

テキスト処理の落とし穴20選 - 堅牢な実装を目指して

はじめに
ご覧いただきありがとうございます。SHIFTのDAAE部に所属しているshinagawaです。
本記事ではアプリケーション開発におけるテキスト処理の実装において、これまでの自分の経験の中で見た・聞いた・ハマった事象の中で印象的だったものを大雑把に列挙しました。
地味なテーマではありますが、堅牢な実装を目指していく上で疎かにできない部分を主観でまとめたので、ぜひご覧いただけると幸いです。
本記事が扱うキーワード
本記事では次のキーワードの周辺領域について触れています。
コードポイント
サロゲートペア
ゼロ幅 / ZWJ
バイトオーダーマーク (BOM)
合字 / 組文字 / 結合文字
正規表現
日本語 (かな/カナ/カナ/仮名)
CJK統合漢字 / CJK互換漢字
異字体セレクタ
特殊記号 / 制御文字
文字コード (Unicode / Shift_JIS / EUC)
JIS第一水準 / 第二水準
セキュリティ / 脆弱性
フォント
注意事項
本記事では特に断りがなければUnicodeの事象として説明しています。
本記事は特殊な記号・文字を多用しているので、ご利用の環境次第では正しく閲覧できない可能性があります。
本記事で行った検証は個人的な趣味でJavaScript (Node.js v20)を利用しています。他の言語・ランタイムで同じ事象が起きるかという点までは考慮していません。
1. サロゲートペアを考慮した文字列の操作
コードポイント: コンピュータで文字を扱うために文字それぞれに割り当てられた数値
例えばUnicodeで「あ」であれば「 U+3042」が割り当てられている
サロゲートペア: 1つの文字に対し、2つの文字コードポイントを利用して表される文字
「文字列長を取得する」「先頭の文字を取得する」「スプリットする」
このような実装で一つ気をつけなければならないのは、サロゲートペア文字の考慮です。
例えば、次のサンプルコードのようにサロゲートペアを含む場合に1つの文字数(コードポイント)が「2」とカウントされ、意図しない結果となる可能性があります。
// 通常の文字
console.log("a".length) // 1
console.log("あ".length) // 1
console.log("吉".length) // 1
// サロゲートペア
console.log("𠮷".length) // 2
console.log("𩺊".length) // 2
console.log("🍇".length) // 2
console.log("𠮷吉".split('')) // �,�,吉そのため サロゲートペアを1文字として扱いたい場合は、次のコードのように文字列を配列としてスプリットしてカウントさせるのが1つの手となります。
console.log(Array.from("𠮷").length) // 1
console.log([..."🍇"].length) // 1
console.log(Array.from("𠮷吉")) // 𠮷,吉また、HTMLのinput要素で利用できるmaxlength 属性や minlength 属性もサロゲートペアの長さを「2」としてカウントします。
<input type="text" maxlength="2">このように、言語標準の文字列操作関数・メソッド・オブジェクト等は、 1文字のサロゲートペア文字の長さを「2」として扱う場合があり、こういった点に気をつける必要があります。
参考サイト
Unicode 絵文字にまつわるあれこれ (絵文字の標準とプログラム上でのハンドリング) - Qiita
2. サロゲートペアと正規表現
サロゲートペアでもう1点触れておきたいのが正規表現です。
console.log(/^[a]$/.test("a")) // true
console.log(/^[a]$/u.test("a")) // true
console.log(/^[𠮷]$/.test("𠮷")) // false
console.log(/^[🍇]$/.test("🍇")) // false
console.log(/^[𠮷]$/u.test("𠮷")) // true
console.log(/^[🍇]$/u.test("🍇")) // true上記のコードは、サロゲートペアと正規表現の関係を示しています。
通常の正規表現では、サロゲートペアを正しく扱えないことがあります。この例では、文字 "a" は通常の正規表現で問題なくマッチングされますが、サロゲートペアである "𠮷" や "🍇" は通常の正規表現ではうまく処理できません。
しかし、正規表現の末尾に u フラグを付けることで、サロゲートペアを含むUnicode文字を正しく扱うことができます。
3. ゼロ幅接合子とZWJシーケンス
ゼロ幅接合子: アラビア文字等で利用される文字を接合して表現するために利用する制御文字。コードポイントはU+200D。
ZWJシーケンス: ゼロ幅接合子(U+200D)を用いて複数の絵文字を組み合わせて1つの絵文字を表現する仕組みのこと
例えば、「👩💻」という絵文字はZWJシーケンスを利用して、「👩」(女性の絵文字)と「💻」(パソコンの絵文字)を結合したものです。
console.log("👩💻".length) // 5
console.log(Array.from("👩💻").length) // 3
console.log(JSON.stringify(Array.from("👩💻"))) // ["👩","","💻"]
console.log("👨👨👦👦".length) // 11
console.log(Array.from("👨👨👦👦").length) // 7
console.log(JSON.stringify(Array.from("👨👨👦👦"))) // ["👨","","👨","","👦","","👦"]上記のコードのように、画面上では1文字の幅であるが、実際には複数のコードポイントを持つことになります。このように、ZWJシーケンスを使用することで、多様な絵文字の組み合わせを表現することが可能となります。
技術的な取り扱いには注意が必要であり、文字列操作や文字数の計算などでは、結合された絵文字を正しく処理できるように対応する必要があります。
参考サイト
絵文字の文字列操作: '👨🏻💻'.replace('💻', '🏫') === '👨🏻🏫' - Qiita
4. ゼロ幅文字
ゼロ幅接合子に加えて、文字幅がない文字としてゼロ幅非接合子とゼロ幅スペースが存在します。これらを利用することで、通常の文字列と見分けがつかないような「ぱっと見1文字に見える文字列」を作ることができます。
const c = [
String.fromCodePoint(0x200B), // ゼロ幅スペース
String.fromCodePoint(0x200C), // ゼロ幅非接合子
String.fromCodePoint(0x200D), // ゼロ幅接合子
'a',
].join('')
console.log(JSON.stringify(c)) // "a"
console.log(c.length) // 4上記のサンプルコードは、ゼロ幅スペース、ゼロ幅非接合子、ゼロ幅接合子、そして通常のアルファベットの "a" を連結しています。それにもかかわらず、結果として表示される文字列は "a" となります。これは、ゼロ幅文字が文字幅を持たないため、実際の文字数が4つあるにもかかわらず、ビジュアル上は1文字として表示されるためです。
ゼロ幅文字は通常、テキストを装飾したり、文書の形式を工夫する際に利用されます。また、セキュリティの観点からも、文章を検索対象から外したり、特定のテキストの存在を隠すために使用されることもあります。
5. 見えない文字とトリミング
「見えない文字」とは、ゼロ幅文字に加えて半角スペースや全角スペース、タブ、制御文字など目視が困難な文字のことを指しています。
Unicode characters you can not see
では見えない文字を54種類紹介しています。
これらの文字をトリミング系の組み込み関数や正規表現のメタ文字を使用して処理しようとすると、意図しない結果になる可能性があります。
例えば、次のサンプルコードのように、見えない文字のトリミングに失敗する可能性があります。
// 半角スペース
let c = ' '
console.log(JSON.stringify(c)) // " "
console.log(c.trim().length) // 0
console.log(c.replace(/\s+/g, '').length) // 0
// 全角スペース
c = ' '
console.log(JSON.stringify(c)) // " "
console.log(c.trim().length) // 0
console.log(c.replace(/\s+/g, '').length) // 0
// ハングルのフィラー
c = String.fromCodePoint(0x3164)
console.log(JSON.stringify(c)) // "ㅤ"
console.log(c.trim().length) // 1
console.log(c.replace(/\s+/g, '').length) // 1
// ハングルの半角フィラー
c = String.fromCodePoint(0xFFA0)
console.log(JSON.stringify(c)) // "ᅠ"
console.log(c.trim().length) // 1
console.log(c.replace(/\s+/g, '').length) // 1実際に一部のWebサービスでは、半角スペースや改行コードはトリムされるが、他の見えない文字はトリムされないという事象を観察しています。
また、これと似たようなテクニックを利用して、公式名称と誤認させたり、悪意のあるアプリをダウンロードさせる攻撃が行われた事例も存在します。
参考サイト
チャットアプリ「WhatsApp」の偽物、Google Playで100万回以上もダウンロード - CNET Japan
6. BYTE ORDER MARK: BOM
UTF-8のファイル読み込みなどの処理において、忘れがちなのがBOM(バイトオーダーマーク)周りの処理です。
BOMとは、Windowsのメモ帳などのエディタでテキストファイルをUTF-8で保存する際に先頭に付与される特殊なマーク(U+FEFF)であり、エンコーディングの判定に利用されます。
個人的には、このようなBOMに関連する仕組みはあまり好きではありませんが、一般的に普及しているソフトウェアがBOM付きで保存できてしまう以上は、ファイルをパースして先頭の行を利用するような処理においては、エラーハンドリングを施してあげることが重要だと考えています。
7. 波ダッシュ(〜)と全角チルダ(~)問題

波ダッシュ(〜)と全角チルダ(~)はUnicodeではそれぞれ U+301C と U+FF5E という異なる文字として定義されています。
console.log("〜" === "~") // false言うまでもなくバリデーションや置換等の処理ではこの2つの違いを考慮する必要があります。
この2つの文字の関係をより厄介な問題にしているのが「Windowsと他の端末ではキーボードから入力できる『〜』が異なる」という点です。
これはShift_JISの特徴に起因しています。
Shift_JISは波ダッシュを全角チルダと同一視するという問題を抱えています。 そしてShift_JISはWindowsの標準のロケールとして利用されているため、Windowsで「〜」キーを押下すると全角チルダが入力され波ダッシュを入力することが困難になっています。
参考サイト
8. 昔は全角チルダ(~)の形は違っていた
グリフ: 字体とほぼ同義語であるが、記述記号やスペースなども含めたもの
昔は全角チルダのグリフの「山」と「谷」が逆でした。
Unicode 7.0(2014年以前)のバージョンでは、全角チルダは波ダッシュとは異なる形をしていましたが、Unicode 8.0で波ダッシュと同じ形に統一されました。
しかしながら、一部の古い端末やフォントによっては、以前と同じ形のグリフとして表示されることがあります。

9. 円記号問題

上記の波ダッシュと全角チルダの問題に類似したものとして、「\」(バックスラッシュ)と「¥」(円記号)の関係にも問題が存在します。プログラミングの資料を見ているとエスケープシーケンスに「\」を利用している場合と「¥」を利用している場合があり違和感を感じた方もいるかもしれません。
これはASCIIコード上では0x5Cにバックスラッシュが割り当てられているのに対し、JIS X 0201(日本工業規格で制定している文字コード)では0x5Cに円記号が割り当てられていることに起因します。
実際に発生する問題としては、特に日本語環境において、バックスラッシュと円記号が混同されることがあります。Windowsのファイルパス表示やプログラム内の文字列リテラルなどで、意図しない文字が表示される原因となることがあります。
参考サイト
10. 横棒のような記号がたくさんある
「横棒」として扱われる文字にはハイフン、マイナス、ダッシュ、長音符、そして漢字の一(イチ)などの記号があります。これらの文字は外見が似ているため、間違って利用されることが少なくありません。
これらの文字は、単純な置換やバリデーションだけでは十分に扱いきれないケースがあることに注意が必要です。
以下に、代表的な横棒のようなグリフの文字を示します。
ハイフン: -
マイナス: -
ダッシュ: ﹣
長音符: −
漢字の一(イチ): 一
全角ダッシュ: -
全角マイナス: -
全角ハイフン: ーさらに、他にも…
--﹣−‐⁃‑‒–—﹘―⎯⏤ーー─━参考サイト
Unicodeにあるハイフン/マイナス/長音符/波線/チルダのコレクション | hydroculのメモ
11. 横棒以外にも似たような記号がたくさんある
横棒以外にも似たような文字の組み合わせはいくつか存在します。その例が以下です。
# ダブルクォーテーション・二重引用符・濁点...
” " “ ” ゙ ゛
# 丸、漢字のゼロ、大きなサークル、ミディアムホワイトサークル、アルファベットのO(オー)...
○ 〇 ◯ ⚪︎ o O O o ο
# バツ、エックス
× 窱 x X ✖️ x X
# イチ、l(エル小文字)、I(アイ大文字)、パイプ、罫線、バーティカルバー...
1 1 l I I l ! | | │ ┃
# シングルクオート、アポストロフィー、バッククオート...
’ ' ‘ ' ` ' `
# 中黒、中点、ビュレット...
· • ∙ ⋅ ・ ・
# リーダー
… ⋯ ‥
# 小文字G、ラテンスモールキャピタルG
g ɡ
# スラッシュ、ディビジョンスラッシュ
/ ∕これらの文字や記号は、使用するフォントによっては全く違いがわからなかったり、微妙な違いが生じることがあります。特に技術文書やプログラムのソースコードなどでは、正確な文字の選択が重要となる場合があるため、注意が必要です。フォントの選択やコンテンツの閲覧環境に配慮しつつ、正確な文字を使用するよう心掛けたいところです。
余談ですがVisualStudioCodeでは似たような形の文字を警告してくれるので便利ですね。
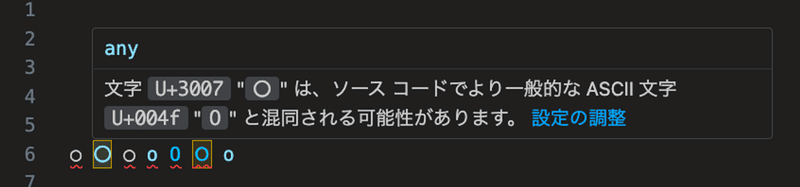
12. 平仮名の正規表現
結論から言うとこのセクションで言いたいことは「Unicodeのコード表を確認しておかないと見落とすかもしれない」という話です。
平仮名や片仮名を利用する正規表現については後述する文字プロパティを使えば簡単に定義できますが、ここでは文字プロパティを利用しない文字の範囲でマッチさせるような正規表現の話をします。
平仮名の正規表現パターンとしてよく見かけるのは以下のようなものです。
/[ぁ-ん]/ これは五十音の平仮名の「あ」から「ん」までにマッチしますが、歴史的仮名遣いである「ゐ」や「ゑ」も含まれてしまいます。もし意図的にこれらの文字を除外したい場合は、この正規表現を使用することはできません。
また、「ゔ」「ゕ」「ゖ」なども上記の正規表現にはマッチしません。これらの文字を含めるためには、以下のように正規表現を修正する必要があります。
/[ぁ-ゖ]/とする必要があります。
また、踊り字(ゝ ゞ )や「より」の合字(ゟ)も含まれていません。これらの必要に応じて正規表現を調整する必要があります。
# 踊り字
ゝ ゞ
# 「より」の合字
ゟ詳細な説明はしませんが片仮名の正規表現もこれと同様な考え方で考慮すべきものを判断したほうが良いかもしれません。
13. 平仮名と片仮名を相互に変換する
平仮名と片仮名の相互変換は、1対1のコードポイントで完全に行えるわけではありません。
例えば、片仮名の「ヷ (U+30F7)」に対応する平仮名の「ヷ」はUnicode上に存在しません。そのため、「ヷ」を表現する場合は、結合文字である濁点記号(U+3099)を付与して「わ゙」(U+308F U+3099) と表現する必要があります。
console.log('ヷ'.length) // 1
console.log('ヷ' === '\u30F7') // true
console.log('わ゙'.length) // 2
console.log('わ゙' === '\u308F\u3099') // true他にも、片仮名に存在して平仮名に存在しない文字がいくつかあります。これらの文字を相互変換する場合は、適切な結合文字などを組み合わせる必要があります。
# 片仮名
ヷ (U+30F7)
ヸ (U+30F8)
ヹ (U+30F9)
ヺ (U+30FA)また小書きの片仮名で平仮名に存在しないものもあります。
# 片仮名 (小書き)
ㇰ (U+31F0)
ㇱ (U+31F1)
ㇲ (U+31F2)
ㇳ (U+31F3)
ㇵ (U+31F5)
ㇶ (U+31F6)
ㇷ (U+31F7)
ㇸ (U+31F8)
ㇹ (U+31F9)
ㇻ (U+31FB)
ㇼ (U+31FC)
ㇽ (U+31FD)
ㇾ (U+31FE)
ㇿ (U+31FF)14. Unicode文字プロパティ
正規表現におけるUnicode文字プロパティは、Unicodeの特性やカテゴリに基づいて文字を分類し、パターン内でそれらのプロパティを指定することで、異なる言語や文字体系に対応する柔軟なマッチングを実現します。
例えば、正規表現内で\p{L}と指定すると、すべての文字カテゴリ(Letter)にマッチすることができます。
const regex = /\p{L}/u; // Unicode文字プロパティを利用
console.log(regex.test("こんにちは")); // true
console.log(regex.test("Hello")); // true
console.log(regex.test("123")); // false他には、\p{Script=Hiragana}と指定すると、日本語のひらがな文字にマッチします。
const regex = /\p{Script=Hiragana}/u; // Unicode文字プロパティを利用
console.log(regex.test("こんにちは")); // true
console.log(regex.test("Hello")); // false
console.log(regex.test("あいうえお")); // trueまた、\p{Number}を使うことで、アラビア数字、ローマ数字、漢数字などあらゆる数字にマッチングできます。
const regex = /\p{Number}/u; // Unicode文字プロパティを利用
console.log(regex.test("123")); // true
console.log(regex.test("Ⅳ")); // true (ローマ数字)15. 同じ漢字が複数存在する
Unicodeには、同じ漢字に対して複数のコードポイントが存在する場合があります。これらはCJK互換漢字と呼ばれるもので、グリフは殆ど同じでもコードポイントが異なる文字です。
例として、「都」と「都」はほぼ同じグリフに変換されますが、それぞれ異なるコードポイントを持っています。したがって、等価比較を行うと異なる文字として扱われます。
console.log(String.fromCodePoint(0xFA26)) // 都
console.log(String.fromCodePoint(0x90FD)) // 都
console.log('都' === '都') // false他にも
朗(U+F929)と朗(U+6717)
類(U+F9D0)と類(U+985E)
殺(U+F970)と殺(U+6BBA)
郎(U+F92C)と郞(U+90DE)と郞(U+FA2E)
隷(U+96B7)と隸(U+F9B8)と隷(U+FA2F)
等があります。
※郎と隷はCJK互換漢字ブロックで誤って定義されて再定義されたもの。
特定の漢字を制限する場合は、CJK互換漢字も考慮に入れて適切な処理を行う必要があります。
const checkInput = (str) => {
const pattern = /類/i
return pattern.test(str)
}
checkInput('類') // あなたはNGです
checkInput('類') // あなたはOKです16. 異字体セレクタ
異字体セレクタは、文字の字体を詳細に指定するためのセレクタで、U+FE00からU+FEOFの範囲に定義されています。これを用いることで、基底となる文字のコードポイントに対してセレクタのコードポイントを加えることで異体字を表現できます。
異体字セレクタを使用することで、同じ文字でも異なるグリフで表示することが可能となります。例として、葛飾区の「葛」を基底文字として異体字セレクタを付与すると、「葛󠄀」のように表示されます。
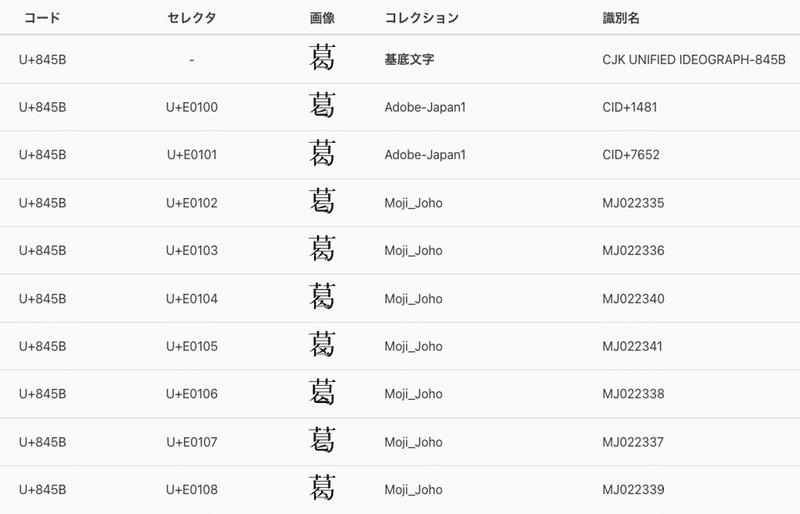
これを利用することで、特定の字体を強制的に表示させたり、文化や表現の違いに対応した表示を行ったりすることができます。
17. East Asian Width
Unicodeには文字幅(East Asian Width)という概念が存在し、特定の文字が半角文字や全角文字として扱われるかを示す情報が含まれています。
文字幅を考慮して文字列を表示することは、等幅フォントが普及した現在においてもCLIアプリケーションのユーザーインターフェースを考える上で気をつけたい要素の一つです。
ここで、文字列の表示や文字数のカウントにどのように影響を与えるかについて見ていきます。
Unicodeの文字幅は、以下の4つのカテゴリーに分類されます
Narrow(N): 半角文字(ASCII文字や半角カタカナなど)の幅
Wide(W): 全角文字(全角カタカナや漢字など)の幅
Ambiguous(A): 半角・全角の両方で使われる文字
Neutral(Na): 幅が一意に決まらない文字(例: 制御文字など)
このうち全角に該当する文字は
https://unicode.org/Public/UNIDATA/EastAsianWidth.txtにて定義されているため、これをパース処理に応用することで全角文字の判定が可能となります。
18. 絵文字の差異
Unicodeが新しいバージョンにアップデートされるたびに、新しい絵文字が追加されたり、既存の絵文字のデザインが変更されたりすることがあります。
例えば、Unicode 9.0では"🤖"(ロボットの絵文字)が追加され、Unicode 12.0では"🥺"(泣いている顔の絵文字)が追加されました。
このように新しい絵文字が追加されることによって、より多様な表現をすることが可能になりますが、古いバージョンの端末やアプリケーションでは新しい絵文字が正しく表示されない場合があります。
また、特定の端末ばかり利用していると気付きづらい問題だと思いますが、絵文字は異なるプラットフォーム間で絵が若干異なったりしていたり、場合によっては絵文字が存在しないケースもあります。
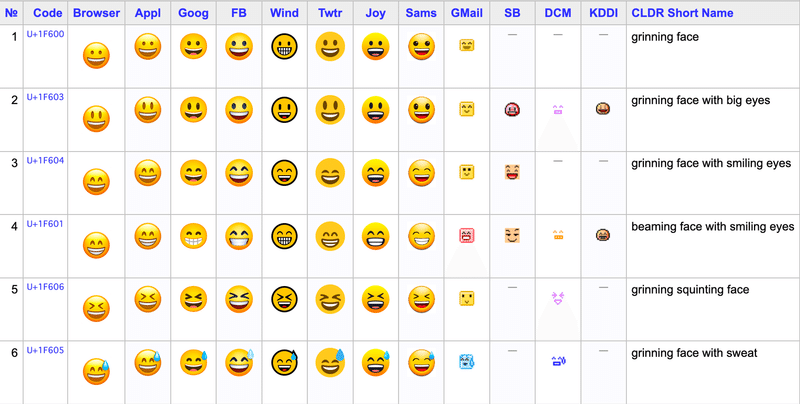
システムで絵文字を重用する場合はこういった点を留意できれば良いのかなと思います。
19. RIGHT-TO-LEFT OVERRIDE: RLO
U+202E RIGHT-TO-LEFT OVERRIDE (RLO) は、アラビア語・ヘブライ語等の右から左へ読む言語のために表示方向を切り替えるための制御文字です。
古典的な攻撃手法として拡張子を含む文字を見た目上反転させて、別の拡張子に偽装するような攻撃が存在したりします。
console.log(`Hello ${String.fromCodePoint(0x202E)} World`);
// Hello World
// txt ファイルに偽装した exe ファイル
console.log(`hello-${String.fromCodePoint(0x202E)}txt.exe`);
// hello-txt.exe参考サイト
第10回 文字コードが引き起こす表示上の問題点[後編] | gihyo.jp
20. Unicode正規化
Unicodeの正規化とは、Unicode文字列内の文字表現を標準化する処理のことです。
Unicodeは世界中の多くの言語や文字体系をサポートするため多くの文字を含んでおり、同じ文字を異なる方法で表現することができる場合があります。
その一つの例が平仮名の濁音の「が」です。
「が」は 「U+304C」という1つのコードポイントのみで表現することもできますが、「か」(U+304B)と濁音記号の「 ゙ 」(U+3099)を組み合わせて合字とすることでも表現ができます。
正規化を行うことで、これらの異なる表現を1つの標準的な形式に変換することで、文字列の比較や検索などの操作を容易にします。
正規化の方法は以下の4種類があります。
NFC(Normalization Form Canonical Composition):結合文字として正規化する
NFD(Normalization Form Canonical Decomposition): 文字を分解し、基本文字とそれに続く結合文字(または修飾子)に分割する
NFKC(Normalization Form KC): 合成文字や互換性のある文字を正規化し、より単純な表現に変換する
NFKD(Normalization Form KD): 合成文字を分解し、互換性文字をそれに対応するASCII文字に変換する
const s1 = "\u304C"; // が
const s2 = "\u304B\u3099"; // が
console.log(s1.length); // 1
console.log(s2.length); // 2
console.log(s1.normalize('NFC')); // が (U+304C)
console.log(s2.normalize('NFC')); // が (U+304C)
console.log(s1.normalize('NFC').length); // 1
console.log(s2.normalize('NFC').length); // 1
console.log(s1.normalize('NFD')); // が (U+304B + U+3099)
console.log(s2.normalize('NFD')); // が (U+304B + U+3099)
console.log(s1.normalize('NFD').length); // 2
console.log(s2.normalize('NFD').length); // 2このUnicode正規化を行う際に気をつけたいのがバリデーションとの兼ね合いです。
例えば「‥」(2点リーダー: U+2025) はNFKC または NFKDを用いて正規化すると2つの「.」(U+002E)記号に変換されます。この文字の扱い方を間違えればディレクトリトラバーサル系の攻撃につながることは想像に難くないでしょう。
const s = "\u2025"; // ‥ (2点リーダー)
console.log(s.normalize('NFC')); // ‥ (U+2025)
console.log(s.normalize('NFD')); // ‥ (U+2025)
console.log(s.normalize('NFKC')); // .. (U+002E + U+002E)
console.log(s.normalize('NFKD')); // .. (U+002E + U+002E)
console.log(s.length); // 1
console.log(s.normalize('NFKD').length); // 2また、「<」(全角左尖括弧: U+FF1C) のような記号も「<」(左尖括弧: U+003C)に正規化される場合があり、XSSのような攻撃の原因になりかねません。
const s = "\uFF1C"; // < (全角左尖括弧)
console.log(s.normalize('NFC')); // < (U+FF1C)
console.log(s.normalize('NFD')); // < (U+FF1C)
console.log(s.normalize('NFKC')); // < (U+003C)
console.log(s.normalize('NFKD')); // < (U+003C)こういったリスクを考えるとバリデーションを行う前に正規化を行うのが、1つの手だと思います。
参考サイト
まとめ
本記事ではテキスト処理、特にUnicodeの仕様に起因するハマりやすい箇所についてまとめました。
正直、筆者も理解が追いつかない部分があり説明として不十分な点もあったかと思いますが、見ていただいた人に「簡単なテキスト処理であっても十分に注意を払うべき箇所があり改めて意識していただくことで堅牢な実装に一歩でも近づけてもらうことができれば」という思いで執筆しました。
ご拝読ありがとうございました。
付録: お役立ちリンク・ツール
書き進めるにあたって役立ったサイトやツールを紹介します。
サイト
Unicode コードポイント変換 - ちょびつーる
コードポイントの分析が簡単にできます。
異体字セレクタセレクタ
異字体セレクタを簡単に検索・出力できます。
ホーム | Emoji 絵文字一覧 📓 | EmojiAll 日本語公式サイト
絵文字の意味、使用例、Unicodeコードポイント、高解像度の絵文字画像といった絵文字に関する情報を提供しているサイトです。
Unicode正規化 (NFC, NFKC, NFD, NFKD) 変換 Online - DenCode
Unicode正規化が容易に行えるWebツールです。
文字コード変換ツール
libiconv - GNU Project - Free Software Foundation (FSF)
有名どころですが文字コードの変換ツールとして最初に思い浮かぶところは iconv だと思います。
nkf Network Kanji Filter プロジェクト日本語トップページ
歴史のある日本産の文字コード変換ツールです。近年は名前を見なくなった気がします。
\もっと身近にもっとリアルに!DAAE公式Twitter/
執筆者プロフィール: shinagawa
SHIFTのDAAE部に所属。エンジニアをしております。
アイキャッチ画像は某○HKの歴史ドキュメンタリー番組のOPのパロディです。
お問合せはお気軽に
https://service.shiftinc.jp/contact/
SHIFTについて(コーポレートサイト)
https://www.shiftinc.jp/
SHIFTのサービスについて(サービスサイト)
https://service.shiftinc.jp/
SHIFTの導入事例
https://service.shiftinc.jp/case/
お役立ち資料はこちら
https://service.shiftinc.jp/resources/
SHIFTの採用情報はこちら
https://recruit.shiftinc.jp/career/