

【Node.js】コード修正で処理速度を1/10にした方法

はじめに
こんにちは、SHIFTアプリケーション開発テクノロジーG(旧DAAEテクノロジーG)の島田です。
処理速度の改善といえばDBアクセスやスケーリングなどが注目されがちですが、今回はコードに焦点を当てた対策を共有したいと思います。過去には改善前と比べて処理時間を1/10にできた実績もあります。
他の言語、FWで利用できる対策もあるので、普段Node.jsを使っていない方にもご参考になれば幸いです。
前提
どんなシステムでも改善効果はありますが、多重ループなど重い処理があるとより有効です。
大きな速度改善が期待できる例として、ここでは以下のようなシステムを想定しています。
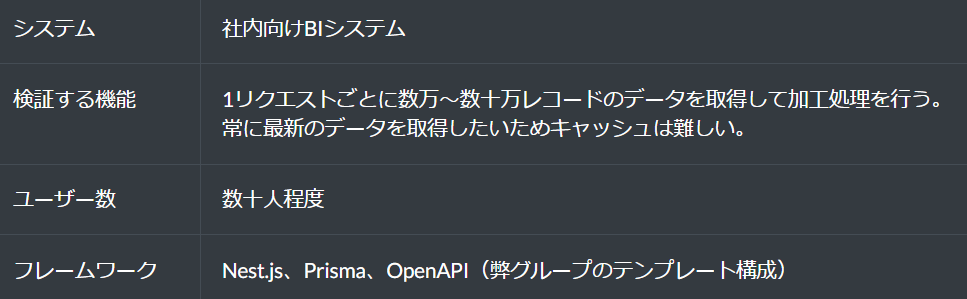
評価基準
改善効果: どれくらい処理速度を改善できるか
適用範囲: どれくらいのコードで使えそうか
1. ArrayをMapへ変換
改善効果: ★★★★☆
適用範囲: ★★★★☆
配列のデータをキーバリュー型に変換することで処理時間を短縮します。
配列のarray.find()で先頭から順に検索するとO(n)かかってしまいますが、キーバリュー型ならO(1)で取得できます。
変更前(Arrayの処理)
// 店舗の日別売上高
const sales: {
date: string; // 日付
shop: string; // 店舗
sales: number; // 売上高
}[];
// 当日の該当店舗の売上高を取得
sales.find(({date, shop}) => date === today && shop === targetShop);変更後(Mapの処理)
// 店舗の日別売上高
// Key: 日付@店舗
// Value: 売上高
const sales: Map<string, number>
// 当日・該当店舗の売上高を取得
sales.get(`${today}@${targetShop}`)一つのキーに複数件該当する場合はバリューに配列を指定します。
// 店舗・部門ごとの日別売上高
type SalesForSection = {
date: string; // 日付
shop: string; // 店舗
section: string // 部門
sales: number; // 売上高
}[];
// 部門ごとの売上高リスト
const salesValue: SalesForSection[]
// 店舗の日別売上高
// Key: 日付@店舗
// Value: 部門ごとの売上高リスト
const sales: Map<string, SalesForSection[]>
// 当日・該当店舗の部門ごとの売上高リストを取得
salas.get(`${today}@${targetShop}`)2. ループ処理をまとめる
改善効果: ★★★★★
適用範囲: ★★☆☆☆
複数データのループ処理を一つにまとめます。
例えば1ヶ月分の注文・売上・仕入のデータを日別に処理する場合、日ごとにフィルターをかけるより、データをまとめて一つのfor文で処理する方が早い場合もあります。
ものによってはかなり処理数が減りますが、適用箇所が限られる、可読性が落ちるといったデメリットがあります。
以下のデータがある場合
// 1ヶ月分の注文リスト
const orders: Order[] = [
{ date: '2023-10-01', amount: 100 },
{ date: '2023-10-02', amount: 150 },
// ... more data
];
// 1ヶ月分の売上リスト
const sales: Sale[] = [
{ date: '2023-10-01', revenue: 200 },
{ date: '2023-10-02', revenue: 250 },
// ... more data
];
// 1ヶ月分の仕入リスト
const purchases: Purchase[] = [
{ date: '2023-10-01', cost: 50 },
{ date: '2023-10-02', cost: 75 },
// ... more data
];変更前(日ごとにフィルターをかける)
const dates = ['2023-10-01', '2023-10-02', ...]; // 1ヶ月分の日付リスト
dates.forEach(date => {
// 日ごとの注文、売上、仕入
const dailyOrders = orders.filter(order => order.date === date);
const dailySales = sales.filter(sale => sale.date === date);
const dailyPurchases = purchases.filter(purchase => purchase.date === date);
dailyOrders.forEach(order => {
// 注文の処理
console.log(`Order on ${date}: ${order.amount}`);
});
dailySales.forEach(sale => {
// 売上の処理
console.log(`Sale on ${date}: ${sale.revenue}`);
});
dailyPurchases.forEach(purchase => {
// 仕入の処理
console.log(`Purchase on ${date}: ${purchase.cost}`);
});
});変更後(一つのfor文で処理する)
// 注文、売上、仕入れの最大数を取得
const maxSize = Math.max(orders.length, sales.length, purchases.length);
for (let i = 0; i < maxSize; i++) {
if (i < orders.length) {
const order = orders[i];
// 注文の処理
console.log(`Order on ${order.date}: ${order.amount}`);
}
if (i < sales.length) {
const sale = sales[i];
// 売上の処理
console.log(`Sale on ${sale.date}: ${sale.revenue}`);
}
if (i < purchases.length) {
const purchase = purchases[i];
// 仕入れの処理
console.log(`Purchase on ${purchase.date}: ${purchase.cost}`);
}
}3. 非同期関数の並列処理
改善効果: ★★☆☆☆
適用範囲: ★★★★★
非同期関数(async/await)を使っている場合は並列処理できないか検討してみます。
データの加工処理が重い場合、データ取得を改善しても効果が薄いですが、ほぼ確実に適用できるのでやっておいて損はないと思います。
変更前
const customer = await connection.getRepository(Customer).findOne({ id: customerId });
const orders = await connection.getRepository(Order).find({ customerId: customerId });
const products = await connection.getRepository(Product).find();変更後
const [customer, orders, products] = await Promise.all([
connection.getRepository(Customer).findOne({ id: customerId }),
connection.getRepository(Order).find({ customerId: customerId }),
connection.getRepository(Product).find()
]);4. マルチスレッド化
改善効果: ★★★☆☆
適用範囲: ★★★★☆
Node.jsは基本シングルスレッドですが、多重ループのようなCPU負荷のかかる処理ではマルチスレッド化も有効です。
4.1. クラスタリング
CPUコア分のプロセスを同時起動してリクエストを分散処理する方法です。
リクエスト数が多い場合に効果的です。
※以下はNest.js用のコード例です。
変更前
main.ts
import { NestFactory } from "@nestjs/core";
import { AppModule } from "./app.module";
async function bootstrap() {
const app = await NestFactory.create(AppModule);
await app.listen(3000);
}
bootstrap();変更後
cluster.service.ts
import { Injectable } from '@nestjs/common';
const cluster = require('cluster');
import * as process from 'node:process';
// コア数を取得
const numCPUs = parseInt(process.argv[2] || "1");
@Injectable()
export class ClusterService {
static clusterize(callback: Function): void {
if (cluster.isMaster) {
console.log(`MASTER SERVER (${process.pid}) IS RUNNING `);
// コア数分のプロセスを起動
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log(`worker ${worker.process.pid} died`);
});
} else {
callback();
}
}
}main.ts
import { NestFactory } from "@nestjs/core";
import { AppModule } from "./app.module";
import { ClusterService } from './cluster.service';
async function bootstrap() {
const app = await NestFactory.create(AppModule);
await app.listen(3000);
}
ClusterService.clusterize(bootstrap);参考
4.2. Worker Threads
Worker Threadsを使って重い処理だけ別スレッドで実行する方法もあります。
クラスタリングはリクエストごとにスレッドを分けますが、こちらは1リクエスト内でマルチスレッド処理できるので、少ないリクエスト数でも効果があると思います。
私は実装したことがないので、以下のリンクをご参考ください。
参考
https://qiita.com/suin/items/bce351c812603d413841
5. ライブラリの見直し
改善効果: ★★★★☆
適用範囲: ★★★☆☆
特定のライブラリが処理速度に思わぬ影響を及ぼすこともあります。
以前、日付管理ライブラリとしてday.jsを採用していました。日付の比較に多用していましたが、数回だけであればほとんど処理時間に影響はないものの、何万回も実行するとかなりの差が発生してしまいました。
そのため、できるだけDayjs型ではなくstring型を使用するように変更しました。
変更前
date.isSame(today)
date.isBefore(today)変更後
dateString === todayString // 日付は"YYYYMMDD"形式
dateString < todayString日付の加算・減算(date.add()やdate.subtract())は文字列では厳しいため、そのままday.jsの機能を使いました。
注意点
文字列は日付以外の不正なデータも入力できてしまいます。バリデーションチェックを厳重に行ってください。処理速度に困っていないときは素直にライブラリの使用を推奨します。
まとめ
以下の方法で速度改善策を上げてみました。
ArrayをMapへ変換
ループ処理をまとめる
非同期関数の並列処理
マルチスレッド化
ライブラリの見直し
速度改善はコードの可読性や安全性とのトレードオフです。用法用量を守って実施してください。
\もっと身近にもっとリアルに!DAAE 公式 X/
執筆者プロフィール:島田 拓斗
2024年4月にSHIFTへ入社。前職ではSIerでSEとして業務システム開発を経験。現在はエンジニアとしてWebアプリケーションの開発を行っている。
好きなコーヒーはクリスタルマウンテン。
お問合せはお気軽に
https://service.shiftinc.jp/contact/
SHIFTについて(コーポレートサイト)
https://www.shiftinc.jp/
SHIFTのサービスについて(サービスサイト)
https://service.shiftinc.jp/
SHIFTの導入事例
https://service.shiftinc.jp/case/
お役立ち資料はこちら
https://service.shiftinc.jp/resources/
SHIFTの採用情報はこちら
https://recruit.shiftinc.jp/career/
PHOTO:UnsplashのMarkus Spiske