

Amazon DynamoDB の Single Table Design とは? 使い方と設計の手引き

株式会社SHIFT インフラサービスグループの山下と申します。パブリッククラウドを活用したサービス設計・構築を主な業務としています。
今回は Amazon DynamoDB の効果的なデザインパターンである Single Table Design をご紹介したいと思います!
Amazon DynamoDB は NoSQL のデータベースサービスですが、実際にどのようにスキーマ設計をするのかイメージが掴めず、DB としての候補にすら挙げづらいといった側面があるのではないでしょうか?
本記事では、Amazon DynamoDB でどのようにスキーマ設計を行うのかを解説します。AWS をご存知ない方でも理解できる内容となっております!Amazon DynamoDB を組み込んだアーキテクチャをお客様に提案できるようになるレベルまでの内容を含んでいますので、是非最後までご一読ください!
Amazon DynamoDB とは?
Amazon DynamoDB は AWS が提供する DB サービスの 1 つで、スキーマレスな DBMS です。
ただし、「スキーマレス」とは全くスキーマが存在しないという意味ではなく、柔軟なデータ構造を許容しつつ、厳密なスキーマ定義を必須としないことを指します。この用語は「サーバレス」に似たニュアンスで使われることがあり、たとえば「サーバレス」がサーバを意識せずに利用できる環境を意味するのと同様に、「スキーマレス」もスキーマを固定的に意識せずに扱える柔軟性を強調しています。
パーティションキーとソートキーが DynamoDB のスキーマの一部に相当しますが、これ以外のカラムは特にスキーマを固定する必要がありません。これがスキーマレスと謳われる所以です。
Single Table Design とは?
Single Table Design とは、1つのテーブルで複数のエンティティを管理するNoSQLの強みを生かしたデザインパターンです。
より具体的に言うと、顧客情報・注文情報・商品情報など異なる構造を持つデータをすべて1つのテーブルに格納するということです。
全てのエンティティを1つのテーブルに格納してどのようにデータフェッチを行うのか?という疑問にお答えするには、先ずは DynamoDB のデータ保存とデータ取得の仕組みについて触れる必要があります。
パーティションキーとソートキー
パーティションキーとソートキーは DynamoDB において特別な属性です。
テーブルを作る際に、以下のどちらかを選択できます。
パーティションキーのみを指定する
パーティションキーとソートキーを指定する
パーティションキーのみの場合はパーティションキーが主キーとなります。パーティションキーとソートキーの組み合わせの場合は 2 つの属性の複合主キーとなります。
この設定はテーブル作成後は変更することができません。
また、パーティションキーとソートキーの値は更新が不可能です。書き換えたい場合は一度アイテムを削除するしかありませんが、書き換えないで済む設計をするべきです。NoSQL 全般に言えることですが、データの非正規化を是としてデータを追加していくことが推奨されます。
パーティションキー
パーティションキーはデータの配置場所を決めるキーです(パーティションとデータの分散配置 )。パーティションキーが同じレコードは、同じパーティションに配置されます。以降、カラム名では PK と記載します。

各パーティションには制限があり、テーブルに 1 つ以上の LSI がある場合はパーティション 1 つあたり 10GB までのデータ制限 があります。
また、データが各パーティションに分散していないとデータスループットにスロットリングが起きる可能性があります(ワークロードを分散するパーティションキーの設計 )。そのため LSI を使用しない場合でも各パーティションにデータが分散するように設計するのが望ましいです。
注記: LSI の用途は限定的であり、後の項でも必要でない知識のため省略しています。Single Table Design のような結果的整合性を求める設計の場合は LSI は基本的に使用しません。
ソートキー
ソートキーはパーティションの中でアイテムが並ぶ順番を決める属性です(パーティションとデータの分散配置 )。ソートキーを使用してパーティション内で検索(Query)を行うことができます。以降、カラム名では SK と記載します。

DynamoDB でのデータ取得方法
RDB の API は RDBMS ごとの独自の通信プロトコルを使用して通信しクエリ言語に SQL を使用するものですが、DynamoDB は HTTP API で操作を行います。また、この HTTP クライアントとして AWS SDK などのラッパーライブラリがあり、多くの場合こちらを使用して開発を行うことになります。
ちなみに、AWS SDK は複数の主要な言語に対応していますが、これらの SDK は Smithy という IDL から自動生成されたコードであるため、どの言語でも似たような API を提供することに成功しています。また、その性質上更新も迅速で安定しており安心して使用できます。
GetItem
GetItem は一意のレコードを取得する操作です。
テーブルを作る際にパーティションキーのみで作成すると、パーティションキーのみを指定してデータを取得できます(パーティションキーがユニークになるため)。
テーブルを作る際にパーティションキーとソートキーを使用すると、パーティションキーとソートキーを指定することでデータを取得できます(パーティションキーとソートキーの複合がユニークになるため)。
この操作は DynamoDB からのデータ取得で最も効率の良い方法です。
また、1 回の API リクエストで100 件までの GetItem と同等の操作を実行できる BatchGetItems も存在します(Amazon DynamoDB Batch Operations )。
Query
Query は特定のパーティションキーの中から、ソートキーに関する条件を使用してデータを探索する操作です(DynamoDB テーブルにクエリを実行する )。そのためパーティションキーのみでテーブルを作成すると使用できません。
Query では、ソートキーに対して等しい・以下……などと様々な条件を使用してデータを探索できる非常に便利な操作です。しかし、ソートキー以外には使用できないため RDBMS と比べて自由度が減ってしまっています。
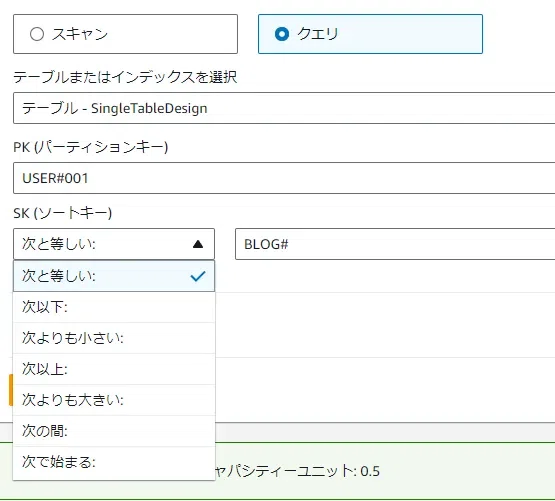
Amazon DynamoDB で使用できる Query 操作の条件式
ちなみに Query の API 実行時にフィルター を使用してさらに他属性(ソートキーでない属性)をフィルタリングできますが、DynamoDB 自体が消費するキャパシティユニットは変わりません(データ転送量は減ります)。
Scan
Scan はテーブル内のすべてのレコードを取得する操作です。非常に非効率な操作であるため、特別な理由がない限り恒常的に Scan 操作を行うような設計は避けるべきです(クエリとスキャンのベストプラクティス )。
DynamoDB のデータベース設計においては、Query, GetItem のみで目的のデータを取得できるようにすることが目標です。
RDB を DynamoDB に移行する
本項では、実際に RDB で実装していたものを DynamoDB で表現するとどうなるかについて、具体例を提示して解説していきます。
例としてブログ投稿サービスを考えます。ユーザーは E メールでアカウントを作成し、メールアドレスをログイン ID としてパスワードでログインします。ログイン後はブログを投稿することができます。
サービス提供のためには以下のクエリができることが必要です。
特定のブログ記事を取得する
投稿順(作成順)に最新のブログ 3 件を取得する
特定の E メールからユーザーを取得する
特定のユーザーのブログ記事一覧を取得する
必要最小限のテーブルを作成すると以下のようになります。

特定のブログ記事を取得するには、Users テーブルと Blogs テーブルを結合し blogID によってクエリを行えば 1 件のブログが取得できます。
投稿順(作成順)に最新のブログ 3 件を取得するには、Blogs テーブルから createdAt カラムの降順にソートして 3 件のブログを取得すればよいです。
特定の E メールに紐付いたパスワードカラムを取得するには Users テーブルから username でクエリを行えばよいです。
特定のユーザーのブログ記事一覧を取得するには、Users テーブルと Blogs テーブルを結合し userID によってクエリを行えば該当ユーザーのブログ一覧が取得できます。
上記の内容を DynamoDB で実装するとどうなるでしょうか?
DynamoDB での実装
DynamoDB の Single Table Design で上記の実装を行うと次のようになります。
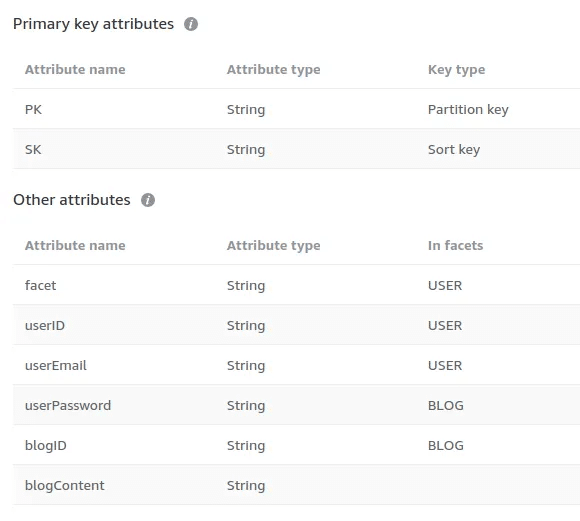
こちらに記載されている属性はすべて 1 つのテーブルに格納されます。データの種類はユーザーとブログの 2 種類ありますが、DynamoDB は自由に属性を追加できるスキーマレスな DBであるためこのようなことが可能です。
サンプルデータを挿入した DB がこちらになります。
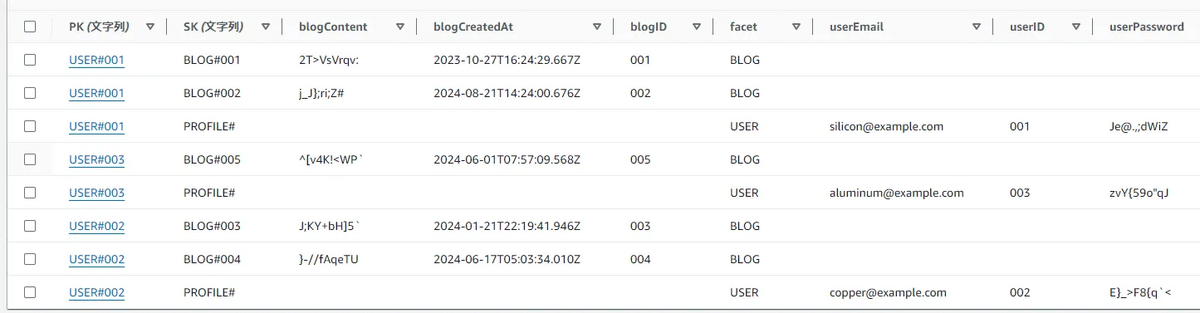
スキーマがバラバラになっており、目的のデータが取得できないように見えますが、こちらは ファセット という概念によってそれぞれのレコードの持つ属性が識別されています。
ファセット
DynamoDB は、異なるデータ構造のレコードをすべて 1 つのテーブルに挿入することがあります。これは DynamoDB のメリットでもありますが、どのレコードが何の情報を格納したものであるかを識別する手段がなければデータの取り扱いが難しくなってしまいます。
DynamoDB では、それぞれのレコードを識別するために ファセット を使用しています。ファセットはどの属性を持つかをそれぞれ指定しています。ファセットは DB 側で制限をかけるスキーマではなく、開発者がよりデータを扱いやすくするためにデータベース設計で作成するという点に注意してください。
例えば、先ほどお見せした DynamoDB のレコードのファセットを見てみます。
USER ファセット
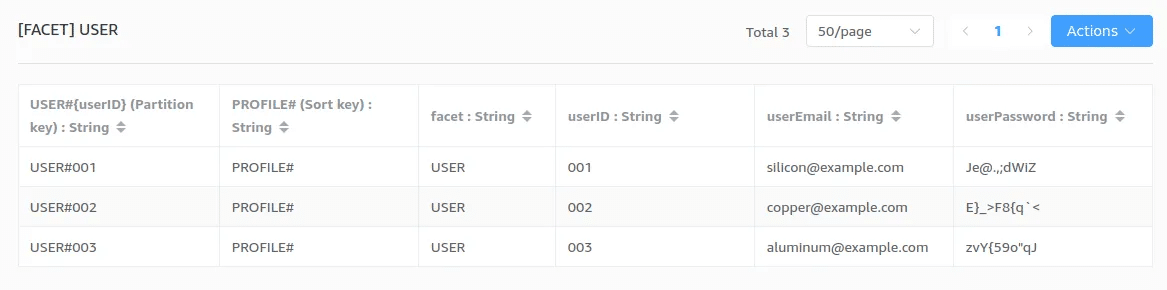
こちらの USER ファセットでは、PK, SK, userID, faset, userEmail, userPassword の 5 つの属性を持つように設定しています。
BLOG ファセット
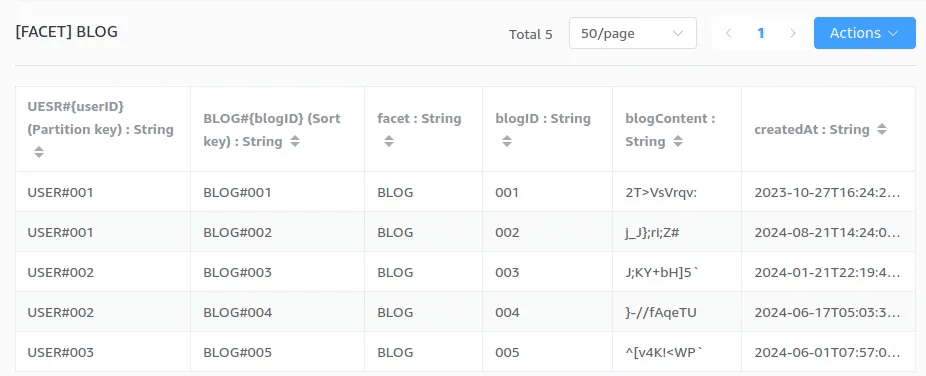
一見無法地帯に見えた先ほどのレコードも、ファセットごとでは必要なデータが纏まっています。NoSQL ではこのようにデータのスキーマを管理しているのです。
データの取得パターンから DB を設計する
ファセットを使用して異なるスキーマのアイテムを同じテーブルに挿入し、かつ識別できるようになりました。次は実際にデータを取り出す方法を考えなければなりません。
DynamoDB はソートキーでのみクエリが可能であるため、ソートキーに識別可能な情報を入れることが肝要です。そしてソートキーに入れるべき情報はアクセスパターンから考えます。
今回例に挙げたシナリオでは、以下のクエリができることが必要でした。
特定のブログ記事を取得する
投稿順(作成順)に最新のブログ 3 件を取得する
特定の E メールからユーザーを取得する
特定のユーザーのブログ記事一覧を取得する
これらすべてのアクセスパターンに対応できるように設計を進めます。
特定のブログ記事を取得する
ブログ記事を一意に取得するにはパーティションキーとソートキーで GetItem 操作を行います。
例えば、以下のテーブルから特定のブログのアイテムを取得するとき、
PK=USER#001
SK=BLOG#001
とすることでデータを取得できます。
投稿順(作成順)に最新のブログ 30 件を取得する
こちらは、ブログ記事の作成日を属性に追加して保存しないといけません。そのため BLOG のファセットには createdAt という属性を追加しました。

追加した createdAt を降順に並び替えるにはクエリをする必要がありますが、こちらの属性はソートキーではありません。
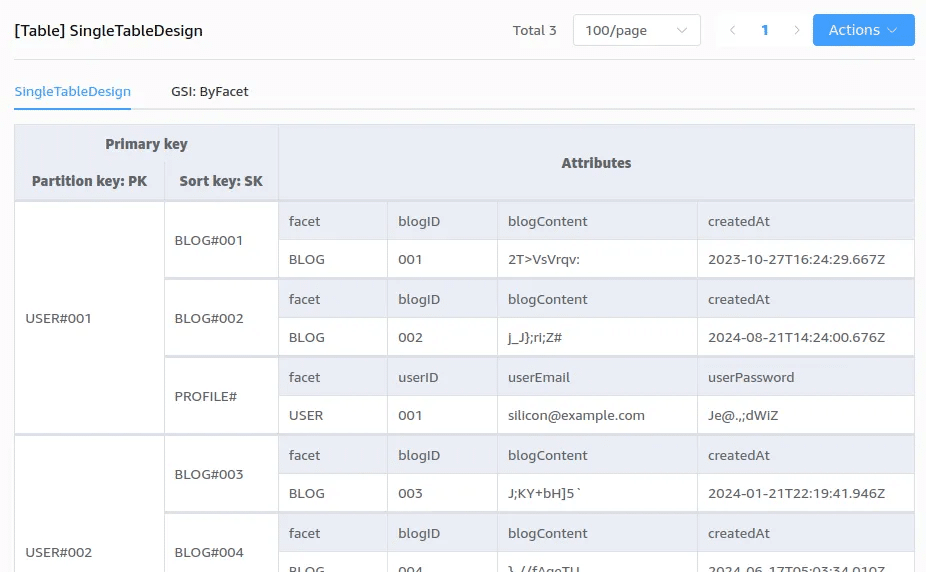
このような時に使用する機能が GSI (Global Secondary Index) です。
GSI は何を行うかというと、新たにパーティションキーとソートキーを属性から指定して、テーブルを複製します。
今回は facet をパーティションキー、createdAt をソートキーに設定して新たな GSI ByFacet を作成しました。

ByFacet GSI は、属性に facet と createdAt を含むアイテムのみを複製し、新たなテーブルを作り出します(以降追加されたアイテムも評価され GSI テーブルに複製されます)。
今回は USER ファセットには createdAt が含まれていなかったため GSI のテーブルのパーティションキーには BLOG のみが現れました。そして本来の目的である createdAt がソートキーに現れました!これでブログを降順に取得することができます!

マネージメントコンソールから実行してみます。先ほど作成した GSI を選択し、パーティションキーに BLOG と入力します。BLOG パーティション内のアイテムはソートキーの昇順に並んでいますが、「降順のソート」にチェックを入れることで降順のクエリも可能です。

実行結果は以下の通りです。期待通り、新しい記事の順番に並んでいます!
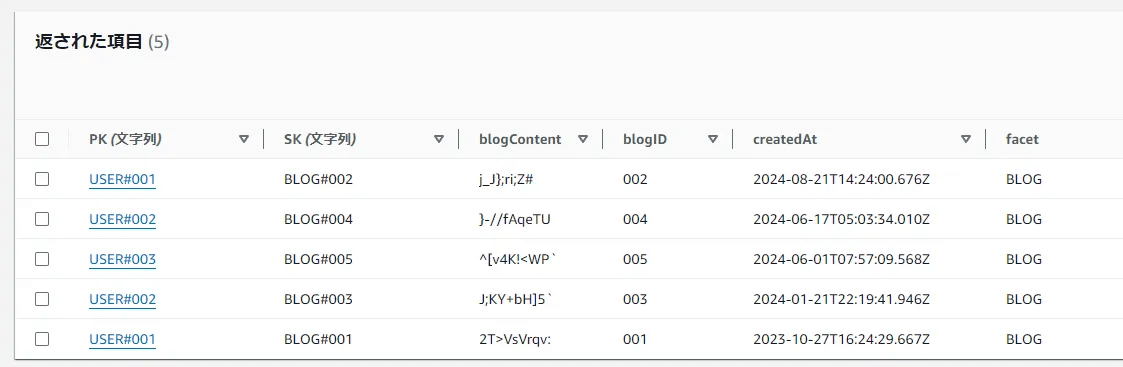
要件は 3 件の記事を取得することでした。マネージメントコンソールでは取得アイテム数を制限できませんが、API 自体には取得アイテム数を制限できるパラメーターがありますので実装時はそちらを使用します(API Reference - Query )。
特定の E メールからユーザーを取得する
こちらも GSI を作成することで対応できます。ただし、今回 GSI で指定する属性はユニークな属性(メールアドレスは一意でなければならない)ため、パーティションキーのみを指定すればよいです。

パーティションキーのみを指定して GSI を作成すると、E メールのみで主キーとなる属性が完成しました。

こちらの GSI に対して GetItem API を呼び出すことで対応するユーザーの情報を取得することができます。
特定のユーザーのブログ記事一覧を取得する
こちらの表結合が必要そうな処理ですが、一番 DynamoDB Single Table Design の強みが出る処理です。
こちらの処理は Query 操作を使用してアイテム取得をするのですが、そのために今までシードデータとして挿入していたアイテムのソートキーに工夫がされていました。
まず、Query 操作で利用可能なオペレーターに「次で始まる:」(begins_with)というものがあります(クエリ操作の主な条件式 )。こちらはソートキーの文字列が前方一致するアイテムを取得することができます。

ここでテーブルに戻り、USER#001 のソートキーを見ていただくと、BLOG# から始まっていることに気付くと思います。このようにソートキーにファセットに関するプレフィックスを入れておくことで、余計な GSI や属性を増やすことなくアイテムを取得できるのです。
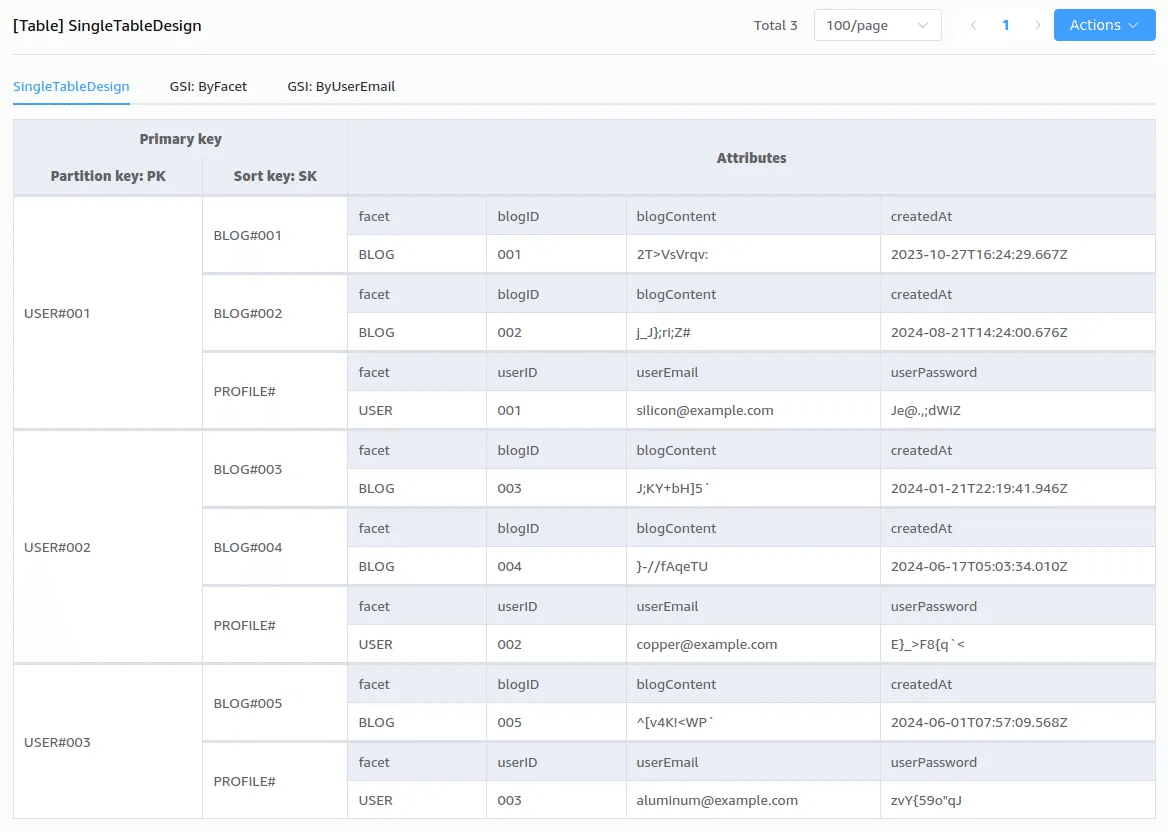
以下のように PK が USER#0001 のパーティションに対して BLOG# で始まるクエリを実行することで USER#001 のブログをすべて取得することができました!

こちらの # でソートキーの情報を階層化する方法は AWS デベロッパーガイド でもベストプラクティスとして紹介されています。
上述の DynamoDB での 1 対多のデータ取得方法については、RDBMS と比べテーブルの結合の必要がなく非常に低いレイテンシで結果を返せるという点でメリットがあります。
DynamoDB で多対多を実装してみる
次の要件が増えたとします。
ブログに複数のタグをつけることができるようにする。ブログ閲覧時にブログについているタグをすべて表示する。加えて、特定のタグが付いているブログを新着順に一覧表示する。
RDB でも多対多となると中間テーブルが必要になり、複数回の内部結合が必要です。

こちらを DynamoDB で実装してみます。
特定のタグが付いているブログを新着順に一覧表示
TAG と BLOG_TAG_RELATION ファセットを追加しました。


tagID をパーティションキー、createdAt をソートキーとする GSI を作成しました。タグをブログに関連付けるときに、ブログの createdAt を BLOG_TAG_RELATION ファセットの属性にコピーするロジックをアプリケーションで実装します。
作成した GSI のテーブル内容は以下の通りです。
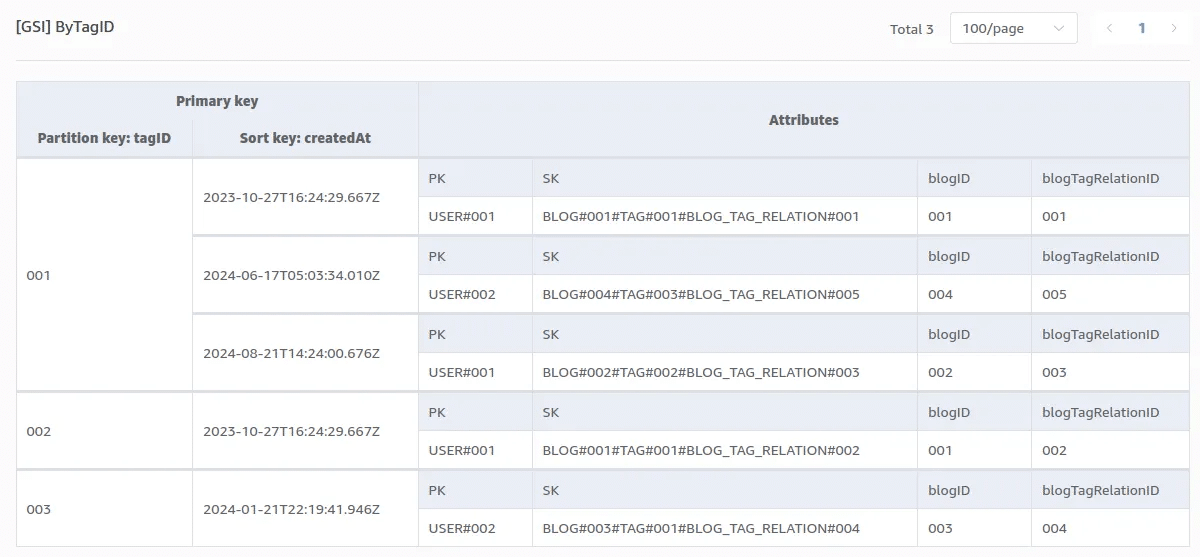
こちらの GSI に対して以下のクエリを実行します。
操作: Query
対象: インデックス - ByTagID
PK: 001
SK: なし (降順ソート)

こちらで blogID が取得できましたので、すべての blogID を指定して BatchGetItem API でブログ一覧を取得します。
ブログについているタグをすべて表示
先ほどまではブログ取得時に PK と SK を指定して GetItem API を使用していましたが、今回は同じ PK と SK を指定し、Query API の begin_with(「次で始まる:」)を使用します。
操作: Query
対象: テーブル
PK: USER#001
SK: 次で始まる: BLOG#001

こちらでブログのアイテムと、ブログとタグの関連付けアイテムを取得できました。tagID を使用して BatchGetItem API を呼び出し、タグ情報を取得します。ブログとタグ情報を 1 つにまとめてフロントエンドに返します。
おわりに
最後まで読んでいただき、ありがとうございました。Amazon DynamoDB の設計をする際にどのように行うかのイメージを掴んでいただけたら幸いです。
執筆者プロフィール: Ikuma Yamashita
主にLinux系のサーバーインフラ・AWSの設計構築を行うインフラエンジニアです。Ansible, Pulumi, Terraform, AWS CDK などの IaC が得意です。学生時代に組み込み(IoT)・ドライバ・web等の開発した経験を活かしてアプリ・インフラチーム間の橋渡しなどを行っています。Rust が至高の言語と信じています
✅SHIFTへのお問合せはお気軽に
SHIFTについて(コーポレートサイト)
https://www.shiftinc.jp/
SHIFTのサービスについて(サービスサイト)
https://service.shiftinc.jp/
SHIFTの導入事例
https://service.shiftinc.jp/case/
お役立ち資料はこちら
https://service.shiftinc.jp/resources/
SHIFTの採用情報はこちら
https://recruit.shiftinc.jp/career/
PHOTO:UnsplashのFrederic Christian