

Pinecone + OpenAIでオリジナル物語のQAボットを作ったら意外とお利口だった

やりたいこと
独自のドメイン情報に対してGoogle検索や全文検索による回答ではなく、質問の意味を理解した回答をするセマンティックなQAボットをつくりたい。
人はそれをコグニティブ・サーチというらしい。
コグニティブ・サーチとは?
「人工知能 (AI) を使用して、さまざまな種類のクエリのために関連性のある正確な検索結果を迅速に見つける検索エンジンテクノロジーです。」
かねてから生成AIの活用はチャットで満足せず、こういうものが実現されるほうが良いと思っていた。
やってみよう、冬休みだし。
オリジナル物語のWikiを参照データにしてみた
小2の息子の寝かしつけの際にときおり、オリジナルの物語をアドリブ創作して聞かせている。
タイトルは「鬼のはなし」で、様々な色の鬼が登場して活躍する冒険奇譚である。
回を重ねるごとに登場人物が多くなり、物語設定がややこしくなってきたので手元でメモを書きためていた。
子供の記憶力を侮るなかれ、設定を誤ると指摘が厳しいのだ。
冬休みということで、今回は自宅PCでこのWikiデータを参照するQAボットを開発してみた。
ワークフローとアーキテクチャ
Wikiデータは10KB程度だが、これを直接生成AIに食わせるのではなくベクトルデータベースを使う。
今回はフルマネージドでサクッと使えそうという理由でPineconeを採用した。
Vector Database for Vector Search | Pinecone
Pineconeは、数十億のベクトルを10msで検索可能なスケーラビリティとパフォーマンスを提供し、本番のアプリケーションにすぐ導入できるインテグレーション性の高さが強みです。マネージドサービスなので、運用や監視のコストも最小限。
テキストのベクトル化はOpenAIのGPTモデルを使って、Pineconeにベクトルデータを格納する。
質問の回答を考えるのもGPTモデルだ。
ワークフロー

ベクトル化は、単語埋め込み(Word Embedding)ともいわれ、超おおざっぱにいうと文章や単語の意味を数値化してデータ化する要素技術だ。
参考: 単語埋め込みとは何ですか?|包括的な単語埋め込みのガイド | Elastic
アーキテクチャ

お試しということでWSL2内dockerでシステムを構成。Pineconeは無償アカウントを作成。OpenAIはGPT Plusアカウント(有償)を用いた。
ボットの回答を得る処理は、Pineconeのexample notebookをまるっと引用させていただき、バックエンドはFastAPIでpython、フロントエンドはVueJSとなった。
本稿、コードは公開しないがバックエンドはほぼ下記noteboookで再現できるので、そちらをご覧いただきたい。
参考: gen-qa-openai.ipynb - Colaboratory

ひどくシンプルなアプリケーションだが、PoCには十分すぎるぐらいだ。
動かしてみる
さっそくQAボットに質問してみよう。
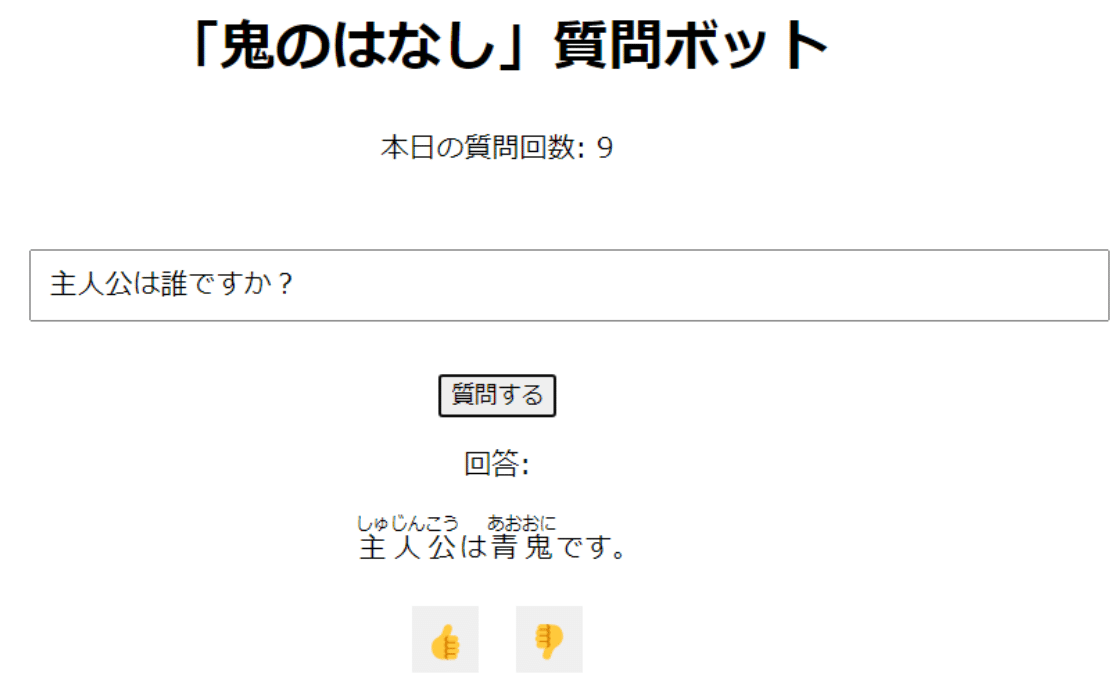
簡単な質問はOK(正解は青鬼)。
少し意味の理解が必要な質問をしてみる。
質問:青鬼の職場は?
回答:青鬼の職場は入間の村で経営する雑貨屋であるWikiには「青鬼が経営する雑貨屋」とあり「職場」という記載が無いにも関わらず、同様の意味で捉えているところが良い感じ。
掘り下げた質問をしてみる。
質問: 鬼のはなしに面白いお店は出てきますか?
回答: はい、たこ焼きボウルが面白いお店です。
質問: たこ焼きボウルとはどんな感じですか?
回答: たこ焼きボウルは、たこ焼きとわんこそばをミックスしたアミューズメント飲食サービスです。
2階のキッチンからレールに乗って熱々のたこ焼きが勢いよく転がってくるので、片っ端から食べなければいけません。
最初は楽しいが、ペースが早いのですぐにお腹いっぱいになってしまいます。
質問: たこ焼きボウルでたこ焼きを停止させるにはどうすれば良い?
回答: 「ぷとっす」と言うことで、たこ焼きを停止させることができます。いずれも見事に正解である。ブラボー。
一方で、うまくいかないパターンもある。
質問: ピンク鬼と青鬼は知り合いですか?
回答: いいえ、知り合いではありません。Wiki上では出会っているのだが、知り合いの概念があいまいで解釈が難しいのかもしれない。
捏造もたまにする。
質問:鬼のはなしの回のタイトルを4つほど、教えていただけますか?
回答:
1.「ぬるぬる小判」
2.「いざ鬼ランドへ(前後編)」
3.「カバンはどこだ!レインボー鬼ふたたび」
4.「鬼のおどり!おばけのおどり!」「鬼のおどり!おばけのおどり!」というお話の回は存在しない。面白そうではあるが。
promptを覗いてみる
promptを覗いてみると、とてもシンプルだった。
Answer the question based on the context below.
Question: 青鬼の職場は?
Context:
青鬼は青鬼とおにぎり工場に行ったことがある。
おにぎり工場にいくと、試食室があった、部屋に入ると服を脱いだり、体に塩を塗ったりと色々な指示をされる。おにぎり工場は実は、鬼を食べてしまう、鬼切りの工場だった。
青鬼と赤鬼はなんとか逃げることができた。
---
赤鬼は青鬼が経営する雑貨屋で働いていて、昔は焼肉屋を経営していた。
火を自由に操ることができる。焼肉屋さんでは特殊能力でコンロに日をつけていて、お客さんを喜ばせていた。
赤鬼は青鬼の冒険の相棒である。青鬼の性格と能力をよく知っている。
...
---
青鬼は物語の主人公である。入間の村で雑貨屋さんを経営している。
その昔は川で渡し船を営んでいた。青鬼はどんな洋服でもイメージするだけでつくることができる特殊能力を持っている。
...Contextはpineconeからのベクトル比較した類似検索の結果ランクで、Wikiデータから3つ取ってきていて、これと質問テキストからGPTが考えて回答を導き出している。
現状ベクトルデータは単一だが、たとえば「タイトル」と「説明」のように構造化して、promptでその優先度を認識させて回答してもらえば、さらに精度が向上しそうだ。
精度向上を考える
たまに勝手な回答をするのは、足りない情報を補完しようする生成AIの性質によるものだろう。
ハルシネーションというらしい。
ハルシネーション(Hallucination)は、もっともらしいウソ(=事実とは異なる内容や、文脈と無関係な内容)の出力が生成されること
主な原因はWikiに適切な説明情報が足りていないからだ。
解決して回答精度を上げたい。
問題はどの項目にどう情報が足りないのかわからないことだ。わかれば補足説明を追記すればよいだけ。なので、まず回答の良し悪しを知る必要がある。
回答がNGのものを集めればよいので、QAログ機能といいね機能を実装して、データを集めてみることにした。

WEBアプリを家のLANに公開して息子君のiPadからもアクセスできるようにしておき、1日の質問ノルマを伝えて、「いいね!」を頑張ってもらうことにした。
ログを定期的に棚卸してWikiを修正すれば精度向上するだろう。
一安心である。
ベストプラクティスを想像してみた
GPTにベクトルデータベースの最適化について相談してみた。
事前にできること
適切な埋め込みモデルの選択(言語、モデル)
データの前処理の最適化(クレンジング、正規化)
ベクトルデータベースの最適化(メトリックやインデックスタイプ、次元数)
運用で改善すること
クエリの調整とランキング結果の修正ロジック検討
連続的な評価と調整
幾つか、ベクトルデータベース特有のものもあるが、概ねAI/MLの既視感あるプラクティスだ。
とはいえ実現させるにはそれなりのMLOpsな体制を整えないといけないだろう、PoC中の筆者には少々お腹いっぱい「ぷとっす」である。
所感
ベクトルデータベースもフルマネージドで手早く作成できることが驚きだった。Elasticsearch等でも同様のことはできると思うが、手数の多さと類似性検索の精度維持には学習コストがかかりそうだ。
AI/ML系の動作検証はgoogle colab/Jupyter notebookが作業効率化に大きく寄与してくれた。
コーディングはNo Google, But GPTだった。GPTの力添え無しでは終わらなかっただろう。
企業で導入するには、エンタープライズでも利用可能なベクトルサーチの選定と運用ルールの選定、データの正規化ワークロードなど、データ利用とデータ送信のガバナンスなどなど、ハードルは高いがプラットフォーム化ができれば汎用性の高い社内サービスになりそうである。
ネクストアクションとしては「鬼のはなし」本編を書いて、その原稿をベクトルデータベースに取り込んで、お話を要約したり、設定考証を考えてくれるボットを作りたい。(たぶんやらないが)
執筆者プロフィール:森川 知雄
中堅SIerでテスト管理と業務ツール、テスト自動化ツール開発を10数年経験。
SHIFTでは、GUIテストの自動化ツールRacine(ラシーヌ)の開発を担当。
GUIテストに限らず、なんでも自動化することを好むが、ルンバが掃除しているところを眺めるのは好まないタイプ。
さまざま案件で自動化、効率化によるお客様への価値創出を日々模索している。2021年からは技術イベントSHIFT EVOLVEの運営を主担当。2023年からはテスト管理ツールCATを始めとしたプロダクトのマネージメントを担当
お問合せはお気軽に
SHIFTについて(コーポレートサイト)
https://www.shiftinc.jp/
SHIFTのサービスについて(サービスサイト)
https://service.shiftinc.jp/
SHIFTの導入事例
https://service.shiftinc.jp/case/
お役立ち資料はこちら
https://service.shiftinc.jp/resources/
SHIFTの採用情報はこちら