

Oracleのインデックスのタイプ

この記事を読むとできるようになること
インデックスの種類と構造を説明できるようになる
アプリケーションの特性に応じて最適なインデックス・タイプを選択できるようになる
はじめに
こんにちは。SHIFTの小澤です。
Oracleでは様々な問合せに対応するため、複数のインデックス・タイプが提供されています。
今回はインデックス・タイプについて見ていきます。
B-Treeインデックス
B-TreeインデックスはOracleの汎用インデックスです。
インデックスの作成時のデフォルトのインデックス・タイプです。
単にCREATE INDEXで作成するとB-Treeインデックスが作成されます。 B-Treeインデックスは単一列(単純)インデックス、複合(連結)インデックスがあります。
B-Treeインデックスには最大32列まで指定できます。
図1はB-Treeの高さが2のB-Treeインデックスです。
この場合、Oracleは2つのブランチブロックを読み込み、リーフブロックにたどり着いてROWIDを取得します。
各ブランチブロックは、チェーン(ブロックのつながり)内の次のブロックIDを格納する行を保持しています。
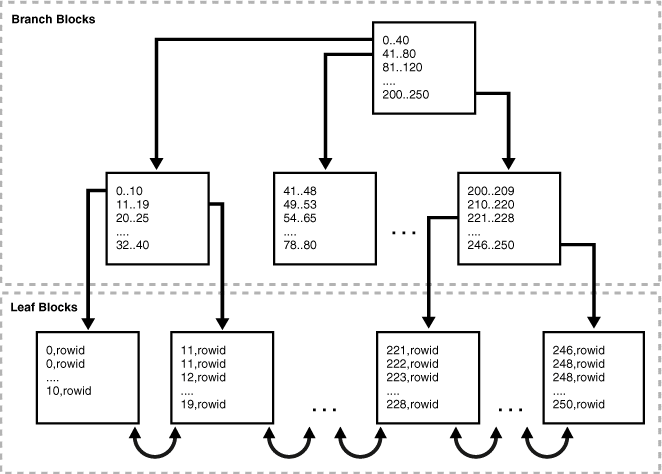
出典:Oracle® Database概要 12c リリース1 (12.1)
各リーフブロックは、インデックス値、ROWID、前のリーフブロック(左隣のブロック)と次のリーフブロック(右隣のブロック)へのポインタを保持しています。
OracleではB-Treeを左右両方向に横断することができます。
B-Treeインデックスには、インデックスした列に値があるテーブル内のすべての行のROWIDが含まれます。
単一列インデックスの場合、インデックスが設定された列にNULL値が含まれる行にはインデックスを作成しません。
複合インデックスの場合、列の1つにNULL値が含まれている場合、その行のインデックスが作成され、NULL値を含む列は空のままになります。
つまり、単一列インデックスではNULL値を検索する問合せでのインデックス利用はできませんが、複合インデックスの場合はインデックスが利用できるケースがあります。
また、インデックスで取得したインデックス値だけでSQLを処理しきれてしまう場合、あらためてテーブルへ値を取得しにいく必要がないのでその分のI/Oを発生させずに済ますことができます。
つまり、テーブルへアクセスさせる代わりにインデックスのアクセスだけでSQLが完了するようにインデックスを作成する、という考え方でチューニングすることもあります。
Bipmapインデックス
Bipmapインデックスは意思決定支援システム(Decision Support System(DSS))やデータウェアハウスで使うと効果的です。
対してオンライントランザクション処理(Online Transaction Processing(OLTP))で使うのは良くありません。
Bitmapインデックスを使うと、大きなテーブルのカーディナリティが低い列に対するアクセスが速くなります。
Bitmapインデックスは30カラムまで指定することができますが、通常は少数の列に対して作成します。
Bitmapインデックスの場合、データベースは各インデックス・キーのBitmapを格納します。
B-Treeインデックスでは、1つのインデックス・エントリが1つの行を指します。
対してBitmapインデックスでは、各インデックスキーに複数の行へのポインタが格納されます。 つまり、B-Treeインデックスでは、1つのインデックス・エントリが更新された時、1つの行をロックすれば済みます。
対してBitmapインデックスはその値を含む複数行をロックする必要があるので、OLTPシステムのように同時並行で多数の更新が入るような状況下ではパフォーマンス劣化やデッドロックの原因になることがあります。
Bitmapインデックスが必要になるような状況は次のようなケースです。
インデックス対象列のカーディナリティが低い。つまり、テーブルの行数に対する個別値の数が少ない。
インデックス対象テーブルが読み取り専用であるか、頻繁な変更が入らない。
例を見てみます。
sh.customers表にはcust_gender列があり、値はMとFの2つだけです。このテーブルに対して、特定の性別の顧客数をカウントするSQLが良く実行されるとします。
その場合、customers.cust_gender列にBitmapインデックスを張ると良いかもしれません。
BitmapインデックスのBitmapの各ビットは取りうるROWIDに対応します。ビットが設定されている場合は、対応するROWIDを持つ行にキー値が入っています。
マッピング関数がビット位置を実際のROWIDに変換するため、BitmapインデックスはB-Treeインデックスとは異なる内部表現を使用しますが、B-Treeインデックスと同じ機能を提供します。
単一行のインデックス付きの列が更新されると、データベースは、更新された行にマップされた個々のBitではなく、インデックス・キーエントリ(たとえば、MやF)をロックします。キーは多くの行を指しているので、インデックス付きデータのDMLは通常、これらすべての行をロックします。つまり更新時にロックする行数が多すぎるために性能劣化やデッドロックの原因になり得るので、BitmapインデックスはOLTPアプリケーションには適していないということになります。
単一テーブルのBitmapインデックスを見てみます。
SQL> select *
from
(
select cust_id, cust_last_name, cust_marital_status, cust_gender
from customers
order by cust_id
)
where rownum < 8; 2 3 4 5 6 7 8
CUST_ID CUST_LAST_NAME CUST_MARITAL_STATUS C
---------- ---------------------------------------- -------------------- -
1 Kessel M
2 Koch F
3 Emmerson M
4 Hardy M
5 Gowen M
6 Charles single F
7 Ingram single F
7 rows selected.cust_marital_status列とcust_gender列のカーディナリティは低いですが、cust_id列とcust_last_name列のカーディナリティは高いです。 このケースではcust_marital_status列とcust_gender列にBitmapインデックスを張るのが良いです。
それ以外の列についてはUniqueのB-Treeインデックスを張るのが良いです。
表2は前の例で示したcust_gender列のBitmapインデックスです。 性別ごとに1つずつ、2つの別々のBitmapになっています。

出典:Oracle® Database概要 12c リリース1 (12.1)
マッピング関数は、Bitmapの各ビットをcustomersテーブルのROWIDに変換します。
各ビット値は、テーブル内の対応する行の値によります。
例えば、M値のBitmapでは、customersテーブルの最初の行の性別がMであるため、最初のビットは1になります。 Bitmap cust_gender='M'では、テーブルの行2,6,7が’F'なので、対応するビットが0になります。
例えば、customers表で「女性のcustomerで独身、離婚している人は何人いるのか?」を調べようとした場合は次のようなSQLを発行します。
SQL> set lines 120
SQL> set timing on
SQL> set autotrace on
SQL> select count(*)
2 from customers
3 where cust_gender = 'F'
4* and cust_marital_status in ('single', 'divorced')
COUNT(*)
----------
6135
Elapsed: 00:00:00.00
Execution Plan
----------------------------------------------------------
Plan hash value: 2716255083
-------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 8 | 4 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 8 | | |
| 2 | BITMAP CONVERSION COUNT | | 3461 | 27688 | 4 (0)| 00:00:01 |
| 3 | BITMAP AND | | | | | |
| 4 | BITMAP OR | | | | | |
|* 5 | BITMAP INDEX SINGLE VALUE| CUSTOMERS_MARITAL_BIX | | | | |
|* 6 | BITMAP INDEX SINGLE VALUE| CUSTOMERS_MARITAL_BIX | | | | |
|* 7 | BITMAP INDEX SINGLE VALUE | CUSTOMERS_GENDER_BIX | | | | |
-------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - access("CUST_MARITAL_STATUS"='divorced')
6 - access("CUST_MARITAL_STATUS"='single')
7 - access("CUST_GENDER"='F')
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
9 consistent gets
0 physical reads
0 redo size
551 bytes sent via SQL*Net to client
466 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processedBitmapインデックスでは、表3のような結果のBitmap内の1の値をカウントすることによって、このクエリを効率的に処理できます。
SQLの条件にマッチする行を特定するために、Oracleは結果のBitmapを使用して表にアクセスします。

出典:Oracle® Database概要 12c リリース1 (12.1)
BitmapインデックスはWHERE句の複数の条件に対応するインデックスを効率的にマージします。
一部の条件を満たす行はテーブル本体にアクセスする前に除外されるので、応答時間が大幅に改善できる場合があります。
Bitmap結合インデックス
Bitmap結合インデックスは、2つ以上のテーブルを結合するためのBitmapインデックスです。
テーブル列の値ごとに、対応する行のROWIDをインデックスに格納します。
標準のBitmapインデックスは単一のテーブル列値に対して作成されます。
Bitmap結合インデックスは、事前に絞り込みを実行して、結合する必要のあるデータ量を減らします。
例えば、ユーザが特定の職種の従業員の数を問い合わせる場合次のようなSELECT文を実行します。
SELECT COUNT(*)
FROM employees, jobs
WHERE employees.job_id = jobs.job_id
AND jobs.job_title = 'Accountant';上記のSELECT文は、例えばjobs.job_titleのインデックスを使用してAccountantの行を取得し、employees.job_idのインデックスを使用して一致する行を検索します。
テーブルをスキャンするのではなく、インデックス自体からデータを取得するには、次のようにBitmap結合インデックスを作成します。
CREATE BITMAP INDEX employees_bm_idx
ON employees (jobs.job_title)
FROM employees, jobs
WHERE employees.job_id = jobs.job_id;次の図の通り、インデックス・キーはjobs.job_titleであり、インデックス付きテーブルはemployeesです。

出典:Oracle® Database概要 12c リリース1 (12.1)
概念的には、employees_bm_idxは、次のSELECT文のjobs.title列のインデックスです。
インデックスのjob_titleキーは、employeesテーブルの行を指します。
Accountantを数えるSELECT文を実行する場合、インデックス自体に必要な情報があるため、インデックスを使用すればemployeesテーブルとjobsテーブルへのアクセスを省略できます。
SELECT jobs.job_title AS "jobs.job_title", employees.rowid AS "employees.rowid"
FROM employees, jobs
WHERE employees.job_id = jobs.job_id
ORDER BY job_title;
jobs.job_title employees.rowid
----------------------------------- ------------------
Accountant AAAQNKAAFAAAABSAAL
Accountant AAAQNKAAFAAAABSAAN
Accountant AAAQNKAAFAAAABSAAM
Accountant AAAQNKAAFAAAABSAAJ
Accountant AAAQNKAAFAAAABSAAK
Accounting Manager AAAQNKAAFAAAABTAAH
Administration Assistant AAAQNKAAFAAAABTAAC
Administration Vice President AAAQNKAAFAAAABSAAC
Administration Vice President AAAQNKAAFAAAABSAAB
.
.
.Bitmap記憶域構造
Oracle Databaseは、B-Treeインデックス構造を使用して、インデックスキーのBitmapを格納します。
例えば、jobs.job_titleがBitmapインデックスのキー列である場合、インデックス・データは1つのB-Treeに格納されます。
個々のBitmapはリーフ・ブロックに保存されます。
jobs.job_title列に、Shipping Clerk、Stock Clerk、及びその他のいくつかの一意の値があるとします。
このインデックスのBitmapインデックス・エントリには次のコンポーネントがあります。
INDEXキーとしてのjob title
さまざまなROWIDの低ROWIDと高ROWID
範囲内の特定のROWIDのBitmap
概念的には、このINDEXのINDEXリーフブロックには、次のようなエントリが含まれます。
Shipping Clerk,AAAPzRAAFAAAABSABQ,AAAPzRAAFAAAABSABZ,0010000100
Shipping Clerk,AAAPzRAAFAAAABSABa,AAAPzRAAFAAAABSABh,010010
Stock Clerk,AAAPzRAAFAAAABSAAa,AAAPzRAAFAAAABSAAc,1001001100
Stock Clerk,AAAPzRAAFAAAABSAAd,AAAPzRAAFAAAABSAAt,0101001001
Stock Clerk,AAAPzRAAFAAAABSAAu,AAAPzRAAFAAAABSABz,100001
.
.
.例5 ビットマップ記憶域の例
出典:Oracle® Database概要 12c リリース1 (12.1)
ROWIDの範囲が異なるため、同じjob titleが複数のエントリに表示されます。
あるセッションにより、1人の従業員のjob IDがShipping ClerkからStock Clerkに更新されるとします。 この場合、このセッションで、古い値(Shipping Clerk)と新しい値(Stockc Clerk)のインデックス・キーエントリへの排他的アクセスが必要になります。 Oracle Databaseは、UPDATEがコミットされるまで、これら2つのエントリが指す行をロックしますが、Accountantなどそれ以外のキーが指す行はロックしません。
ハッシュ・インデックス
ハッシュ・インデックスの前提知識として表クラスタと索引付きクラスタを理解する必要があるので、まずこれらから見ていきます。
表クラスタ
表クラスタとは、別の表であっても列が共通していて、共通する列の同じ値のデータを同じブロックに格納する表のグループです。 例えば、employees表とdepartment表があってdepartment_id列が10、20、30、、、のような列値を持つ場合、department_id列が10のemployees表のデータとdepartment表のデータを同じブロックに格納します。 この時、department_idをクラスタ・キーと言います。 department_id=20などの値をクラスタ・キー値と言います。 通常の表ではdepartment_id=20などの値は対応する行が10行あれば10個の20が格納されますが、クラスタ・キー値の場合はその値を持つ行がいくつかの表に含まれているとしても、クラスタとクラスタ索引にそれぞれ一度のみ格納されます。
索引付きクラスタ
索引付きクラスタは、表クラスタに索引を付けたものです。 クラスタ索引は、クラスタ・キーのB-Tree索引のことです。 クラスタ索引は、クラスタ化表に行を挿入する前に作成しておく必要があります。
例を見てみます。
department_idという名前のクラスタ・キーを指定してクラスタemployees_departments_clusterを作成します。
CREATE CLUSTER employees_departments_cluster
(department_id NUMBER(4))
SIZE 512;
CREATE INDEX idx_emp_dept_cluster
ON CLUSTER employees_departments_cluster;employees_departments_clusterが索引付きクラスタになります。 この例では、クラスタ・キーdepartment_idにidx_emp_dept_clusterという名前の索引を作成しています。
索引付きクラスタを作成後、このクラスタにemployees表とdepartments表を作成し、クラスタ・キーとしてdepartment_id列を指定します。
CREATE TABLE employees ( ... )
CLUSTER employees_departments_cluster (department_id);
CREATE TABLE departments ( ... )
CLUSTER employees_departments_cluster (department_id);employees表とdepartments表に行を追加するとします。 データベースでは、employees表とdepartments表の各部門の行がすべて同じデータ・ブロックに格納されます。
図5はemployeesとdepartmentsを含むemployees_departments_cluster表クラスタです。 データベースでは、department_id=20であるemployees表の行department表の行がまとめて格納されます。

B-Treeクラスタ索引は、データを含むブロックのデータベース・ブロック・アドレス(DBA)にクラスタ・キー値を関連付けます。 たとえば、キー20の索引エントリには、部門20の従業員のデータを含むブロックのアドレスが表示されます。
20,AADAAAA9dクラスタ索引は、クラスタ化されていない表の索引と同様に個別に管理され、表クラスタとは別の表領域に存在することがあります。
ハッシュ・クラスタとハッシュ・インデックス
続いてハッシュ・クラスタとハッシュ・インデックスを見ていきます。
ハッシュ・クラスタは、索引付きクラスタの索引キーをハッシュ関数に置き換えたもので、この索引がハッシュ・インデックスです。 ハッシュ・クラスタを作成するときは、索引付きクラスタの場合と同じCREATE CLUSTER文を使用しますが、HASHKEYSを指定する必要があります。
クラスタ・キーは、索引付きクラスタのキーと同様に、単一の列、またはクラスタ内の表が共有するコンポジット・キーです。 ハッシュ・キー値は、クラスタ・キー列に挿入される値です。 例えば、クラスタ・キーがdepartment_idの場合は、ハッシュ・キー値が10、20、30のような値です。
Oracle Databaseでは、無数にあるハッシュ・キー値を入力として受け付け、限定された数のバケットに選別するハッシュ関数が使用されます。 各バケットにはハッシュ値という一意の数値IDが付与されます。 各ハッシュ値は、ハッシュ・キー値(department_id=10、20、30など)に対応する行の格納ブロックのデータベース・ブロック・アドレスにマップされます。
次の例では、存在すると推測される部門数が100であるため、HASHKEYSが100に設定されています。
CREATE CLUSTER employees_departments_cluster
(department_id NUMBER(4))
SIZE 8192 HASHKEYS 100;employees_departments_clusterの作成後、そのクラスタ内にemployees表とdepartments表を作成できます。
ハッシュ・クラスタの問合せで、ユーザーが入力するキー値をハッシュする方法は、データベースが決定します。 例えば、ユーザーが次のような問合せを頻繁に実行し、p_idに様々な部門ID番号を入力するとします。
SELECT *
FROM employees
WHERE department_id = :p_id;
SELECT *
FROM departments
WHERE department_id = :p_id;
SELECT *
FROM employees e, departments d
WHERE e.department_id = d.department_id
AND d.department_id = :p_id;ユーザーがdepartment_id=20のemployeesの行を検索した場合は、この値がバケット77にハッシュされます。 department_id=10のemployeesの行を検索した場合は、この値がバケット15にハッシュされます。 データベースは、内部的に生成されるハッシュ値を使用して、問合せ対象のdepartment_idに対応するemployeesの行を格納したブロックを検索します。
図6は、ハッシュ・クラスタ・セグメントを水平方向に並べたブロック行として示しています。 この図に示すように、1件の問合せにつき、1回のI/Oでデータを取得できます。
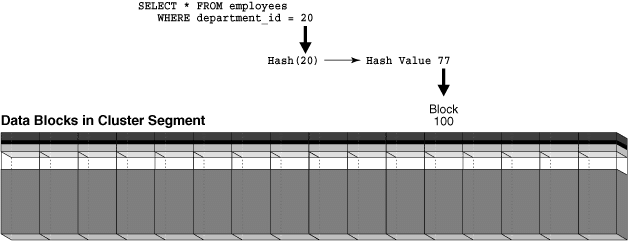
出典:Oracle® Database概要 12c リリース1 (12.1)
ハッシュ・クラスタの制限は、索引のないクラスタ・キーのレンジ・スキャンを使用できないことです。 department_idが20から100の検索は、20から100の間のすべての取り得る値をハッシュしていないため、ハッシュ・アルゴリズムを使用できません。 索引が存在しないため、データベースではテーブル・フルスキャンを実行する必要があります。
ハッシュ・クラスタの記憶域
Oracle Databaseは、ハッシュ・クラスタのための領域を索引付きクラスタとは異なる方法で割り当てます。
ハッシュ・クラスタの作成の時、HASHKEYSに存在する可能性のある部門数を指定し、SIZEに各部門に関連付けられたデータのサイズを指定しました。
CREATE CLUSTER employees_departments_cluster
(department_id NUMBER(4))
SIZE 8192 HASHKEYS 100;次の式に従って記憶域領域の値が計算されます。
HASHKEYS * SIZE / database_block_sizeもし、ブロック・サイズが8192バイトだとすると、ハッシュ・クラスタに100ブロックが割り当てられます。
Oracle Databaseでは、クラスタに挿入可能なハッシュ・キー値の数に制限はありません。 たとえば、HASHKEYSが100になっている場合でも、departments表に一意のdepartment_idを200個挿入することも可能です。 ただし、ハッシュ値の数がハッシュ・キーの数よりも多くなると、ハッシュ・クラスタ取得の効率が悪くなります。
取得の問題について、図6でブロック100がdepartment_id=20の行でまったく空きがない場合の例で説明します。

出典:Oracle® Database概要 12c リリース1 (12.1)
ユーザーがdepartment_id=43の新しい部署をdepartments表に挿入します。
部門の数がHASHKEYS値よりも大きいため、department_id=43はハッシュ値77にハッシュされますが、これは、department_id 20に使用されているハッシュ値と同じです。
複数の入力値を同じ出力値にハッシュすることをハッシュ衝突と呼びます。
ユーザーがdepartment_id=43のクラスタに行を挿入しようとしても、ブロック100はいっぱいであるため、行は格納されません。
ブロック100は新しいオーバーフロー・ブロック(ここではブロック200とします)にリンクされ、その新しいブロックに挿入行が格納されます。 つまり、ブロック100とブロック200の両方に、どちらの部門のデータも格納されている可能性があることになります。
図7に示すように、department_id=20またはdepartment_id=43を問い合せると、ブロック100とその関連ブロックであるブロック200からデータが取得されるため、I/Oが2回必要になります。
この問題を解決するには、HASHKEYS値を大きくしてクラスタを再作成する必要があります。

出典:Oracle® Database概要 12c リリース1 (12.1)
索引構成表
索引構成表は、B-Treeインデックスのストレージ構造に主キーのソート順で格納される表です。
対して、ヒープ構成表(単にCREATE TABLEで作成する表)では、主キーのソート順は特に意識せずに格納されます。
索引構成表では、行は表の主キーに定義された索引に格納されます。 B-Treeの各索引エントリには、非キー列値も格納されます。 アプリケーションは、ヒープ構成表と同じように、SQL文を使用して索引構成表を操作します。
索引構成表は、主キーまたはそのキーの有効な接頭辞の使用により、表の行に対するアクセスを高速化します。 リーフ・ブロックの行に非キー列が存在することにより、追加のデータ・ブロックI/Oが回避されます。 さらに、行が主キーの順序で格納されるため、主キーまたは接頭辞によるレンジ・アクセスでは最小限のブロックI/Oが行われます。 もう1つの利点は、個別の主キー索引の空間オーバーヘッドが回避されることです。
索引構成表は、関連したデータ断片をまとめて格納する必要がある場合や、データを特定の順序で物理的に格納する必要がある場合に役立ちます。 通常、このタイプの表は情報取得、空間データおよびOLAPアプリケーションに使用されます。
図8に索引構成表departmentsの構造を示します。 リーフ・ブロックには表の行が主キーの順序に従って格納されています。
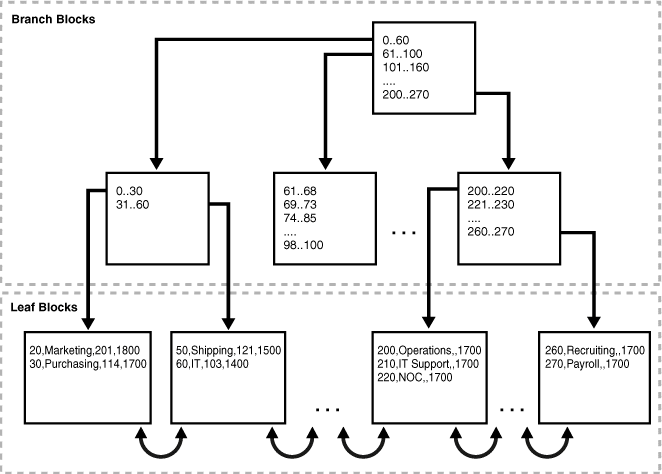
出典:Oracle® Database概要 12c リリース1 (12.1)
索引構成表では、すべてのデータが同じ構造に格納され、ROWIDを格納する必要がありません。
図8のように、索引構成表のリーフ・ブロック1には、主キーの順序に従った次のようなエントリが含まれます。
20,Marketing,201,1800
30,Purchasing,114,1700索引構成表のリーフ・ブロック2には次のようなエントリが含まれます。
50,Shipping,121,1500
60,IT,103,1400主キーの順序になっている索引構成表の行をスキャンすると、ブロックが次の順序で読み取られます。
ブロック1
ブロック2ヒープ構成表でのデータ・アクセスを索引構成表でのデータ・アクセスと比較するため、ヒープ構成表departmentsのセグメントのブロック1に、次のように行が格納されているとします。
50,Shipping,121,1500
20,Marketing,201,1800ブロック2には同じ表の行が次のように格納されています。
30,Purchasing,114,1700
60,IT,103,1400このヒープ構成表のBツリー索引リーフ・ブロックには、次のエントリが格納されています(最初の値は主キーであり、2つ目の値はROWIDです)。
20,AAAPeXAAFAAAAAyAAD
30,AAAPeXAAFAAAAAyAAA
50,AAAPeXAAFAAAAAyAAC
60,AAAPeXAAFAAAAAyAAB主キーの順序になっている表の行をスキャンすると、表セグメント・ブロックが次の順序で読み取られます。
ブロック1
ブロック2
ブロック1
ブロック2したがって、この例のブロックI/Oの数は、索引構成の例での数の倍になります。
逆キー・インデックス
逆キー・インデックスはB-Treeインデックスの一種であり、列の順序は保ちながら、各索引キーのバイトを物理的に逆にします。
例えば、索引キーが20であり、このキーに対して標準B-Treeインデックスで格納される16進数の2バイトがC1,15である場合、逆キー・インデックスでは、バイトが15,C1として格納されます。
例えば、orders表では、オーダーの主キーは順次キーです。
クラスタ内の1つのインスタンスがorder20を追加し、別のインスタンスがorder21を追加し、各インスタンスがインデックスの右側にある同じリーフ・ブロックにキーを書き込みます。
この問題は、複数のインスタンスが同じブロックを繰り返し変更するOracle Real Application Clusters(Oracle RAC)データベースでは特に深刻です。
この問題を軽減するには、複数のディスクにファイルを物理的にストライプ化できるディスクアーキテクチャにインデックス・テーブルスペースを格納する必要があります。
Oracleでは別の解決策として、逆キー・インデックスを提供しています。 逆キー・インデックスでは、バイト順を逆にすることにより、挿入が索引のすべてのリーフ・キー全体に分散されます。
例えば、標準キー・インデックスでは隣接する20や21などのキーは、逆キー・インデックス離れた別々のブロックに格納されます。
つまり、順次キーの挿入のためのI/Oは、より等分に分散されます。
索引のデータは格納されるときに列キーでソートされないため、逆キー配列を使用すると、場合によっては索引レンジ・スキャン問合せを実行できなくなります。
例えば、20より大きいオーダーIDを求める問合せを発行した場合、データベースではこのIDを含むブロックから開始できず、リーフ・ブロックが水平に処理されます。
ファンクション・インデックス
ファンクション・インデックスでは、1つ以上の列を含むファンクションや式の値が計算され、索引に格納されます。
ファンクション・インデックスはB-TreeインデックスまたはBitmapインデックスのいずれかです。
ファンクション・インデックスは、WHERE句にファンクションを含む文を効率的に評価します。
データベースでは、ファンクションが問合せに含まれている場合にのみ、ファンクション・インデックスを使用します。
ただし、INSERT文とUPDATE文の処理中には、データベースでは文を処理するために従来どおりファンクションを評価する必要があります。
例えば、次のようなファンクション・インデックスを作成したとします。
CREATE INDEX emp_total_sal_idx
ON employees (12 * salary * commission_pct, salary, commission_pct);データベースでは、次(部分的なサンプル出力を示しています)に示すような問合せを処理するときに、この索引を使用できます。
SELECT employee_id, last_name, first_name,
12*salary*commission_pct AS "ANNUAL SAL"
FROM employees
WHERE (12 * salary * commission_pct) < 30000
ORDER BY "ANNUAL SAL" DESC;
EMPLOYEE_ID LAST_NAME FIRST_NAME ANNUAL SAL
----------- ------------------------- -------------------- ----------
159 Smith Lindsey 28800
151 Bernstein David 28500
152 Hall Peter 27000
160 Doran Louise 27000
175 Hutton Alyssa 26400
149 Zlotkey Eleni 25200
169 Bloom Harrison 24000別の例を見てみます。
SQLファンクションUPPER(column_name)またはLOWER(column_name)でファンクション・インデックスを定義すると、大文字/小文字を区別しない検索が容易になります。
例えば、employeesのfirst_name列に大文字/小文字が含まれるとします。 hr.employees表に次のようなファンクション索引を作成します。
CREATE INDEX emp_fname_uppercase_idx
ON employees ( UPPER(first_name) ); emp_fname_uppercase_idxインデックスによって、次のような問合せが容易になります。
SELECT *
FROM employees
WHERE UPPER(first_name) = 'AUDREY';オプティマイザがファンクション・インデックスを使うことができるようにするためにはQUERY_REWRITE_ENABLED初期化パラメータをTRUEにセットする必要があります。
パーティション・インデックス
Oracleデータベースでは、パーティション化により、大規模な表や索引をパーティションという、より小さく管理しやすい部分に分割できます。
アプリケーションから見ると、スキーマ・オブジェクトは1つのみ存在します。 パーティション表にアクセスするためにSQL文を修正する必要はありません。
パーティション化は様々なタイプのデータベース・アプリケーションで有効ですが、特に大量のデータを管理するアプリケーションで便利です。
パーティション・キーは、パーティション表の各行が属するパーティションを決定する1つ以上の列のセットです。
各行は、単一パーティションに明示的に割り当てられます。
レンジ・パーティション
次のような表をパーティション化する例を見てみます。
PROD_ID CUST_ID TIME_ID CHANNEL_ID PROMO_ID QUANTITY_SOLD AMOUNT_SOLD
---------- ---------- --------- ---------- ---------- ------------- -----------
116 11393 05-JUN-99 2 999 1 12.18
40 100530 30-NOV-98 9 33 1 44.99
118 133 06-JUN-01 2 999 1 17.12
133 9450 01-DEC-00 2 999 1 31.28
36 4523 27-JAN-99 3 999 1 53.89
125 9417 04-FEB-98 3 999 1 16.86
30 170 23-FEB-01 2 999 1 8.8
24 11899 26-JUN-99 4 999 1 43.04
35 2606 17-FEB-00 3 999 1 54.94
45 9491 28-AUG-98 4 350 1 47.45 例9 パーティション表のサンプル行セット
出典:Oracle® Database概要 12c リリース1 (12.1)
レンジ・パーティション化では、Oracle Databaseはパーティション化キーの値の範囲に基づいて、行をパーティションにマップします。 レンジ・パーティション化は、最も一般的なタイプのパーティション化であり、通常は日付とともに使用されます。
time_id列をパーティション・キーとして指定して次のSQL文を使用して、time_range_salesをパーティション表として作成します。
CREATE TABLE time_range_sales
( prod_id NUMBER(6)
, cust_id NUMBER
, time_id DATE
, channel_id CHAR(1)
, promo_id NUMBER(6)
, quantity_sold NUMBER(3)
, amount_sold NUMBER(10,2)
)
PARTITION BY RANGE (time_id)
(PARTITION SALES_1998 VALUES LESS THAN (TO_DATE('01-JAN-1999','DD-MON-YYYY')),
PARTITION SALES_1999 VALUES LESS THAN (TO_DATE('01-JAN-2000','DD-MON-YYYY')),
PARTITION SALES_2000 VALUES LESS THAN (TO_DATE('01-JAN-2001','DD-MON-YYYY')),
PARTITION SALES_2001 VALUES LESS THAN (MAXVALUE)
); 図10がレンジ・パーティションのイメージです。
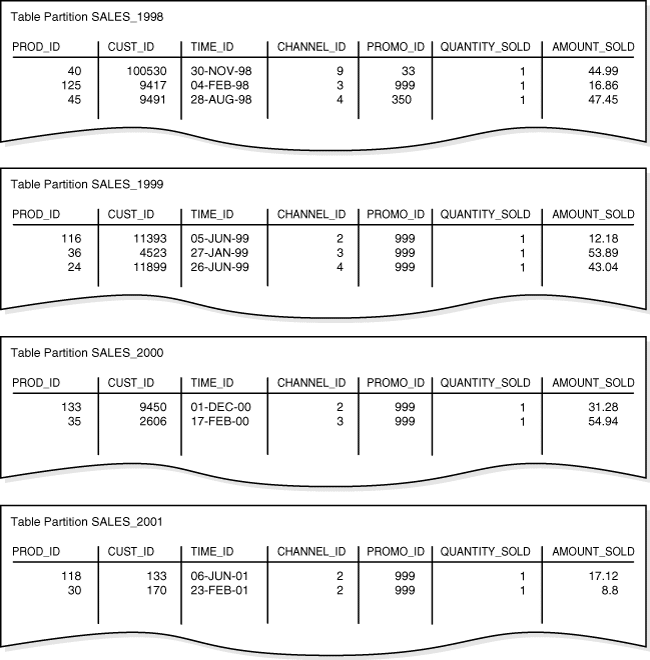
出典:Oracle® Database概要 12c リリース1 (12.1)
リスト・パーティション
リスト・パーティション化では、各パーティションのパーティション・キーとして離散値のリストを使用します。
channel_id列がパーティション・キーである次の文を使用して、リスト・パーティション表としてlist_salesを作成するとします。
CREATE TABLE list_sales
( prod_id NUMBER(6)
, cust_id NUMBER
, time_id DATE
, channel_id CHAR(1)
, promo_id NUMBER(6)
, quantity_sold NUMBER(3)
, amount_sold NUMBER(10,2)
)
PARTITION BY LIST (channel_id)
( PARTITION even_channels VALUES ('2','4'),
PARTITION odd_channels VALUES ('3','9')
); 図11がリスト・パーティションのイメージです。

出典:Oracle® Database概要 12c リリース1 (12.1)
ハッシュ・パーティション
ハッシュ・パーティション化では、ユーザー指定のパーティション・キーに適用するハッシング・アルゴリズムに基づいて、行をパーティションにマップします。
prod_id列をパーティション・キーとして指定して次の文を使用して、パーティション化されたhash_sales表を作成するとします。
CREATE TABLE hash_sales
( prod_id NUMBER(6)
, cust_id NUMBER
, time_id DATE
, channel_id CHAR(1)
, promo_id NUMBER(6)
, quantity_sold NUMBER(3)
, amount_sold NUMBER(10,2)
)
PARTITION BY HASH (prod_id)
PARTITIONS 2; 図12がハッシュ・パーティションのイメージです。
パーティションの名前は、システムによって生成されます。
データベースはハッシュ関数を適用し、関数の出力結果に基づいて、どのパーティションに行を格納するかを決定します。

出典:Oracle® Database概要 12c リリース1 (12.1)
パーティション・インデックス
パーティション・インデックスは、パーティション表のように、より小さく管理しやすい単位に分割されたインデックスです。
次の図に、索引パーティション化のオプションを示します。
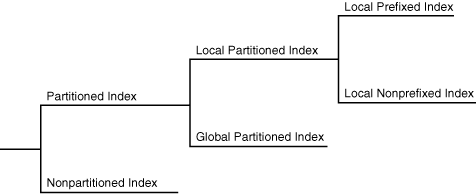
出典:Oracle® Database概要 12c リリース1 (12.1)
ローカル・パーティション・インデックス
ローカル・パーティション・インデックスでは、その表と同じパーティション数および同じパーティション境界で、同じ列に対してインデックスがパーティション化されます。
インデックス・パーティションにあるすべてのキーが単一の表パーティションに格納された行のみを参照するように、各インデックス・パーティションは、ベースとなる表のパーティションと1対1で関連付けられます。
この方法で、データベースはインデックス・パーティションと関連する表パーティションを自動的に同期化し、表とインデックスの各ペアを独立させます。
次の例では、hash_sales表のtime_id列にローカル・パーティション・インデックスを作成します。
CREATE INDEX hash_sales_idx ON hash_sales(time_id) LOCAL;図14では、hash_products表に2つのパーティションがあり、そのため、hash_sales_idxにも2つのパーティションがあります。 各インデックス・パーティションは異なる表パーティションに関連付けられています。 インデックス・パーティションSYS_P38は表パーティションSYS_P33の行をインデックス付けするのに対し、インデックス・パーティションSYS_P39は表パーティションSYS_P34の行をインデックス付けします。
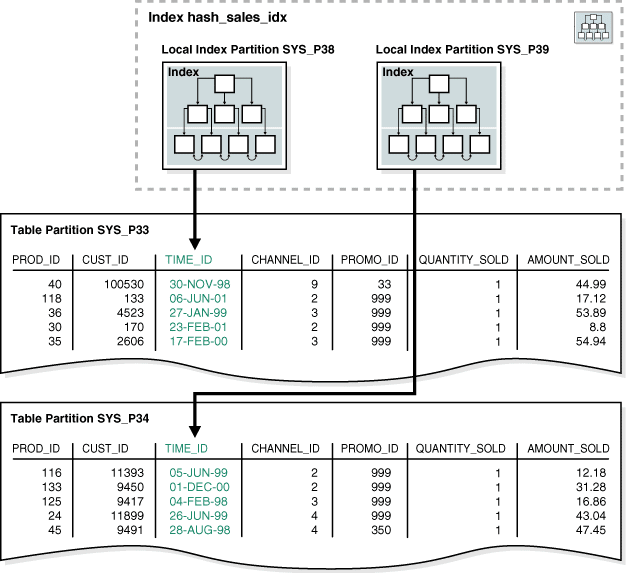
出典:Oracle® Database概要 12c リリース1 (12.1)
グローバル・パーティション・インデックス
グローバル・パーティション・インデックスは、インデックスのベース表とは別にパーティション化されたB-Treeインデックスです。
一つのインデックス・パーティションは、複数の表パーティションを指す場合があります。
対してローカル・パーティション・インデックスでは、インデックス・パーティションと表パーティションが1対1で関連付けられていました。
次の例では、time_range_sales表のchannel_id列の範囲別にパーティション化されたグローバル・インデックスを作成します。
CREATE INDEX time_channel_sales_idx ON time_range_sales (channel_id)
GLOBAL PARTITION BY RANGE (channel_id)
(PARTITION p1 VALUES LESS THAN (3),
PARTITION p2 VALUES LESS THAN (4),
PARTITION p3 VALUES LESS THAN (MAXVALUE));図15の通り、グローバル・インデックス・パーティションには、複数の表パーティションを指すエントリを含めることができます。 インデックス・パーティションp1はchannel_idが2の行を指し、インデックス・パーティションp2はchannel_idが3の行を指し、インデックス・パーティションp3はchannel_idが4または9の行を指しています。
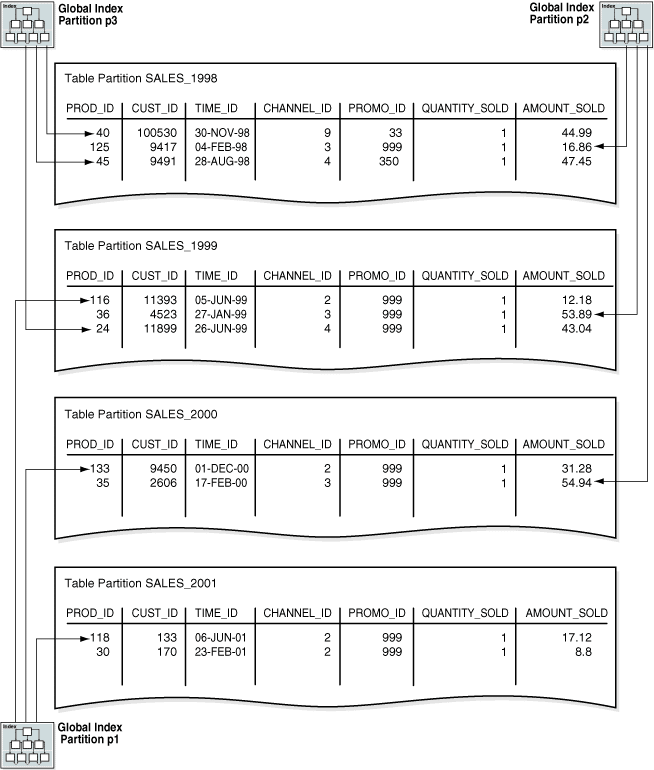
出典:Oracle® Database概要 12c リリース1 (12.1)
【このSHIFT公式ブロガーの最新記事】
執筆者プロフィール:小澤 雅弘
DBMSベンダー、ISPなどでDB関連のプロジェクトを20数年経験。得意領域はDBのパフォーマンスチューニング。
お問合せはお気軽に
https://service.shiftinc.jp/contact/
SHIFTについて(コーポレートサイト)
https://www.shiftinc.jp/
SHIFTのサービスについて(サービスサイト)
https://service.shiftinc.jp/
SHIFTの導入事例
https://service.shiftinc.jp/case/
お役立ち資料はこちら
https://service.shiftinc.jp/resources/
SHIFTの採用情報はこちら
https://recruit.shiftinc.jp/career/