

VSCodeからローカルDeepSeek R1のDistillモデルを使ってみた

SHIFT ITソリューション部の水谷です。
先週あたりから中国スタートアップ企業が開発した生成AIである "DeepSeek R1" が話題になっていますね。
DeepSeek R1は、学習コストが大幅に低いのに性能は CatGPT o1レベルとされ、コスパがとても高いLLMと言われています。
アカウントを作成すれば無料でチャット機能が使える(API使用は有料)ので、もうすでに試された方も多いのではないでしょうか?
しかし、入力した情報が中国国内のサーバーに保管され、それが別企業にも共有される可能性があることが使用許諾に書かれているため、仕事で使うにはこの点が大きな問題となます。
そこで、本記事では DeepSeek R1 のDistillモデルをローカルPC上で動かすことで情報を外に出さないようにしつつ、VSCodeと連携して使ってみたいと思います。
補足1: 本記事の使用例では、以前作ったAnsibleのコードの改善を試してみますが、もちろんほかの言語で書かれたコードやプロジェクトにももちろん使用できます。
補足2: 今回はGPUに VRAMを12GB搭載したNVIDIAの GeForce RTX 3060を使用しました。GPUの性能によって使用できるモデル、推論にかかる時間は大きく変わります。
LM Studioのインストールと設定
ローカルPC上でLLMを動かすのによく使われている定番ツールとして、LM Studio があります。
無料で使え、とても使い勝手の良く、しかもAPIを提供する機能も持っているツールですので、今回はこれを使用することにします。
LM Studioをインストールは、パッケージをダウンロードして実行するだけですので省略しますが、LM Studioが起動出来たら、さっそくDeekSeek R1のモデルをダウンロードします。
LM Studioの左にある "Discover"(虫眼鏡のアイコン)をクリックし、"DeepSeek"で検索すると……、このように Distill モデルが出てきますね。

2025/1/29 時点ではDeekSeek R1 Distill (Qwen 7B)と、DeepSeek R1 Distill (Llama 8B)が見つかるのですが、今回は Llama の方を使ってみます。私は詳しくないのですが、これはMeta社が開発したオープンソースのLLMモデルであるLlama3 8Bに、DeepSeek R1で生成された推論データを追加学習させた(?)ものということになるでしょうか。
このモデルのパラメーター数は(Llama 8Bなので)8Billion(=80億)ですね。元々のDeepSeek R1はパラメーター数が671Bなので、それに比べたらかなり小さいですが、ローカルPCの1台のGPUで推論させるなら、この程度が良いところでしょう。
難しいことはさて置いて、とりあえず動作確認としてチャットを行ってみます。
左上のチャットアイコンをクリックし、モデルを選択します。

モデルの設定画面が表示されますが、一旦デフォルトで進めます。

で、チャット欄に「Ansibleはどんなツールですか?」と入れてみると……。

回答が返ってきましたが、英語ですね。。。
「日本語で書いてください。」とお願いすると、日本語になりました。

やや言語の面で不安はありますが、回答内容は悪くないし、何よりDeepSeek R1のモデルが動いていることは確認できたので次に進みます。
補足: 2025/1/30の時点ではDeepSeek-R1-Distill-Qwenに日本語の追加学習を行ったモデルも複数公開されていました。これらを使うと、「日本語で書いてください」と書かなくても日本語で表示されました。
DeepSeek R1 DistillをVSCodeから使えるように設定するため、左の上から2番目「Developer」アイコンをクリックします。

ちょっとわかりにくいですが、左上の方に「Status Stopped」と表示されていて、今は外にAPIを提供していない状態のようです。
その「Status Stopped」と書かれているところをクリックすると「Status Running」に変わり、「http://192.168.1.2:1234 」で接続できるよ、と出ています。

とりあえず、これで LM Studio 側の設定は完了です。
VSCodeの設定
VSCodeから使う、と言ってもいろいろやり方はあるのかなと思いますが、今回は Cline エクステンションの1つ、"Roo Code" を使ってみます(選定理由は、使ったことがないので試したかったからw)。
VSCodeのExtensionsで "Roo Code" を検索してインストールします。

すると、VSCodeの左端にロケットのようなアイコンが追加されるので、これをクリックします。
いきなりプロンプトが入力できる状態になっていますが、先に設定が必要です。
"Auto-approve" と表示されているところをクリックすると、Roo Code許可なくできることを指定できます。
ここでは、ファイルやディレクトリへのアクセス、ファイルの編集、それからブラウザの使用を許可しました。

続いて、Roo Codeのペインの右上にある歯車アイコンをクリックして、さらに設定を進めます。

ここにはたくさんの設定項目があるのですが、難しい設定はデフォルトのままにし、どのAIを使うかについて指定します。
"API Provider" に "LM Studio" を選択し、先ほどの LM Studio に表示されていたURLを指定します。
この時 LM Studio に複数のモデルが登録(ダウンロード)されている場合は、そのリストが表示されるので、使いたいモデルを選択します。
タスクを実行してみる
では、試してみましょう。
適当なプロジェクトディレクトリを開いておき、おもむろに以下のように書いてみます。

最初の "@/" は、このプロジェクトのトップディレクトリ以下すべてのファイルをAIに見せる、という意味になります。実行してみると……。

と、エラーが出てしまいました。
エラーメッセージから context length をもっと大きくする必要があるようです。
ということで、LM Studio に戻って、デフォルト4096の context length を適当に約3倍の12000にしてみます。

で、もう一度タスクを実行してみると……。
英語ですが、何か出てきました。
内容を読んでみると、どうやらこのプロジェクトがAnsibleのプロジェクトであることを理解しておらず、(YAML)形式の設定ファイルが多く存在しすぎていて、設定の競合が起きる危険がある、などと出てました。
そこで、「/@ このプロジェクトにあるYAMLファイルはすべてAnsibleのファイルです。このAnsibleプロジェクトの問題点を指摘してください。」としてみます。

すると、Ansibleプロジェクトとしての問題点が表示されるようになりました。
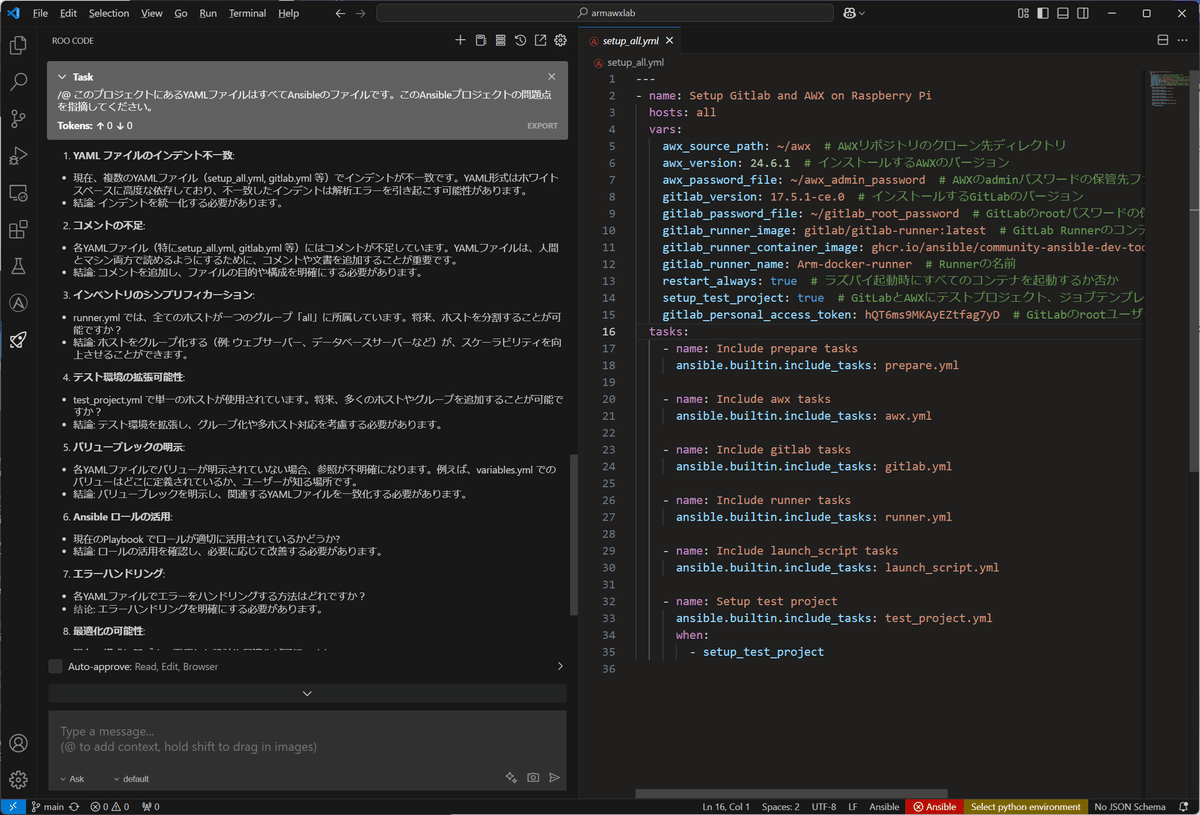
そして、そのまま見ていると、急に日本語になり、以下のようなそれっぽい指摘がでてきました。
1. YAML ファイルのインデント不一致:
・現在、複数のYAMLファイル(setup_all.yml, gitlab.yml 等)でインデントが不一致です。YAML形式はホワイトスペースに高度な依存しており、不一致したインデントは解析エラーを引き起こす可能性があります。
・結論: インデントを統一化する必要があります。
2. コメントの不足:
・各YAMLファイル(特にsetup_all.yml, gitlab.yml 等)にはコメントが不足しています。YAMLファイルは、人間とマシン両方で読めるようにするために、コメントや文書を追加することが重要です。
・結論: コメントを追加し、ファイルの目的や構成を明確にする必要があります。
3. インベントリのシンプリフィカーション:
・runner.yml では、全てのホストが一つのグループ「all」に所属しています。将来、ホストを分割することが可能ですか?
・結論: ホストをグループ化する(例: ウェブサーバー、データベースサーバーなど)が、スケーラビリティを向上させることができます。
4. テスト環境の拡張可能性:
・test_project.yml で単一のホストが使用されています。将来、多くのホストやグループを追加することが可能ですか?
・結論: テスト環境を拡張し、グループ化や多ホスト対応を考慮する必要があります。
5. バリューブレックの明示:
・各YAMLファイルでバリューが明示されていない場合、参照が不明確になります。例えば、variables.yml でのバリューはどこに定義されているか、ユーザーが知る場所です。
・結論: バリューブレックを明示し、関連するYAMLファイルを一致化する必要があります。
6. Ansible ロールの活用:
・現在のPlaybook でロールが適切に活用されているかどうか?
・結論: ロールの活用を確認し、必要に応じて改善する必要があります。
7. エラーハンドリング:
・各YAMLファイルでエラーをハンドリングする方法はどれですか?
・結論: エラーハンドリングを明確にする必要があります。
8. 最適化の可能性:
・現在の構成に基づき、更優れた設計や最適化が可能ですか?
・結論: 最適化の可能性を探り、必要に応じて改善する必要があります。
「確かに!」と思う項目もあるものの、「バリューブレックの明示」ってなんなんだろ? となったり、いろいろですね。
続いて、コードの追加を少し試してみましょう。
タスクの種類を "Ask" から "Code" に切り替えて、「@/prepare.yml このファイルの最後に httpd をインストールするタスクを追加してください。なお、モジュールは ansible.builtin.dnf を使ってください。」としました。

しばらくすると……。

期待通りのタスクが追加されました(右下の黄色い部分)。
しかも、表示された英文を読んでみると、「私はAnsibleではaptモジュールやdnfでパッケージがインストールできることを知っている。このファイルはすでにansible.buitlin.aptモジュールを使っているけど、dnfモジュールを使うという指示がある。おそらくaptモジュールを使うべきだと思うが、(指示通り)dnfにスイッチしよう。」とか独り言のように言っているのが面白い(混乱させてごめん > roo)。
で、「Save」を押せばタスクが追加されたファイルが保存され、「Reject」を押せば破棄されるようです。 なかなか便利ですね。
もう少し複雑でコマンド実行を伴うタスクも試してみたのですが、コマンドの引数を間違えたりして、思うように進みませんでした。このあたりは、(Rooが持っている)プロンプトが良くないのか、Ansible関連のコマンドはあまり学習していないのか、理由はよくわかりません。もう少し使い込んでみる必要がありそうです。
最後に
まだ「少し触ってみた」程度ですが、意外なほどすんなり DeepSeek R1 の Distill モデルを動かせました。
クオリティについては、私には他のモデルと比較する知識がないのでどれほど良いものなのかはわかりませんが、ローカルのGPUだけを使って無料でこれだけできるだけでもすごいことだな、と感じました。
とは言え、タスクを書いて会話していけば開発がどんどん進んでいく、というような世界にはまだ遠いのかな、とも感じましたが、Ansibleではなくもっとメジャー(?)な言語なら違ったかもしれません。
それにしても、時代はどんどん変わってますね。遅れないようについていかないと。。。
✅公式ブロガー水谷の執筆記事一覧
執筆者プロフィール:水谷 裕一
大手外資系IT企業で15年間テストエンジニアとして、多数のプロジェクトでテストの自動化作業を経験。その後画像処理系ベンチャーを経てSHIFTに入社。
SHIFTグループ会社「RGA」および「システムアイ」に出向し、インフラ構築の自動化やCI/CD、コンテナ関連の業務に従事した後、2024年3月よりSHIFTのインフラサービスグループに配属。
LinuxよりWindowsの方が好き。
✅SHIFTへのお問合せはお気軽に
✅SHIFTについて(コーポレートサイト)
✅SHIFTのサービスについて(サービスサイト)
✅SHIFTの導入事例
/
🆓無料DL
\
お役立ち資料はこちら
SHIFTの採用情報はこちら
PHOTO:UnsplashのSteve Johnson