやすい説明を心がけています。
★SHIFTグループ公式アドベントカレンダー2024【A】 IT技術関連トピック Day8は「devcontainerでBun+React+Vite構成のフロントエンド開発環境を構築する」(矢坂 拓)
お問合せはお気軽に
SHIFTについて(コーポレートサイト)
SHIFTのサービスについて(サービスサイト)
SHIFTの導入事例
お役立ち資料はこちら
SHIFTの採用情報はこちら
PHOTO:UnsplashのMaximalfocus