

CentOS上のProFTPD移行でC言語のlong型にハマった話

SHIFTからグループ会社の1つであるリアルグローブ・オートメーティッド(RGA)に出向中の水谷です。
以前RGAのエンジニアが書いた技術情報を「IT自動化ブログ」という名前でこの「SHIFT Group 技術ブログ」内で発信させていただいておりました。RGAが得意とするIT自動化をテーマにし、AnsibleやOpenshift関連の技術に関連したかなり濃い内容の記事を投稿させていただいていたのですが、書く方も読む方も大変wという事情もありまして、ここ半年ほどはお休みさせていただいておりました。
その間もRGAのエンジニアは日々新しい技術を学んだり、豊富な知識を元にお客様の問題を解決したりしており、その技術情報が社内に溜まってきました。そこで、以前に比べれば少しライトに、最近RGAのエンジニアが遭遇した問題や、調査を行った技術などを発信していく形でブログを再開していこうと思います。もしご興味を持っていただけたなら、是非こちらのマガジンをフォローしていただけると幸いです。
再開一発目の今回は、わたくし水谷が最近対応した案件で、ちょっと面白いトラブルシューティングがあったので軽く紹介します。
――――――――――――――――――――――――――――――――――
いきなりですが
問題です。
- C言語のlong型って何bit幅の型でしょうか?
答えは後ほど。
ProFTPDにおけるユーザー認証
私がサポートとして入らせていただいたある案件では、かなり前にCentOS 5上に建てたProFTPDというOSSのFTPサーバーを、CentOS 7+最新版のProFTPに移行する、という作業を行っていました。
ProFTPDはユーザー認証方法が複数あり、MySQLやPostgreSQLを使うもの、LDAPなどを使うもの、テキストファイルにユーザー情報を書いてそれを使うもの(パスワードは生ではなくハッシュが入っている)、それからCDBファイルと呼ばれるユーザー情報が入ったバイナリファイルを使うもの、などがあります(ありました)。
案件の情報を見ると、現行サーバーがCDBファイルを使った認証で運用されていることがわかりました。
CDBファイルとは
CDBファイルのCDBは、Constant DataBaseの略で、Key-Value型のDBを構成します。特徴は、与えたKeyに対して、素早くValueを返すことができるが、レコードの追加や削除時には、ファイル全体を作り直す必要がある、というちょっと変わった(?)DBです。
マイナーなファイル形式のためか、CDBファイルを読むための公式ライブラリはないので、基本的に自分で1から実装する必要があったりして、今この形式のファイルが使われるケースはほとんどないと思われます。
ProFTPDでのCDBの扱い
ProFTPDでは、数年前のバージョンでは、このCDBファイルがデフォルトで使用可能な状態だったようですが、最近のバージョンではオプション扱いとなっており、これを使用するには別途C言語で書かれたコードをダウンロードし、これをProFTPDのソースコードに含めてビルドしなおす必要があります。
遭遇した問題
顧客の要望は、ユーザー認証はCDBファイルで行うことを継承することでした。CDBファイル以外の認証方法に移行するには、全ユーザーの再登録、および全ユーザーに対してパスワード変更の依頼、などを行う必要があるので、そのコストを考えるとこの要望には理にかなったものと言えます。
で、実際にCentOS 7上でC言語のコードを組み込んでビルドしてみたのですが、ビルドは成功したものの実際ProFTPDを動かしてみると、CDBファイルはちゃんとオープンできているのにユーザー認証に失敗します。ログのメッセージによると、ユーザー名がCDBファイル内に見つからない、というものでした。
ということで、ソースコードを調べることになりました。
見つかった意外な問題
ソースコードはそれほど複雑ではないのですが、なかなか問題が見つかりません。コードの中で問題が起きていると考えられるCDB内の検索の部分は、与えられたKeyのハッシュを計算し、CDB内に書かれているハッシュ値と比較しています。ロジック的にも問題なさそうだし、実際このコードで動いていたはずなのです。
ぼーっとコードを眺めていると、ハッシュの比較元と比較先の変数の型がlong型(正確には unsigned longですが、簡単のためlongとします)になっていることに気づきました。何か理由がなければ型なんかに目が行くこともないのですが、結論としてはふと目についたこの型に問題がありました。
C言語のlong型というのは long int型の省略形で、その名の通りintより大きい整数を扱うための型(逆はshort = short int)ですね。
このように整数型にも複数の型があることは良いのですが、問題はC言語自体はintやlong intが何bitであるかは規定していないことです。
C言語はCPUが16bitだったころからあり、今はご存じのように64bit CPUが主流になっています。元々C言語は(OSを記述するための言語であったこともあり)高速でコンパクトなバイナリを生成することを目的としていました。このためには、CPUのレジスタ幅にマッチした値が扱える型がある方が有利なため、CPUに合わせてビット幅を定義してよいことにしているのです。つまり、例えばintを(CPUの)汎用レジスタと同じ幅にしてしまえば、この型を使い続けている間は、レジスタ間演算に置き換えられる(高速なコードが生成される)ことが想像できますので それを意識しながら効率の良いコードを生成することが可能になります。
ちょっと横道にそれましたが、要するにlongが何bit幅なのかも、コンパイラごとに違う可能性があるのです。
表にまとめるとこうなります。
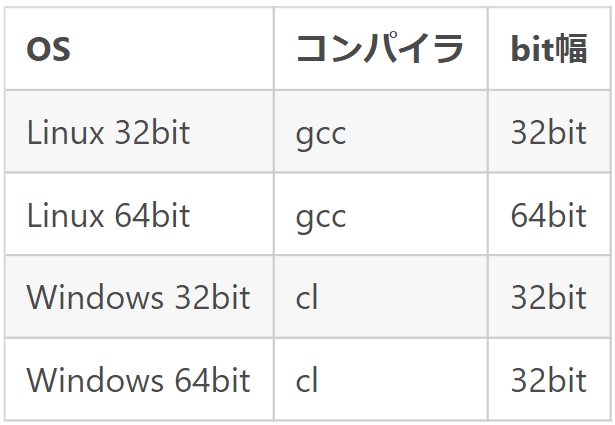
ということで、実際にLinuxでは32bit OSと64bit OSではlong型のビット数が異なっているのです。
もうお気づきかと思いますが、今回の問題はハッシュの計算をlong型の変数上で行っており、32bit OS上と64bit OS上では計算結果が異なるようなコードになっていました。このため、事前に32bitコードで計算されてCDBファイルに書かれていたハッシュ値と、64bit OS上で計算したハッシュ値がマッチせず、結果としてユーザー名が見つからない、という問題につながっていたのです。
解決方法
この問題の解決方法は、long型ではなく32bitの型を使って変数を定義してしまえばよいわけです。で、これの一番簡単なものがintですね。やや余談ですが、Windowsでもintは32bitです(32bit Windows、64bit Windows共に)。
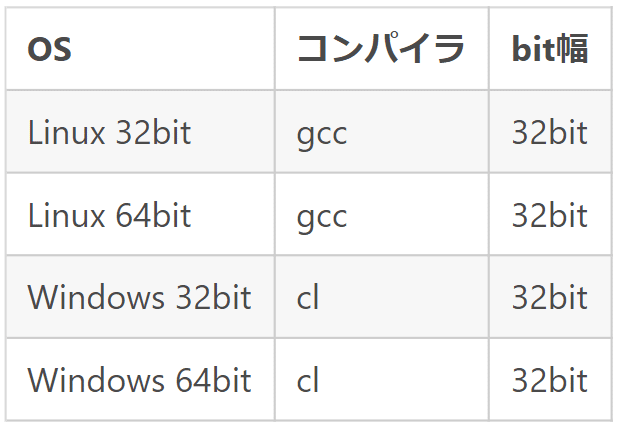
なんとも面倒ですが、クロスプラットフォームなネイティブアプリを作成するときはこのあたりは細心の注意が必要です。
……と書きましたが、注意しなくてもよい方法もありまして、下のような型を使ってしまうのが手っ取り早いですね(C99で定義)。

――――――――――――――――――――――――――――――――――
執筆者プロフィール:水谷 裕一
大手外資系IT企業で15年間テストエンジニアとして、多数のプロジェクトでテストの自動化作業を経験。その後画像処理系ベンチャーを経てSHIFTに自動化エンジニアとして入社。
SHIFTでは、テストの自動化案件を2件こなした後、株式会社リアルグローブ・オートメーティッド(RGA)に出向中。RGAでは副社長という立場でありながら、エンジニアとしてAnsibleやOpenshiftに関する案件も担当。また、Ansibleの社内教育や、外部セミナー講師も行っている。
最近の趣味は電動キックボードでの散歩。
【ご案内】
ITシステム開発やITインフラ運用の効率化、高速化、品質向上、その他、情シス部門の働き方改革など、IT自動化導入がもたらすメリットは様々ございます。
IT業務の自動化にご興味・ご関心ございましたら、まずは一度、IT自動化の専門家リアルグローブ・オートメーティッド(RGA)にご相談ください!
お問合せは以下の窓口までお願いいたします。
【お問い合わせ窓口】
代表窓口:info@rg-automated.jp
URL: https://rg-automated.jp
