

AnsibleでExcelを読み込むカスタムフィルターを作る

はじめに
ITソリューション部の水谷です。いつもAnsibleの記事ばかり書いていますが、今回もAnsibleに関する記事です(笑)。
さて、インフラ構築のパラメーターシートと言えば、今も昔も「Excelで管理するもの」というイメージが強いですよね(?) 手動で構築を行う際にはもちろんこれを基に導入/設定していくわけですが、構築を自動化する際にもやはり基となるExcelシートがあって、それに沿って自動化していくことが多いですよね。
Ansibleで自動化する場合は、(Excelシートを作らず)AnsibleのPlaybookとインベントリに書かれた変数がパラメーターシートです! と、言い切ってしまうのが理想的かな、と個人的には思ってますが、そうでないならExcelシートの内容を手動あるいはスクリプトでhost_varsに落とし込んでおいて、Playbookを実行したりしています。
そのような場合では、Excelシートの内容をhost_varsに落とし込むステップを省略し、Excelシートを直接Ansibleから読み込んで実行してしまえば良いのでは? という考えが浮かんだりします。そうすればスクリプトを作る作業を省略できるかもしれないのですが、残念ながらAnsibleにはExcelファイルを読み込むフィルターやモジュールは用意されていません。
インフラ構築を例に書きましたが、Ansibleを使っている人の中で私のようにExcelを読み込むフィルターやモジュールがあったらいいな、と思っている方は少なくないのではないでしょうか?
前置きが少し長くなってしまいましたが、「無いものは自分で作ろう」精神で、今回はExcelファイルを読み込むフィルター(正確にはフィルタープラグイン)を作ってみたいと思います。
フィルタープラグインの配置方法
Ansibleはテンプレートエンジンに"Jinja2"を使っていますので、Ansibleのフィルタープラグインを作る≒Jinja2フィルターを作る、ということになります。そして、Jinja2はPython用のフィルターエンジンなので、当然ながら開発言語はPythonです。
もう少し具体的には、フィルタープラグインは1つのクラスとして実装することになります。ファイル名は自由に決められ、そのファイルの中に"FilterModule"というクラスを定義し、そのメソッドとしてフィルターの動作を実装していく感じです。
そのメソッドの実装方法はこの後で見ていきますが、その前に実装したフィルタープラグインをAnsibleから見つけられるようにする方法を確認しておきたいと思います。
まず、一番簡単な方法は、ansible.cfgに"filter_plugins=作成したファイルのパス"を追加することです(下はその例)。
[defaults]
filter_plugins = ./filtersここで1つ問題になるのは、私のようにWindowsのWSL上でUbuntuなどを使ってAnsibleを実行する場合などでは、セキュリティ上の問題でansible.cfgを読み込んでくれないため、別の方法を取る必要があります。
参考:https://docs.ansible.com/ansible/devel/reference_appendices/config.html#cfg-in-world-writable-dir
別の方法としては、環境変数"ANSIBLE_FILTER_PLUGINS"にフィルターのあるディレクトリを設定しておくこと。さらに別の方法として、作成したファイルを以下のいずれかのディレクトリに配置しておくことでも解決できます。
~/.ansible/plugins/filter/
/usr/share/ansible/plugins/filter/
どちらも簡単にできるのですが、問題は別のマシンでこのフィルターを再利用したい場合や、その環境でも手動で同様の設定を行う必要があることです。
どうせ作るなら、いろいろなプロジェクトで簡単に使えるような形で作りたいなと思いましたので、今回は(上に書いたどれでもない)コレクション(Ansible Collection)の形で実装したいと思います。
コレクションの作成
コレクションはAnsibleのバージョン2.9で実装された、ロールやモジュール、およびプラグインなどAnsibleのパーツとなるコードの管理方式で、関連する機能を1つのパッケージにまとめ、名前空間を使って管理することができます。このコレクションを使えば簡単に他のプロジェクトに機能を共有することもできますし、Ansible Galaxyでコミュニティコレクションとして全世界に公開することもできます。
「コレクション」と聞くと、ロールやモジュールがたくさん入ったもの、というイメージがある方も多いのではないかなと思いますが、1つのプラグインが存在するだけのコレクションでもまったく問題ありません。むしろ、今は小さなパーツであっても積極的にコレクションの形で開発していくのがいいのではないかな、と個人的には思っています。
ということで、まずは空のコレクションを1つ作ってみます。
空のコレクションの作成は ansible-galaxy コマンドで以下のように行います。
$ ansible-galaxy collection init {コレクション名} --init-path {コレクションを作成するディレクトリ}今回はWindowsマシンのC:\Projects\Note\Excelというディレクトリをプロジェクトディレクトリとし、そこにPlaybookやインベントリファイルを作成し、コレクションはその下にcollections\ansible_collectionsというディレクトリを作成して、開発することにします。こうすることで、ansible.cfgや環境変数を追加せずにWSL上のUbuntuでもコレクションの動作確認ができます。
また、namespaceは test.excelとしました(かなり安直ですねw)。
以下はWSL上のUbuntuでディレクトリ作成とコレクションのひな形作成のコマンドです。
$ mkdir /mnt/c/Projects/note/Excel/collections
$ mkdir /mnt/c/Projects/note/Excel/collections/ansible_collections
$ ansible-galaxy collection init test.excel --init-path collections/ansible_collectionsこれで、下のようなディレクトリ構造が作成されます。
/mnt/c/Projects/note/excel$ tree
.
└── collections
└── ansible_collections
└── test
└── excel
├── README.md
├── docs
├── galaxy.yml
├── meta
│ └── runtime.yml
├── plugins
│ └── README.md
└── roles今回はフィルタープラグインを作成しますので、pluginsディレクトリの下にプラグインの種別を表す"filter"というディレクトリを作成します。
$ mkdir /mnt/c/Projects/note/Excel/collections/ansible_collections/test/excel/plugins/filterこれで開発準備はできました。
フィルタープラグインを実装する
まずはライブラリ選びで、ちょっと調べてみたところ、PythonでExcelファイルの読み書きを行うライブラリはいくつかあるようでした。有名なところではPandasがありますね。ただ、今回はデータ分析を行うわけではないので、もっとシンプルでネット上に使用例がたくさんある"OpenPyXL"を使ってみることにしました。
OpenPyXLをpipコマンドでインストールしておきます。
$ pip install openpyxlで、先ほど作成したplugins/filterディレクトリに下に適当なファイル名のPythonファイル(拡張子.py)を作成します。
今回は"excel.py"としました。
そして、ここにフィルターを実装するのですが、まずは手始めにExcelファイルの特定のシートの全セルを読み込んでその値を2次元配列で返すフィルターを作ってみました。
コードは、以下のとおりです。
from openpyxl import *
class FilterModule(object):
def filters(self):
return {
'read_excel': self.ReadExcel,
}
def ReadExcel(self, path, *args):
workbook = load_workbook(filename=path, data_only=True)
sheet = workbook[args[0]] if len(args) != 0 else workbook[workbook.sheetnames[0]]
values = []
for r in range (1, sheet.max_row + 1):
temp = []
for c in range(1, sheet.max_column + 1):
temp.append(sheet.cell(row=r,column=c).value)
values.append(temp)
return valuesFilterModuleというクラスを定義し、その中でfitlersというメソッドを定義します。このメソッドはフィルター名とそれを処理するメソッドのdictを返すだけのもので、必ず必要となります。今回は"read_excel"というフィルターが、ReadExcelというメソッドに対応していることを記述しています。なお、今回は1つだけですが、複数記述することもできます。
そして、フィルターの中身であるReadExcelメソッドは、Excelのワークブックをロードし、引数でシートの指定があればそのシートを、指定が無ければ1つ目のシートを開き、そしてシートの中のセルをすべて配列に入れてreturnする、という内容になっています。ストレートでシンプルな実装ですね。
Excelファイルへのパスは、2つ目の引数(path)として渡されます。例えば下のようにフィルターを使った場合、pathは"test.xlsx"となる感じですね。
"{{ 'test.xlsx' | test.excel.read_excel }}"また、フィルターに与えられた引数は、可変長引数として受け取るようにしており、引数があれば、その1つ目をシート名だと解釈するようにしています。例えば、下のようにフィルターを使った場合はargs[0]が"シート1"になりますので、このシートを開いて読み込む動作となり、シートの指定がなかったら一番最初のシートを読むことになります。
"{{ 'test.xlsx' | test.excel.read_excel('シート1') }}"動作テストのために簡単なPlaybookとテスト用シートを作成します。
Playbookは下のように、'test.xlsx'という文字列に対し、フィルターを適用し、引数で指定した'テストシート'という名のシートを読み込んで表示する、という内容です。
---
- hosts: localhost
gather_facts: false
tasks:
- name: show excel data
ansible.builtin.debug:
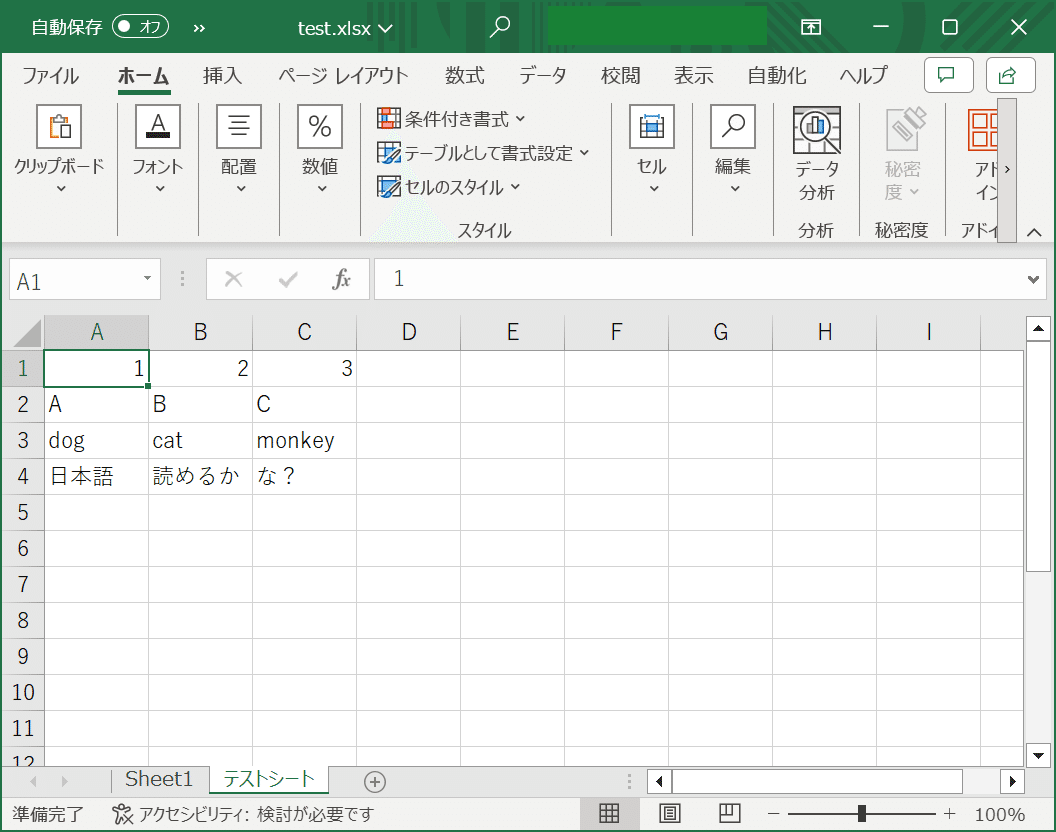
msg: "{{ 'test.xlsx' | test.excel.read_excel('テストシート') }}"Excelシートの'テストシート'は以下のようなものです。
Playbookを実行してみましょう。
$ ansible-playbook site.yml
[WARNING]: provided hosts list is empty, only localhost is available. Note that the implicit localhost does not match
'all'
PLAY [localhost] *******************************************************************************************************
TASK [show excel data] *************************************************************************************************
ok: [localhost] => {
"msg": [
[
1,
2,
3
],
[
"A",
"B",
"C"
],
[
"dog",
"cat",
"monkey"
],
[
"日本語",
"読めるか",
"な?"
]
]
}
PLAY RECAP *************************************************************************************************************
localhost : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0日本語の文字列も含めて、期待通りに読めたようですね。
範囲指定パラメーターを追加してみる
先ほど作成したフィルターは、指定したシートのすべてのセルを読み込む仕様になっていて、やや不便ですので、変数で範囲指定ができるようにしてみましょう。
新たに、read_excel_range という名前のフィルターを下のように追加してみました。
class FilterModule(object):
def filters(self):
return {
'read_excel': self.ReadExcel,
'read_excel_range': self.ReadExcelRange,
}
...
def ReadExcelRange(self, path, startrow, startcolumn, endrow, endcolumn, *args):
workbook = load_workbook(filename=path, data_only=True)
sheet = workbook[args[0]] if len(args) != 0 else workbook[workbook.sheetnames[0]]
if endrow == 0:
endrow = sheet.max_row
if endcolumn == 0:
endcolumn = sheet.max_column
values = []
for r in range (startrow, endrow + 1):
temp = []
for c in range(startcolumn, endcolumn + 1):
temp.append(sheet.cell(row=r,column=c).value)
values.append(temp)
return valuesPlaybookをこのように変えてみます。
---
- hosts: localhost
gather_facts: false
tasks:
- name: show excel data
ansible.builtin.debug:
msg: "{{ 'test.xlsx' | test.excel.read_excel_range(3,2,4,3,'テストシート') }}"フィルターの引数は、順に開始行(先頭行は1)、開始列(先頭は1)、最終行、終了列、シート名(省略可)となりますので、↑の場合は'テストシート'のB3からC4までを読むことになります。
実行してみましょう。
$ ansible-playbook site.yml
[WARNING]: provided hosts list is empty, only localhost is available. Note that the implicit localhost does not match
'all'
PLAY [localhost] *******************************************************************************************************
TASK [show excel data] *************************************************************************************************
ok: [localhost] => {
"msg": [
[
"cat",
"monkey"
],
[
"読めるか",
"な?"
]
]
}こちらも期待通りの動きになりました。
なお、終了行や終了列に0を指定すると、値が存在する最大の行、列の値が自動的に適応されるようにしています。
ヘッダーへの対応
ここまでは、シートの内容を配列に取り込むフィルターを作成してきましたが、もう少し便利にするためにマップとして取り込むフィルターを作ってみます。
まずは、先頭行がヘッダーとして、項目名が並んでいて、2行目以降に実際のデータが並んでいる、よくあるパターンに対応させてみます。
コードは以下のようになり、最初のループで先頭行の内容をheader配列に取り込みます。次のループは2行目から最終行まで、その列の項目名とその値でdictを作成して、それをvalues変数に追加していきます。
def ReadExcelHeader(self, path, *args):
workbook = load_workbook(filename=path, data_only=True)
sheet = workbook[args[0]] if len(args) != 0 else workbook[workbook.sheetnames[0]]
header = []
for c in range(1, sheet.max_column + 1):
header.append(sheet.cell(1,column=c).value)
values = []
for r in range (2, sheet.max_row + 1):
temp = {}
for c in range(1, sheet.max_column + 1):
temp[header[c - 1]] = sheet.cell(row=r,column=c).value
values.append(temp)
return valuesこれを、"read_excel_header"フィルターとして登録し、以下のPlaybookで実行してみます。
---
- hosts: localhost
gather_facts: false
tasks:
- name: show excel data
ansible.builtin.debug:
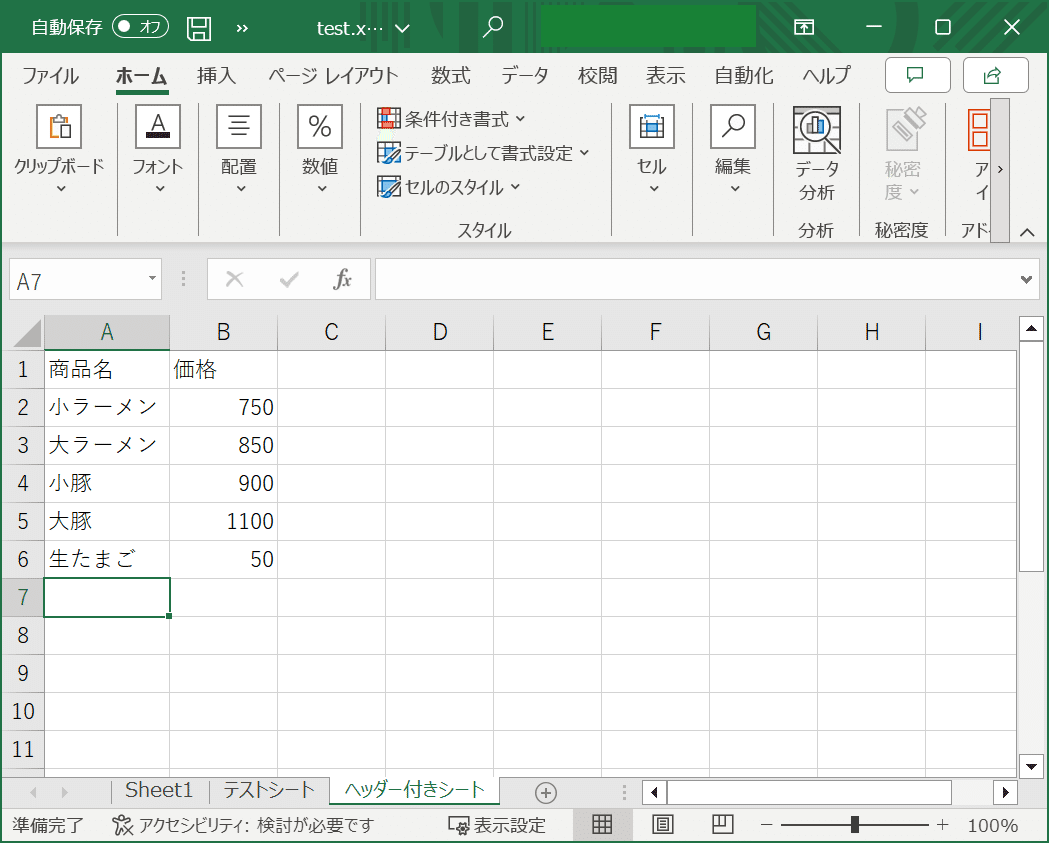
msg: "{{ 'test.xlsx' | test.excel.read_excel_header('ヘッダー付きシート') }}"テストデータはこちらです。
結果は以下のようになりました。
$ ansible-playbook site.yml
[WARNING]: provided hosts list is empty, only localhost is available. Note that the implicit localhost does not match
'all'
PLAY [localhost] *******************************************************************************************************
TASK [show excel data] *************************************************************************************************
ok: [localhost] => {
"msg": [
{
"価格": 750,
"商品名": "小ラーメン"
},
{
"価格": 850,
"商品名": "大ラーメン"
},
{
"価格": 900,
"商品名": "小豚"
},
{
"価格": 1100,
"商品名": "大豚"
},
{
"価格": 50,
"商品名": "生たまご"
}
]
}
PLAY RECAP *************************************************************************************************************
localhost : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0これなら、列が追加されたり、列が入れ替わったとしても値に確実にアクセスできて安心ですね。
今回のExcelフィルターの最終形
あとは、先ほどと同様に範囲指定できるフィルター "read_excel_header_range"として追加して一旦完成とします。
全体的なコードは以下のようになりました。
from openpyxl import *
class FilterModule(object):
def filters(self):
return {
'read_excel': self.ReadExcel,
'read_excel_range': self.ReadExcelRange,
'read_excel_header': self.ReadExcelHeader,
'read_excel_header_range': self.ReadExcelHeaderRange,
}
def ReadExcel(self, path, *args):
workbook = load_workbook(filename=path, data_only=True)
sheet = workbook[args[0]] if len(args) != 0 else workbook[workbook.sheetnames[0]]
values = []
for r in range (1, sheet.max_row + 1):
temp = []
for c in range(1, sheet.max_column + 1):
temp.append(sheet.cell(row=r,column=c).value)
values.append(temp)
return values
def ReadExcelRange(self, path, startrow, startcolumn, endrow, endcolumn, *args):
workbook = load_workbook(filename=path, data_only=True)
sheet = workbook[args[0]] if len(args) != 0 else workbook[workbook.sheetnames[0]]
if endrow == 0:
endrow = sheet.max_row
if endcolumn == 0:
endcolumn = sheet.max_column
values = []
for r in range (startrow, endrow + 1):
temp = []
for c in range(startcolumn, endcolumn + 1):
temp.append(sheet.cell(row=r,column=c).value)
values.append(temp)
return values
def ReadExcelHeader(self, path, *args):
workbook = load_workbook(filename=path, data_only=True)
sheet = workbook[args[0]] if len(args) != 0 else workbook[workbook.sheetnames[0]]
header = []
for c in range(1, sheet.max_column + 1):
header.append(sheet.cell(1,column=c).value)
values = []
for r in range (2, sheet.max_row + 1):
temp = {}
for c in range(1, sheet.max_column + 1):
temp[header[c - 1]] = sheet.cell(row=r,column=c).value
values.append(temp)
return values
def ReadExcelHeaderRange(self, path, startrow, startcolumn, endrow, endcolumn, *args):
workbook = load_workbook(filename=path, data_only=True)
sheet = workbook[args[0]] if len(args) != 0 else workbook[workbook.sheetnames[0]]
if endrow == 0:
endrow = sheet.max_row
if endcolumn == 0:
endcolumn = sheet.max_column
header = []
for c in range(startcolumn, endcolumn + 1):
header.append(sheet.cell(row=startrow,column=c).value)
values = []
for r in range (startrow + 1, endrow + 1):
temp = {}
for c in range(startcolumn, endcolumn + 1):
temp[header[c - 1]] = sheet.cell(row=r,column=c).value
values.append(temp)
return values終わりに
AnsibleからExcelシートを読み込フィルターが、とりあえず作成できましたが、いくつか問題があります。
1つ目は、範囲を指定するには変数を4つ指定する必要があり、順番もわかりにくいことです。startrow=1,startcolumn=1...のように指定するようにもできますが、記述量が多くなってしまいますし、(横に長くなるので)読みにくくなります。
また、先頭行から項目名を取り込むかどうかも変数で指定させることも考えたのですが、これもまた変数が増えることになるので、あえて別のフィルターにしたのですが、これによって同じような動作を行うフィルターの数が4つまで増えてしまいました(これが2つ目の問題)。
自分で使っていても、フィルターで多くの変数を指定することはあまりきれいではないかな、と感じましたので、フィルターではなく「モジュール」としてもう少し使いやすく実装したいな、と思いました。
ということで、次回のブログではモジュールでの実装方法について書いてみようと思います。
(注意)上記コードはあくまで自分で使用するために作成したもので、動作を保証するものではありません。また、エラーチェックはあまり入れておりませんので、もし使用されるのであればその点にもご注意ください。
執筆者プロフィール:水谷 裕一
大手外資系IT企業で15年間テストエンジニアとして、多数のプロジェクトでテストの自動化作業を経験。その後画像処理系ベンチャーを経てSHIFTに入社。
SHIFTグループ会社「RGA」および「システムアイ」に出向し、インフラ構築の自動化やCI/CD、コンテナ関連の業務に従事した後、2024年3月よりSHIFTのインフラサービスGに配属。
LinuxよりWindowsの方が好き。
IaC支援サービスのご紹介
SHIFTではTerraformやCDKを使ったクラウドインフラ構築の自動化や、Ansibleを使ったサーバOSの設定自動化や構成管理のご支援も行っております。ご依頼・ご相談は下記リンクからお願いします。
お問合せはお気軽に
SHIFTについて(コーポレートサイト)
https://www.shiftinc.jp/
SHIFTのサービスについて(サービスサイト)
https://service.shiftinc.jp/
SHIFTの導入事例
https://service.shiftinc.jp/case/
お役立ち資料はこちら
https://service.shiftinc.jp/resources/
SHIFTの採用情報はこちら
PHOTO:UnsplashのBram Van Oost