

【Node.js】Prisma(ORM)を使ってDBマイグレーションをやってみた

はじめに
こんにちは、SHIFTの開発部門に所属している Katayama です。
以前、ORM として Sequelize を利用していたが、近ごろ Prisma をよく聞くな~と思い、今回は Prisma を使って DB マイグレーションを行ってみた。
Prismaはアプリケーションの開発者がデータベースを扱う際の生産性を向上させることを目的にして作成されたライブラリで、具体的には以下のような特徴がある(Why Prisma?も参照)。
リレーショナルデータをマッピングするのではなく、オブジェクトで考える
複雑なモデルオブジェクトを避けるために、クラスではなくクエリを使う
よくある落とし穴やアンチパターンを防ぐ健全な制約がある
コンパイル時に検証可能なタイプセーフデータベースクエリである
定型文が少なく、開発者はアプリの重要な部分の開発に集中できる
コード・エディターで自動補完されるため、ドキュメントを調べる必要がない
※今回は RDB(MySQL)を対象にマイグレーションを試してみる。
※ちなみに、Sequelize で同じような事をやってみた事があったが、そちらについてはSequelize を使って DB マイグレーションをやる方法 2 つを試してみたを参照。また、Sequelize?Prisma?という比較についてはSequelize vs Prismaを参照。また、既存のデータベースツールとの比較は、Problems with SQL, ORMs and other database toolsを参照。
マイグレーション実施までの事前準備
Prisma を利用できるようにする
今回は既存のプロジェクトに Prisma を追加していく場合でやっていく。
既存のプロジェクトに追加する手順はGet started / Set up Prisma / Add to existing project / Relational databasesに記載がある。
まずは、prismaを依存に追加する。
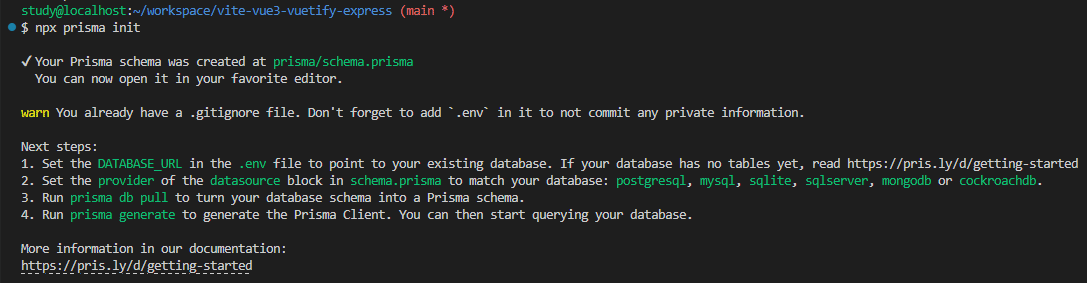
$ yarn add -D prisma続いて、"npx prisma init"コマンドで Prisma の初期化を行う。
初期化を行うち以下のように続きの手順が表示され、プロジェクトのルートに"./prisma/schema.prisma"と"./env"が作成される。
$ tree -I node_modules
.
├── .env
...
├── package.json
├── prisma
│ └── schema.prisma
...
└── yarn.lock以上で一番最初の準備は終了になるが、VS Code で開発するのであればPrisma の Extensionsも追加するといいだろう。
※今回、MySQL のサーバーは docker-compose で起動する。
docker-compose で MySQL を立ち上げる手順についてはCentOS で MySQL を動かせるようにするまで ~docker docker-compose~といった記事を参照。
ちなみに、今回はローカルなのでパスワードなしとして、以下のように設定した。
docker-compose.yamlversion: '3.9'
services:
mysql:
image: mysql:8.0.32
container_name: mysql
environment:
MYSQL_ROOT_PASSWORD: ''
MYSQL_ALLOW_EMPTY_PASSWORD: 'yes'
TZ: 'Asia/Tokyo'
ports:
- 3306:3306
volumes:
- ./data/mysql:/var/lib/mysql
- ./mysql/sql:/docker-entrypoint-initdb.d
- ./mysql/my.cnf:/etc/mysql/conf.d/my.cnf# mysql/my.cnf
[mysqld]
general_log = ON
general_log_file = /var/lib/mysql/general.log
[client]
default-character-set = utf8mb4DB への接続情報を設定する
続いて、Get started / Set up Prisma / Add to existing project / Relational databases / Connect your databaseに書かれているように、MySQL サーバーに接続するように Prisma の設定を変更していく。
初期の"prisma/schema.prisma"は以下のようになっている。
// prisma/schema.prisma
generator client {
provider = "prisma-client-js"
}
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}# .env
DATABASE_URL="postgresql://johndoe:randompassword@localhost:5432/mydb?schema=public"上記の変更すべき部分は以下の 2 つになる。
①datasource db の provider ②.env の DATABASE_URL
変更後の設定は以下の通り。
MySQL を利用するので provider には mysql を設定する。
.env の DATABASE_URL にはConcepts / Database connectors / MySQLに書かれているフォーマットに沿って DB の接続先を定義する。
// prisma/schema.prisma
...
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}# .env
DATABASE_URL="postgresql://johndoe:randompassword@localhost:5432/mydb?schema=public"ここまででマイグレーションを行うための事前準備は以上になる。
続いて実際にマイグレーションを実行していきたいと思うが、2 つのケースでマイグレーションをやってみたいと思う。
① 何もテーブルが存在しない状態から、新規にデータベースの構築を行うパターン
② 既にデータベースが存在し、初期状態のモデルを先に生成してから、テーブルを追加するなどのマイグレーションを行うパターン
マイグレーションをやってみる
① 何もテーブルが存在しない状態から、新規にデータベースの構築を行うパターン
まず作成したいテーブルのモデルを定義する。今回はシンプルに user と post(投稿)のテーブルを作成する事にした。
...
datasource db {
provider = "mysql"
url = env("DATABASE_URL")
}
model User {
id Int @id @default(autoincrement())
name String
posts Post[]
}
model Post {
id Int @id @default(autoincrement())
title String
published Boolean @default(true)
authorId Int
author User @relation(fields: [authorId], references: [id])
}あとは、以下のように"npx prisma migrate dev --name init"コマンドを実行すればいい(以下の画像の中で@prisma/client が依存に追加されているが、これは"--skip-generate"オプションを付けずに prisma migrate dev を実行したため同時に Prisma Client も追加されたものになる)。
また、データベースがない場合には、データベースの作成から Prisma が行ってくれる。

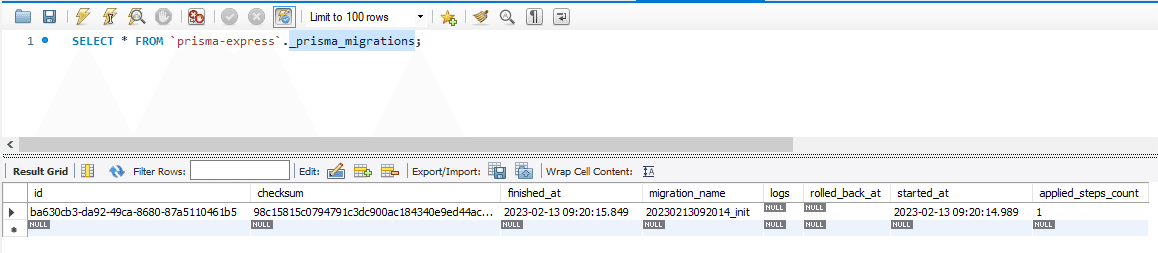
上記のコマンドを実行すると、"./prisma/migrations"が作成され、マイグレーションが管理されるようになる。
マイグレーションの管理は DB の"_prisma_migrations"テーブルで行われ、そこに以下のように実行したマイグレーションの記録が格納されている。
続いてモデルの変更を行い、それを適用してみようと思う。User モデルに jobTitle を追加してみる。
model User {
id Int @id @default(autoincrement())
name String
jobTitle String // ← 追加
posts Post[]
}
...この変更を適用するには、以下のように"npx prisma migrate dev --name added_job_title"コマンドを実行すればいい。
--name オプションなど指定できるオプションについては公式を参照。

上記の操作でマイグレーションが実行され、テーブルの定義も変更されている事が確認できるだろう。
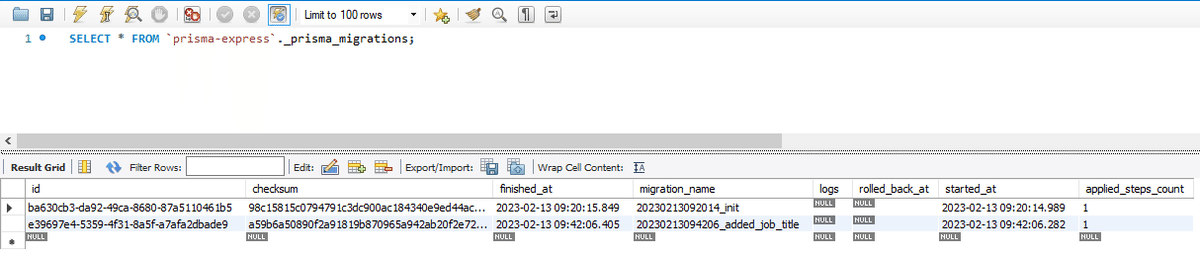
ちなみに、マイグレーションの記録を参照すると、以下のように 1 行増えている事も確認できる。
続いて、既にデータベースが存在し、初期の状態のモデルを先に生成しつつそのマイグレーションも作成後、モデルの変更を行い、DB にそれを反映(マイグレーション)するという事をやってみたいと思う。
② 既にデータベースが存在し、初期状態のモデルを先に生成してから、テーブルを追加するなどのマイグレーションを行うパターン
まず、既にデータベースがある状態での検証になるので、データベースとテーブルを 2 つ作成しておく。
CREATE DATABASE `prisma-express`;
USE `prisma-express`;
CREATE TABLE `User` (
`id` INTEGER NOT NULL AUTO_INCREMENT,
`name` VARCHAR(191) NOT NULL,
PRIMARY KEY (`id`)
) DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
CREATE TABLE `Post` (
`id` INTEGER NOT NULL AUTO_INCREMENT,
`title` VARCHAR(191) NOT NULL,
`published` BOOLEAN NOT NULL DEFAULT true,
`authorId` INTEGER NOT NULL,
PRIMARY KEY (`id`)
) DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
ALTER TABLE `Post` ADD CONSTRAINT `Post_authorId_fkey` FOREIGN KEY (`authorId`) REFERENCES `User`(`id`) ON DELETE RESTRICT ON UPDATE CASCADE;次に、既に作成されているテーブルの定義を Prisma のモデルに落とし込む必要があるが、それは以下のように"npx prisma db pull"コマンドでできる。
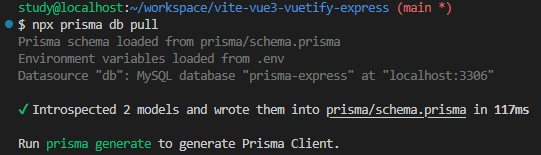
prisma db pull を行うと、以下の図のように Prisma CLI が"prisma/schema.prisma"を自動で作成するという動きになる。

実際に自動で作成されたモデルは以下のようになっていた。
...
datasource db {
provider = "mysql"
url = env("DATABASE_URL")
}
model Post {
id Int @id @default(autoincrement())
title String
published Boolean @default(true)
authorId Int
User User @relation(fields: [authorId], references: [id])
@@index([authorId], map: "Post_authorId_fkey")
}
model User {
id Int @id @default(autoincrement())
name String
Post Post[]
}続いて、既に存在していたデータベースの状態を初期状態としてマイグレーションに登録する、という事を行う。
この手順が抜けると、既存のデータベースの状態を構築するマイグレーションがない状態になり、テーブルの変更・追加といったマイグレーションも作成できない。
まず、初期のマイグレーションを作成するためのフォルダを手動で作成する。
$ mkdir -p prisma/migrations/0_init続いて、以下のようなコマンドを実行し、マイグレーション用の SQL を生成する。
コマンドを実行すると、"prisma/migrations/0_init"以下に migration.sql というファイルが作成され、その中身は画像のようになっている。
$ npx prisma migrate diff --from-empty --to-schema-datamodel prisma/schema.prisma --script > prisma/migrations/0_init/migration.sql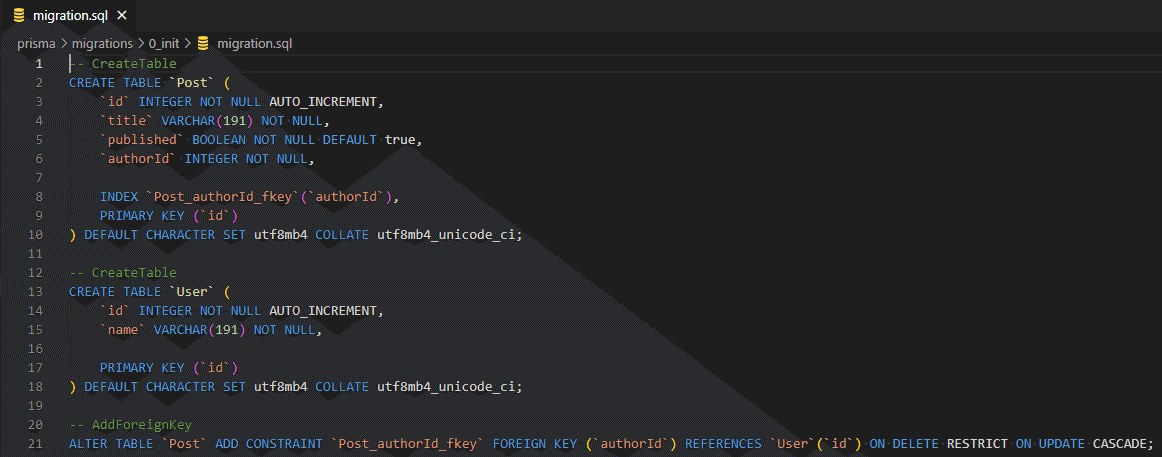
少し migrate diff コマンドに関して補足をする
(全てのオプションや詳細についてはmigrate diffを参照)。
--from-empty
migrate diff コマンドの基本的な使い方としては、"prisma migrate diff --from-... --to-... "のように、source1 の状態を source2 の状態にするための移行時の差分を出力させるという使い方になる。
今回は既に存在しているデータベースの状態が source2 にあたる。
source1 にあたるものは何もなく、そういった時には、--from-empty を指定して、移行元のデータモデルが空であると仮定させる。
--to-schema-datamodel
上記の source2(移行先の状態)を指定する必要があるが、その状態を prisma のスキーマファイルの定義の状態とするためのオプション。
ファイルのパスをオプションに続けて記載する。
※今回は Prisma ファイルにしたが、データベースが存在するので、--to-url "$DATABASE_URL"としても同じ結果が得られる(DATABASE_URL は Linux の環境変数として定義さている前提(export DATABASE_URL=mysql://root:@localhost:3306/prisma-express))。
--script
デフォルトでは migrate diff コマンドの実行結果は以下のように人間が読める要約として出力されるが、この出力を要約ではなく SQL のスクリプトにするオプション。
$ npx prisma migrate diff --from-empty --to-schema-datamodel prisma/schema.prisma
[+] Added tables
- Post
- User
[*] Changed the `Post` table
[+] Added foreign key on columns (authorId)ここまで初期のマイグレーションファイルの作成はできた。
ただ、マイグレーションの履歴として初期のマイグレーションが登録されていないと、マイグレーションを実行しようとした時に既に適用済みでエラーになる。
そこで、手動でマイグレーションの履歴を作成し、適用済みであるという事を記録するようにする。
方法は以下のようなコマンドで applied を設定するだけ。
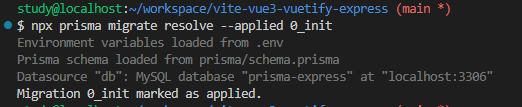
この操作をする事で、データベースには以下のようにマイグレーションの履歴が作成される。これでモデルに修正を行い、それをデータベースに反映するマイグレーションを行う準備が整った事になる。

試しに、以下のように User モデルに jobTitle を追加した後、"npx prisma migrate dev --name added_job_title"コマンドを実行すると、マイグレーション用のファイルが作成され、データベースには変更が反映されている事が確認できる。

※上記 ② の検証は、① で作成された migrations とデータベースを初期化してから行っている。
まとめとして
今回は Node.js の ORM ライブラリ、Prisma でデータベースのマイグレーションを試してみた。
Sequelize でも同じような事はできるが、Sequelize ではモデルを定義してコマンドでマイグレーションではなく、自分でマイグレーションのスケルトンからマイグレーションを実装しなければならず、手間が多かったように思える(Sequelize を使って DB マイグレーションをやる方法 2 つを試してみたを参照)。一方、Prisma の方はモデル定義をして CLI でマイグレーションを実行して差分の SQL も出力されるので簡単にマイグレーションの管理ができそうだなと思った。
次回は Prisma の Cliet で User の簡単な CRUD をする REST API を実装してみるというのをやってみたいと思う。
※ちなみに、モデル → テーブルにマイグレーションというのが一般的な ORM の流れだが、痒い所に手が届かないという理由で、逆(テーブル → モデルを作成)も行われる事があると思う。
この場合、Sequelize ではsequelize-autoという別のライブラリを利用する必要があったが、Prisma の場合には"prisma db pull"というコマンドで簡単にそれができるので、そこもいいなと思った。
《この公式ブロガーの記事一覧》
執筆者プロフィール:Katayama Yuta
認証認可(SHIFTアカウント)や課金決済のプラットフォーム開発に従事。リードエンジニア。
経歴としては、SaaS ERPパッケージベンダーにて開発を2年経験。
SHIFTでは、GUIテストの自動化やUnitテストの実装などテスト関係の案件に従事したり、DevOpsの一環でCICD導入支援をする案件にも従事。その後現在のプラットフォーム開発に参画。
お問合せはお気軽に
https://service.shiftinc.jp/contact/
SHIFTについて(コーポレートサイト)
https://www.shiftinc.jp/
SHIFTのサービスについて(サービスサイト)
https://service.shiftinc.jp/
SHIFTの導入事例
https://service.shiftinc.jp/case/
お役立ち資料はこちら
https://service.shiftinc.jp/resources/
SHIFTの採用情報はこちら
https://recruit.shiftinc.jp/career/