

LangChainのプロンプト最適化ライブラリ「Promptim」を試してみる

はじめに
SHIFTの武藤です。
この記事では、LangChainから発表された「Promptim」というプロンプト最適化ライブラリを試した結果をご紹介します。
最近はLLMを使う場面が増えてきましたが、適切なプロンプトを与えることの重要性と難しさを日々感じています。その最適化を自動化できるのが、このPromptimというライブラリです。
Promptimの概要
LangChainが開発し、2024年11月に発表されたプロンプト最適化ライブラリです。
初期プロンプト、データセット、カスタム評価基準をインプットに、最適化ループを実行して元のプロンプトを上回る精度のプロンプトを生成します。実行にはLangSmithのアカウントが必要ですが、その分様々なリソースをLangSmithで管理して効率よく最適化を行えます。
類似のツール・サービスとしてはスタンフォードNLPのDspyやGoogleのVertex AI Prompt Optimizerなどがあります。
Quick StartでPromptimを理解する
まずは公式のQuick Startに沿ってPromptimを試してみます。
インストールと初期設定
Python仮想環境を作成し、promptimをインストールします。
python -m venv .venv
source .venv/bin/activate
pip install -U promptim続いて、APIキーを環境変数として設定します。今回はgpt-4o-miniを使用するためOPENAI_API_KEYを登録します。
export LANGSMITH_API_KEY=<LangSmithのAPIキー>
export OPENAI_API_KEY=<OpenAIのAPIキー>さらに、最適化プロセスを可視化するため、LangSmithにトレースを記録する設定も行います。
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_ENDPOINT="https://api.smith.langchain.com"タスクの作成
次のコマンドでタスクを作成します。
promptim create task ./my-tweet-task \
--name my-tweet-task \
--prompt langchain-ai/tweet-generator-example-with-nothing:starter \
--dataset https://smith.langchain.com/public/6ed521df-c0d8-42b7-a0db-48dd73a0c680/d \
--description "Write informative tweets on any subject." \
-yこれで./my-tweet-taskディレクトリにファイルが作成され、LangSmithには以下のリソースが追加されます。
初期のプロンプト
ユーザー入力に応じたツイート文章を生成するプロンプト
訓練用のデータセット
ツイートのテーマ


タスクの更新
Quick Startに従い、プロンプトの出力に対する評価を行う./my-tweet-task/task.pyを更新します。
def example_evaluator(run: Run, example: Example) -> dict:
"""An example evaluator. Larger numbers are better."""
predicted: AIMessage = run.outputs["output"]
result = str(predicted.content)
score = int("#" not in result)
return {
"key": "tweet_omits_hashtags",
"score": score,
"comment": "Pass: tweet omits hashtags" if score == 1 else "Fail: omit all hashtags from generated tweets",
}また、生成されたコードはそのままだとAnthropicのモデルが選択されているため、./my-tweet-task/config.jsonを更新します。
"optimizer": {
"model": {
"model": "gpt-4o-mini",
"max_tokens": 8192
}
},実行
それでは、以下のコマンドで最適化を実行します。
promptim train --task ./my-tweet-task/config.jsonトレーニングが完了すると、LangSmith上のプロンプトが更新されています。

トレーニングの仕組み
トレーニングでは以下プロセスが行われています。
現在のプロンプトとデータセットで生成されたテキストを評価し、スコアとコメントを出力
現在のプロンプトと結果を改善用のプロンプトに渡し、より高スコアを得られるようにプロンプトを最適化
改良されたプロンプトを用いて再び生成した結果が、前回のスコアを上回った場合にのみ、そのプロンプトを採用
上記プロセスを複数エポック(指定された回数の繰り返し)実行
Quick Startのシナリオでは、まず「ツイート用の文章を生成する」元のプロンプトから始まり、その出力に#が含まれる場合に低スコアと改善コメントが与えられることで、ハッシュタグが無いツイート文章が生まれるようにプロンプトが改善されていきます。
このように評価ロジックが非常に重要となりますが、サンプルのようなシンプルなロジックで充足することはまずないはずです。もっと複雑なケースでの作り方が知りたい場合は、LangSmithのEvaluation how-to guidesを参考にしてみてください。
また、LangSmithのトレースを確認すると、プロンプトの改善がどのように行われたか確認できます。
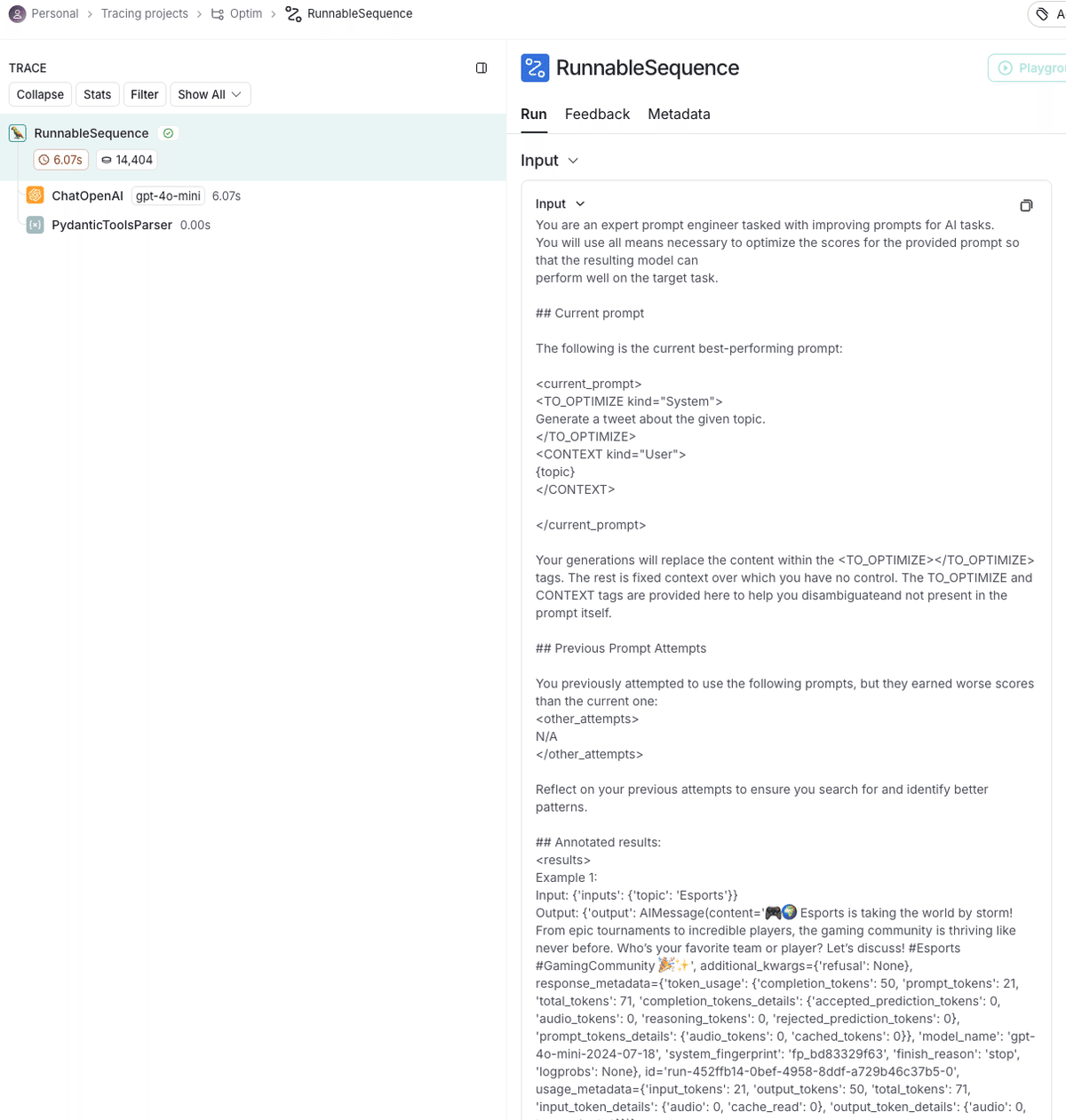
You are an expert prompt engineer tasked with improving prompts for AI tasks.
You will use all means necessary to optimize the scores for the provided prompt so that the resulting model can
perform well on the target task.
## Current prompt
The following is the current best-performing prompt:
<current_prompt>
<TO_OPTIMIZE kind="System">
Generate a tweet about the given topic.
</TO_OPTIMIZE>
<CONTEXT kind="User">
{topic}
</CONTEXT>
</current_prompt>
Your generations will replace the content within the <TO_OPTIMIZE></TO_OPTIMIZE> tags. The rest is fixed context over which you have no control. The TO_OPTIMIZE and CONTEXT tags are provided here to help you disambiguateand not present in the prompt itself.
## Previous Prompt Attempts
You previously attempted to use the following prompts, but they earned worse scores than the current one:
<other_attempts>
N/A
</other_attempts>
Reflect on your previous attempts to ensure you search for and identify better patterns.
## Annotated results:
<results>
Example 1:
Input: {'inputs': {'topic': 'Esports'}}
Output: {'output': AIMessage(content='🎮🌍 Esports is taking the world by storm! From epic tournaments to incredible players, the gaming community is thriving like never before. Who’s your favorite team or player? Let’s discuss! #Esports #GamingCommunity 🎉✨', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 50, 'prompt_tokens': 21, 'total_tokens': 71, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_bd83329f63', 'finish_reason': 'stop', 'logprobs': None}, id='run-452ffb14-0bef-4958-8ddf-a729b46c37b5-0', usage_metadata={'input_tokens': 21, 'output_tokens': 50, 'total_tokens': 71, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})}
Evaluations:
- tweet_omits_hashtags: 0
Comment: Fail: omit all hashtags from generated tweets
Example 2:
...
</results>
## Task description:
<task_description>
Write informative tweets on any subject.
Description of scores:
- my_example_criterion: CHANGEME: This is a description of what the example criterion is testing. It is provided to the metaprompt to improve how it responds to different results.
</task_description>
Unless otherwise specified, higher scores are better (try to maximize scores). Aim for perfect scores across all examples.
In your head, search through all edits, planning the optimization step-by-step:
1. Analyze the current results and where they fall short
2. Identify patterns in successful vs unsuccessful cases
3. Propose specific improvements to address the shortcomings
4. Generate an improved prompt that maintains all required formatting
The improved prompt must:
- Keep all original input variables
- Maintain any special formatting or delimiters
- Focus on improving the specified metrics
- Be clear and concise.
- Avoid repeating mistakes.
Use prompting strategies as appropriate for the task. For logic and math, consider encourage more chain-of-thought reasoning,
or include reasoning trajectories to induce better performance. For creative tasks, consider adding style guidelines.
Or consider including exemplars.
Output your response in this format:
<analysis>
Your step-by-step analysis here...
</analysis>
<improved_prompt>
Your improved prompt here...
</improved_prompt>Promptimでのプロンプト最適化実践
それでは、Quick Startよりも複雑なシナリオでPromptimを使用してみたいと思います。
シナリオとしては、まずReactコンポーネントを生成するための簡素なプロンプトを作り、Promptimでより好みのコードが出力されるように最適化を行います。
初期プロンプトとデータセットの登録
まず、ベースとなるプロンプトをLangSmithに登録します。component変数にコンポーネント名を渡すとReactのコードを生成してくれるシンプルなプロンプトを作成しました。
Output the code for the following React UI component. Output should be code only.
# component
{component}次に、コンポーネント名が入ったCSVをデータセットとして登録します。以下のCSVを用意しました。
component
NavBar
Button
TextField
Select
Radio
Checkbox
Dialog
Tab
Loader
Cardタスクの作成
プロンプトを最適化するためのタスクを作成します。
promptim create task ./generate-ui-component \
--name generate-ui-component \
--prompt <prompt_name>:<commit_hash> \
--dataset <dataset_name> \
--description "Generate React UI Component." \
-yコードの更新
まず先程と同様にOpenAIのモデルを使用するためにconfig.jsonを更新します。
次にtask.pyの更新なのですが、今回のシナリオはコードで評価基準を表現することが困難なため、LLMに評価を行ってもらいます。
LLMを使った評価
それではLLMで評価するようにtask.pyを更新します。以下が変更後のコードの全量です。
from langchain_core.messages import AIMessage
from langsmith.schemas import Run, Example
from pydantic import BaseModel
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
class Evaluation(BaseModel):
score: float
correction_points: list[str]
template = """
Consider improvements needed to bring the code closer to the sample code.
If the development language, framework, and code style match the sample code, it is considered OK. Detailed design details such as font size and color do not need to be evaluated.
# Sample code
This sample code is `Button` component.
\`\`\`
import React from "react";
type ButtonProps = {{
label: string; // ボタンのテキスト
onClick: () => void; // クリック時の動作
variant?: "filled" | "outlined" | "text"; // ボタンのスタイル
color?: "primary" | "secondary" | "danger"; // カラーバリエーション
disabled?: boolean; // 無効化
}};
const Button: React.FC<ButtonProps> = ({{
label,
onClick,
variant = "filled",
color = "primary",
disabled = false,
}}) => {{
// 色に基づいたスタイル
const baseColors = {{
primary: "text-white bg-blue-500 hover:bg-blue-600",
secondary: "text-gray-700 bg-gray-200 hover:bg-gray-300",
danger: "text-white bg-red-500 hover:bg-red-600",
}};
const outlinedColors = {{
primary: "text-blue-500 border border-blue-500 hover:bg-blue-50",
secondary: "text-gray-700 border border-gray-300 hover:bg-gray-50",
danger: "text-red-500 border border-red-500 hover:bg-red-50",
}};
const disabledStyles = "cursor-not-allowed opacity-50";
// スタイルの決定
const getButtonStyle = () => {{
if (disabled) return disabledStyles;
switch (variant) {{
case "filled":
return baseColors[color];
case "outlined":
return outlinedColors[color];
case "text":
return `text-${{color === "primary" ? "blue" : color}}-500 hover:bg-${{color === "primary" ? "blue" : color}}-50`;
default:
return baseColors.primary;
}}
}};
return (
<button
onClick={{onClick}}
disabled={{disabled}}
className={{`px-4 py-2 rounded-md shadow-md font-medium transition-all duration-200 ${{getButtonStyle()}}`}}
>
{{label}}
</button>
);
}};
export default Button;
\`\`\`
# Output
- Score
- A value that evaluates how close the current code is to the sample code (1 is closest, 0 is farthest)
- Improvement Points
Please evaluate the following code:
{input}
"""
prompt = PromptTemplate(input_variables=["input"], template=template)
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
structured_llm = llm.with_structured_output(Evaluation)
chain = prompt | structured_llm
def example_evaluator(run: Run, example: Example) -> dict:
"""An example evaluator. Larger numbers are better."""
prompt_inputs = example.inputs
reference_outputs = example.outputs
predicted: AIMessage = run.outputs["output"]
result = str(predicted.content)
evaluation = chain.invoke({"input": result})
comment = "\n".join([f"- {c}" for c in evaluation.correction_points])
return {
"key": "evaluator",
"score": evaluation.score,
"comment": comment,
}
evaluators = [example_evaluator]評価用プロンプトでは、出力されたコードをサンプルコードと比較し、スコアと改善ポイントを算出します。この情報により、生成されるコードがサンプルコードにより近づくようプロンプトが改善されます。
サンプルコードとしては、TypeScript/React/TailWindCSSによるボタンコンポーネントをLLMで出力したものを使用しました。また、今回は簡易的にサンプルコードとの比較による評価としましたが、プロンプトを変更することで任意の評価が可能です。
実行
コマンドを実行し、最適化を行います。
promptim train --task ./generate-ui-component/config.json
以下が結果として最適化されたプロンプトです。
<TO_OPTIMIZE kind="User">
Output the code for the following React UI component using TypeScript for type safety. Ensure to include TypeScript type definitions for all props, provide default values where applicable, and implement conditional styling based on props. Focus specifically on the Button component, ensuring support for common variants (like filled, outlined, text) and states (like disabled) to enhance component flexibility. Include a required `label` prop for button text, use an `onClick` prop that must be a function without parameters for handling click events, and ensure the output closely matches the provided sample code structure. Consider using utility-first CSS frameworks (like Tailwind CSS) for styling. The output should be code only.
# component
{component}
</TO_OPTIMIZE>最適化前後での比較
それでは、最適化前後でどのようなコードが出力されるかを確認してみます。 最適化前後のプロンプトでセレクトボックスのコードを出力した結果が以下です。
■最適化前
import React from 'react';
const Select = ({ options, value, onChange, label }) => {
return (
<div className="select-container">
{label && <label className="select-label">{label}</label>}
<select className="select" value={value} onChange={onChange}>
{options.map((option) => (
<option key={option.value} value={option.value}>
{option.label}
</option>
))}
</select>
</div>
);
};
export default Select;■最適化後
import React from 'react';
type SelectVariant = 'default' | 'outlined' | 'filled';
type SelectColor = 'primary' | 'secondary' | 'danger' | 'success';
interface SelectProps extends React.SelectHTMLAttributes<HTMLSelectElement> {
options: Array<{ value: string; label: string }>;
label?: string;
variant?: SelectVariant;
color?: SelectColor;
disabled?: boolean;
loading?: boolean;
onChange?: (event: React.ChangeEvent<HTMLSelectElement>) => void;
}
const defaultProps = {
variant: 'default' as SelectVariant,
color: 'primary' as SelectColor,
disabled: false,
loading: false,
};
const Select: React.FC<SelectProps> = ({
options,
label,
variant,
color,
disabled,
loading,
onChange,
...rest
}) => {
const containerClassName = `select-container ${variant} ${color}`;
return (
<div className={containerClassName}>
{label && <label className="select-label">{label}</label>}
<select
className={`select ${loading ? 'select-loading' : ''}`}
disabled={disabled || loading}
onChange={onChange}
{...rest}
>
{loading ? (
<option value="" disabled>
Loading...
</option>
) : (
options.map((option) => (
<option key={option.value} value={option.value}>
{option.label}
</option>
))
)}
</select>
</div>
);
};
Select.defaultProps = defaultProps;
export default Select;
// Sample CSS styles (for reference)
/*
.select-container {
margin: 8px 0;
}
.select-label {
display: block;
margin-bottom: 4px;
font-weight: 600;
}
.select {
padding: 8px;
border-radius: 4px;
border: 1px solid #ccc;
}
.select.default {
background-color: #fff;
}
.select.outlined {
border: 2px solid #007bff;
}
.select.filled {
background-color: #f0f8ff;
}
.select-primary {
border-color: #007bff;
}
.select-secondary {
border-color: #6c757d;
}
.select-danger {
border-color: #dc3545;
}
.select-success {
border-color: #28a745;
}
.select-loading {
color: gray;
}
*/最適化前のコードと比較すると、最適化後のコードはサンプルにより近づきました。最適化の効果が確認できています。
ただ、最適化後もTailwindCSSが利用されないままでした。こちらは、反復数を増やす、--annotation-queueでコメントを追加する、評価プロンプトを変更する、などの対応により改善できる可能性があります。
まとめ
本記事では、LangChainが紹介している「Promptim」というツールを使って、プロンプトの最適化ができるかを試してみました。
プロンプトは、LLMの出力品質を大きく左右する重要な要素です。しかし、手動での微調整は非常に手間がかかります。Promptimを活用することで、このプロセスを効率化し、自動的に最適化を進めることが可能です。興味が出た方は、ぜひ試してみてください。
執筆者プロフィール:武藤 将太
SHIFT アプリケーション開発テクノロジーグループのエンジニア。
主にWebシステムの開発経験を経て、SHIFTに入社。
平日のお昼に週2しらたきを導入することで体重スケールアップを阻止中
✅SHIFTへのお問合せはお気軽に
SHIFTについて(コーポレートサイト)
SHIFTのサービスについて(サービスサイト)
SHIFTの導入事例
お役立ち資料はこちら
SHIFTの採用情報はこちら
PHOTO:UnsplashのArtturi Jalli