

Proxmox VEでCephを使ったクラスタ環境を作ってみた

はじめに
こんにちは。
株式会社SHIFTのITソリューション部アプリケーションサービスG尾﨑です。
前回、「VMware ESXiからProxmox VEへのマイグレーションしてみた」 でVMWare ESXiの仮想マシンを、Proxmox VEへマイグレーションしてみましたが、今回は、Proxmox VEのクラスタ環境を作成してみました。「クラスタ環境を構築すると何が出来るのか」が、日本語で整理されたサイトをあまり見かけないので、作成してみました。みなさんの参考になれば幸いです。
1.クラスタ環境を構成すると何ができるのか
Proxmox VEのクラスタを構成すると、以下の方法で可用性を高める事ができます。
1)Cephによる分散オブジェクトストレージを使った冗長化構成
Proxmox VEのクラスタは、複数のノードを使った稼働(Active)/待機(Standby)方式による冗長化構成が前提である、可用性を高めたHA(High Availability:高可用性)構成を使用できます。 HAが構成されたクラスタ環境では、優先順位を高く設定したノードで仮想マシンが稼働(Active)し、その他サーバ上のノードが待機(Standby)します。
Proxmox VEにおいてはCeph(※)でHAを構成します。待機ノードに対しては、常に稼働ノード上の仮想マシン・データをコピーしているため、仮想マシンの稼働ノードに異常が発生した場合には、自動的に優先順位が一番高い待機ノード上で、仮想マシンが立ち上がります。この動作をフェールオーバーと言います。 なお、Cephを使用する場合には、3つ以上のノードが必要です。なぜなら、Cephを使ったクラスタとは、ノード同士で行われるマスターなしの構成だからです。どれかのノード状態に差異が発生したときには、多数決によって状態の復旧を行います。よって、2ノードのみの場合には、どちらが正しいのか分からないので、最低でも3ノードが必要になります。
フェールオーバの紹介は8章で行います。
Proxmox VEにおけるCephの欠点は、ノード障害時に障害ノードを回復しないでいると、Cephのヘルスチェックモニターが正しく機能しなくなる事です。 Cephヘルスチェックモニターを正常状態に戻すためには、早くノード障害を回復する必要がありますが、障害ノードの修理に時間がかかる場合に問題となります。また、正常動作中のノード上から障害ノード情報をいったん消して、正常状態に戻した後に障害ノードを再度参加させるといったことも簡単には出来ないのが厄介です。 なお、このCephのヘルスチェックモニタ障害は、障害発生時のノード数が2つになるため発生しているのかもしれません。しかし4台以上のノード構成がある場合に、ノード障害時のCephのヘルスチェックモニターが、エラーになるのか・ならないのか、未確認です。今後検証します。
(※)Cephは、2004年以前からカリフォルニア大学サンタクルーズ校(UCSC)で開発され、2006年にオープンソース化された、分散オブジェクトストレージソフトウェアです。
2)ZFSストレージのレプリケーション機能を使った冗長化構成
クラスタが前提となる可用性を高めた冗長化構成の別なアプローチとして、ZFSストレージの場合には、ZFSストレージのレプリケーション機能により、仮想マシンのボリュームを別のノードに複製する方法があります。この際、設定により、異なるノードへ複製を簡単に出来ますし、複数ノードにも仮想マシンを複製して冗長化することができます。
ZFSストレージのレプリケーション機能では、スナップショットを使用し、最初の完全同期後には増分のみネットワーク経由で送信するため、トラフィック負荷を最小限に抑える事が出来ます。運用中の稼働ノードに障害が発生した場合でも、仮想マシンを複製したノードを引き続き利用ができます。この方法は、最低2つのノードで運用できるので、費用対効果が高いです。
欠点は、リアルタイム性に欠け、障害時発生時に起動した仮想マシンには、前回レプリケーションから現在までの間の情報が欠損しているため、リアルタイム性があまり必要では無い場合に有効ということです。ただし、外部サーバにリアルタイム更新の頻度が高いデータを置くことで、この欠点をカバーすることが出来ます。
ZFSストレージのレプリケーション機能を使った方法は、次回の記事で紹介予定です。
3)マイグレート
冗長化のよる可用性には使えませんが、クラスタが前提である可用性を高める別の方法が「マイグレート」です。
マイグレートは、ノード上の仮想マシンを、別のノード上に移動させる方法です。画面上の「マイグレート」ボタン押下により、簡単に移動できます。 ハードウエアの運用保守などのため、仮想マシンが稼働しているサーバを停止したいが、停止中にも仮想マシンを使いたい場合、「マイグレート」でノード移動すれば可能になります。 ZFS以外のローカルストレージを使っている場合でも、最低2つのノードで実現ができるので、費用対効果が高いです。
なお、Cephを使っている場合には、動作中の仮想マシンを、稼働中のまま移動させる「ライブマイグレーション」が利用出来ます。
「ライブマイグレーション」の紹介は5章で行います。
2.必要要件
ハードウェア要件
クラスタに参加している各ノードは、同じ構成である事が必要です。その際、CPUのコア数、メモリ容量およびストレージの構成と容量が、すべて同じである必要があります。 仮想マシンを別ノードに移動させて起動しても、ノード構成が同じでない場合には、仮想マシンが正しく起動しない可能性があります。
また、Cephの分散オブジェクトストレージを使用する場合、OS用の物理ディスク領域/デバイスとは別に、OSDストレージ領域用の物理ディスク領域/デバイスが必要になります。 この領域に仮想マシンを格納し、ネットワークを使った同期更新を行うため、高速なストレージが必要になります。 OSDストレージには、仮想マシンに必要なディスク容量を確保してください。
ネットワーク要件
Cephによる分散オブジェクトストレージを使う場合には、データ同期のための専用ネットワークポートを準備した方が良いです。もし、同期通信用の専用ネットワークポートを準備しない場合には、同期通信によるパフォーマンス劣化が懸念されます。
なお、10GLAN回線が利用できる場合には、ネットワークポートが1つであっても、同期通信によるパフォーマンス劣化を減らすことが出来ます。
名前解決要件
各ノードの名前がIPアドレスから参照できること、およびその逆が出来るようにDNSに登録するか、HOSTSファイルに記載を行います。必ず名前解決が出来ることを確認をしてから、クラスタの設定を行うようにしてください。
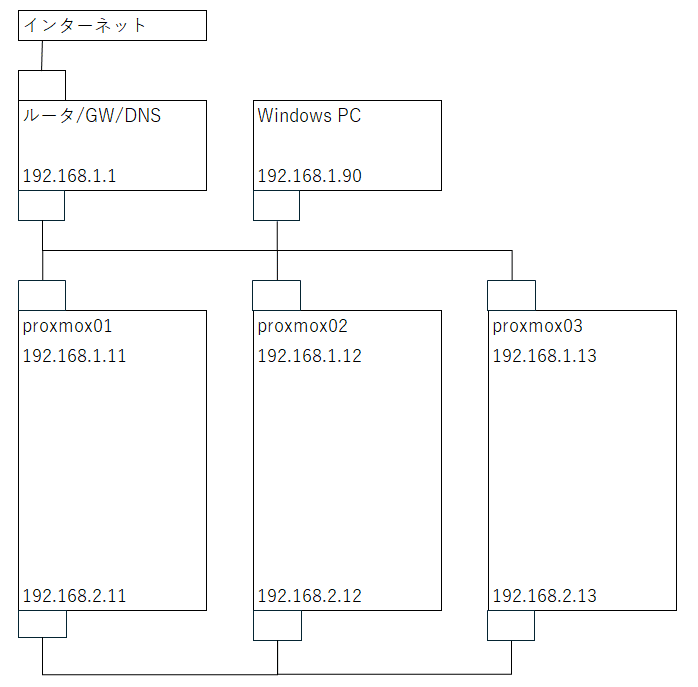
3.HA設定前の状態
以下に、クラスタ構成の設定前状態を示します。
Proxmox VEの導入・操作および仮想マシンの作成・操作は、「192.168.1.90」の「Windows PC」より行います。
4.クラスタ作成
以下に、ノードがクラスタへ参加する際の手順を示します。
1)proxmon01でクラスタを作成する。
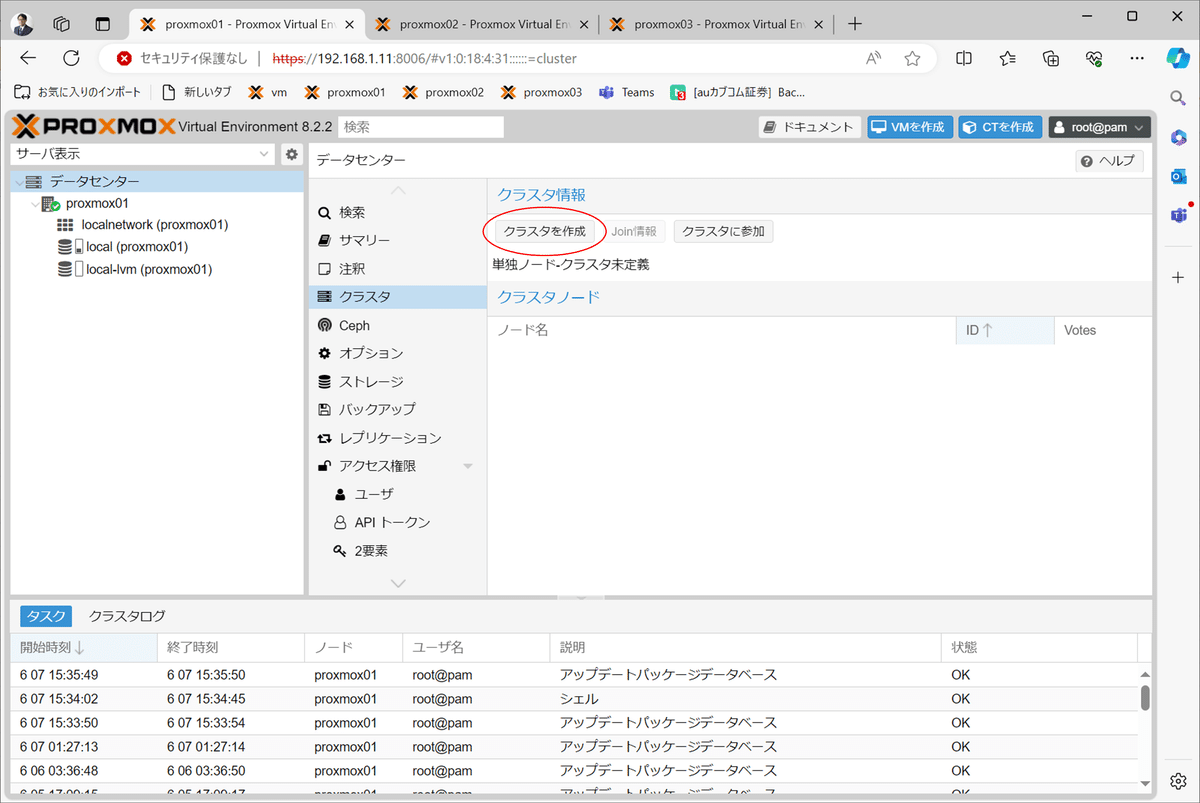
2)バックエンド側のネットワークを指定して作成する。

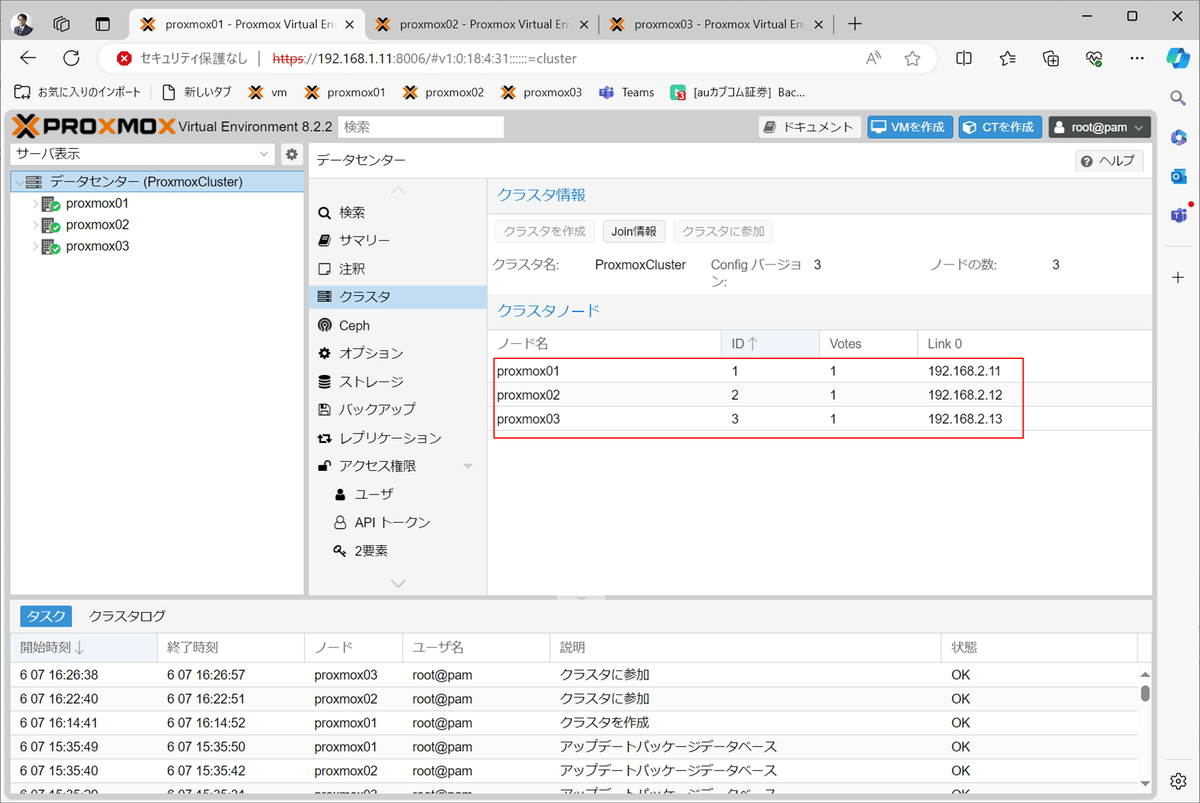
3)クラスタの作成完了を確認する。

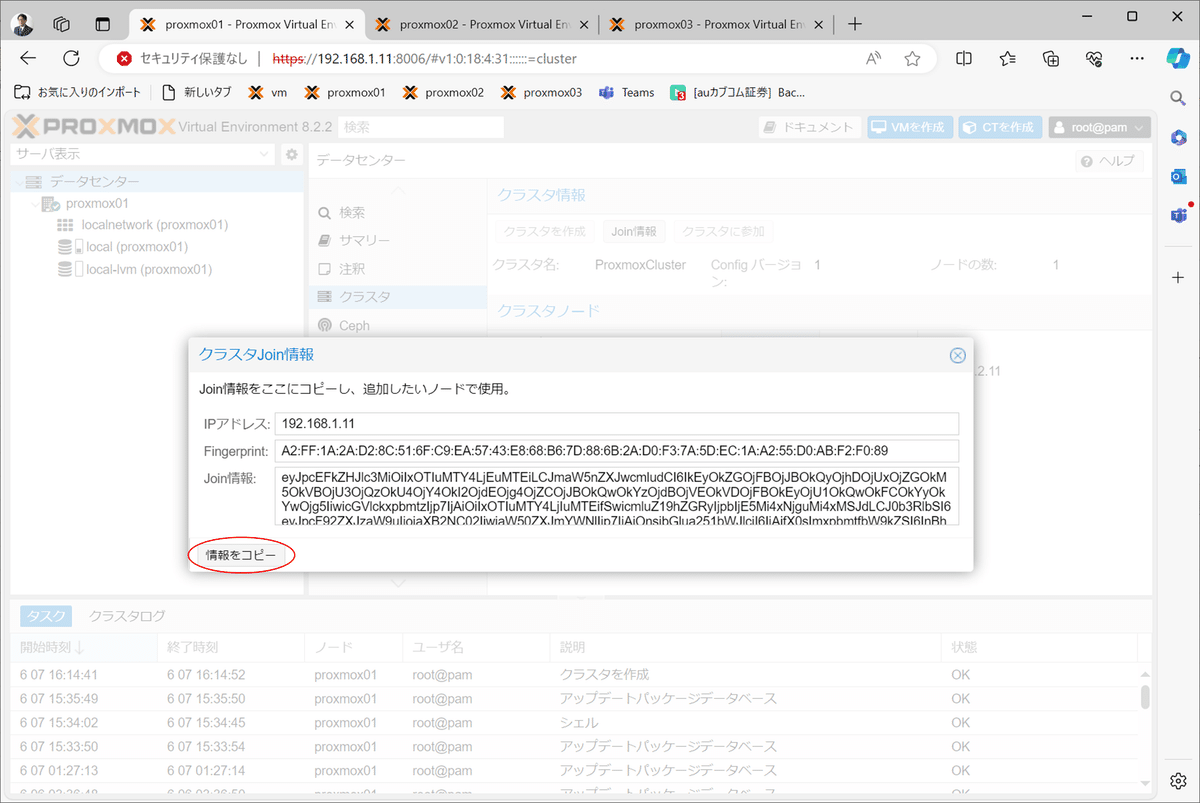
4)クラスタへのJoin情報を表示する。

5)クラスタへのJoin情報をコピーする。
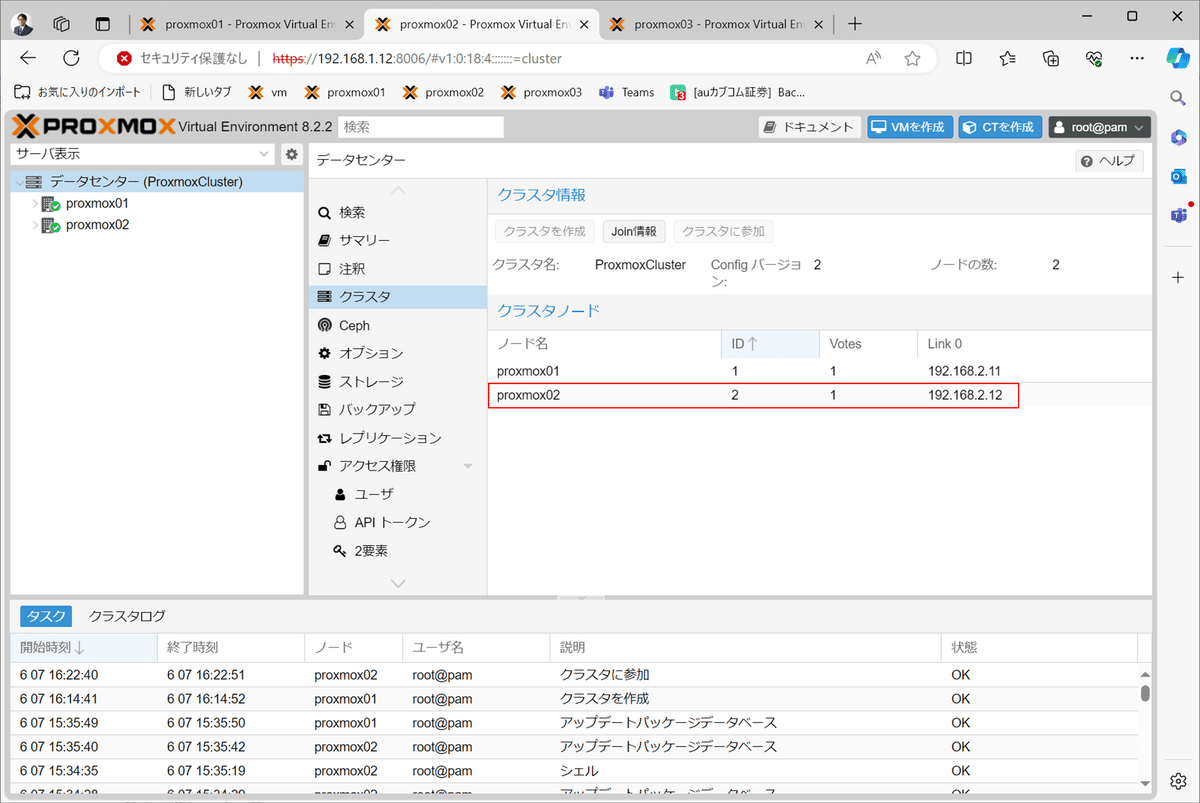
6)proxmox2をクラスタに追加する。

7)クラスタへの参加情報を入力する。

8)クラスタ参加後に、画面が固まるので、proxmon02にログインし直すと、proxmon02がクラスタに参加していることが分かる。
9)proxmox03も同様にクラスタへ参加したのち、状況を確認する。
5.Cephによる分散オブジェクトストレージ設定
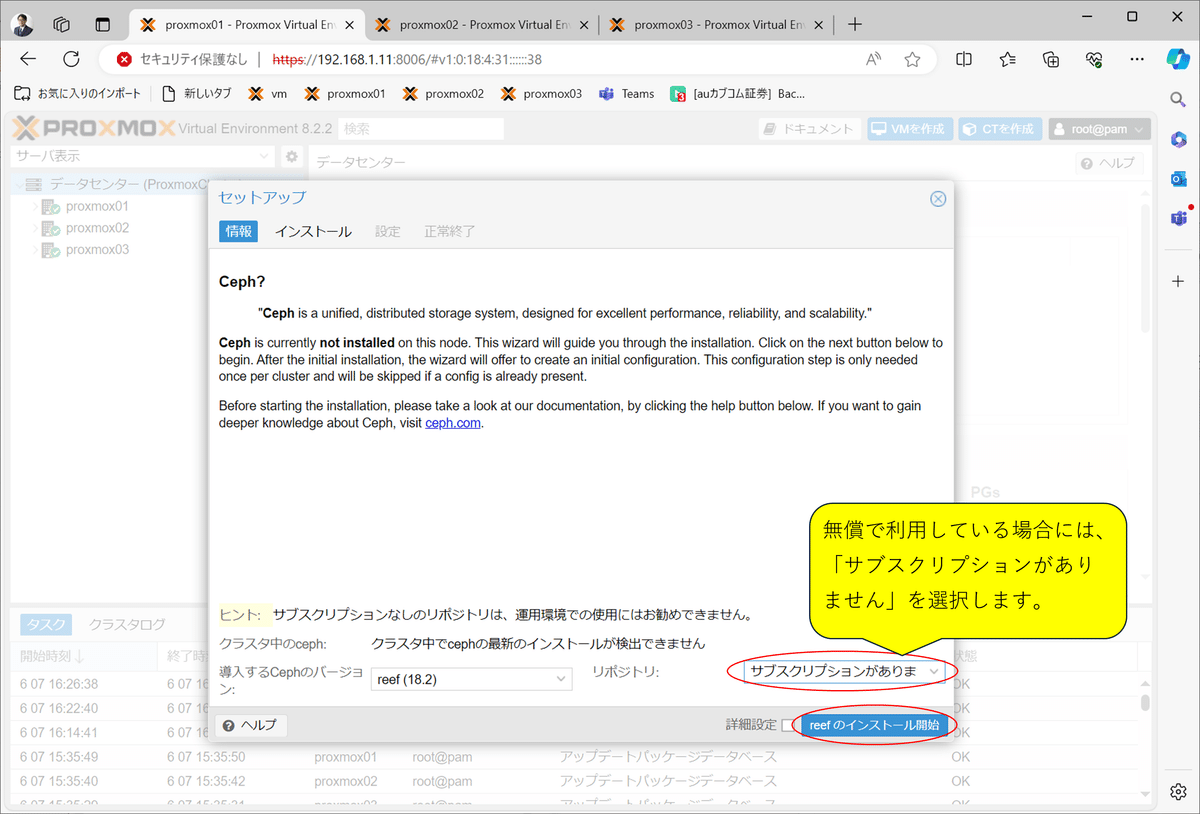
1)Cephコンポーネント・インストール
以下の手順でCephコンポーネントをインストールします。
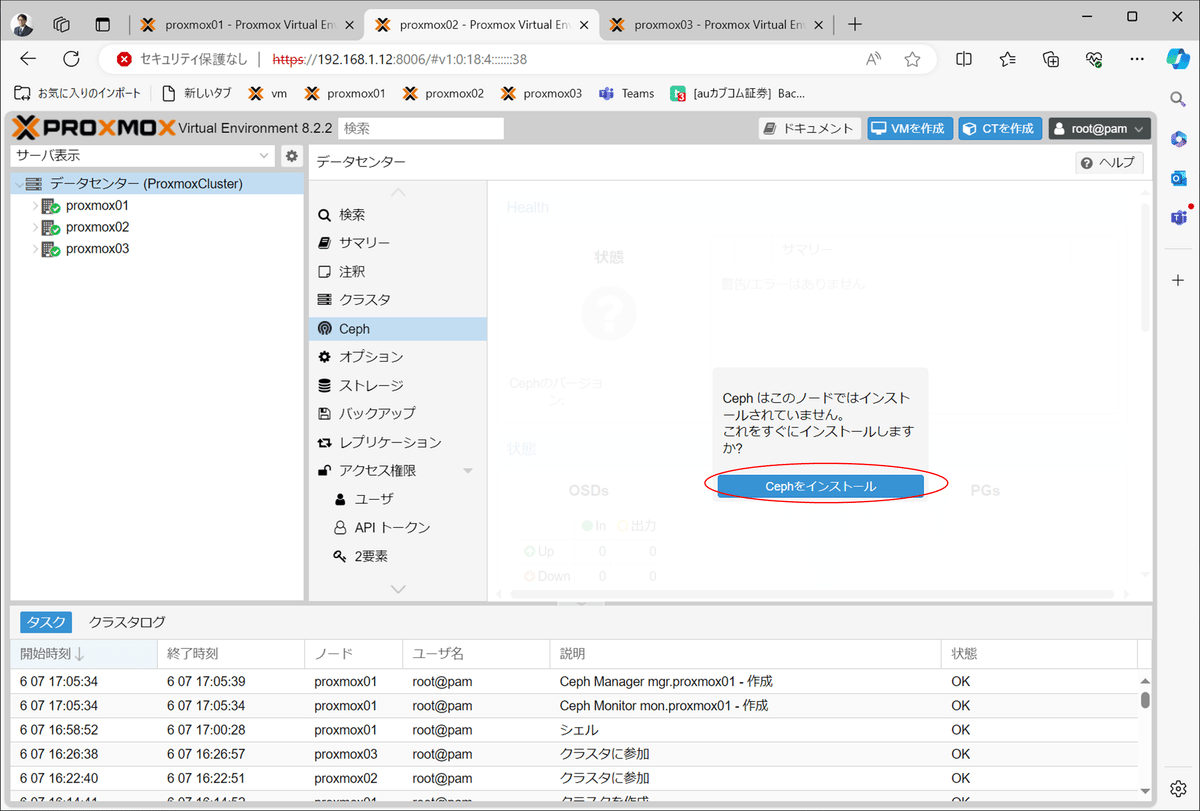
Cephインストールを選択

リポジトリ変更とインストール開始
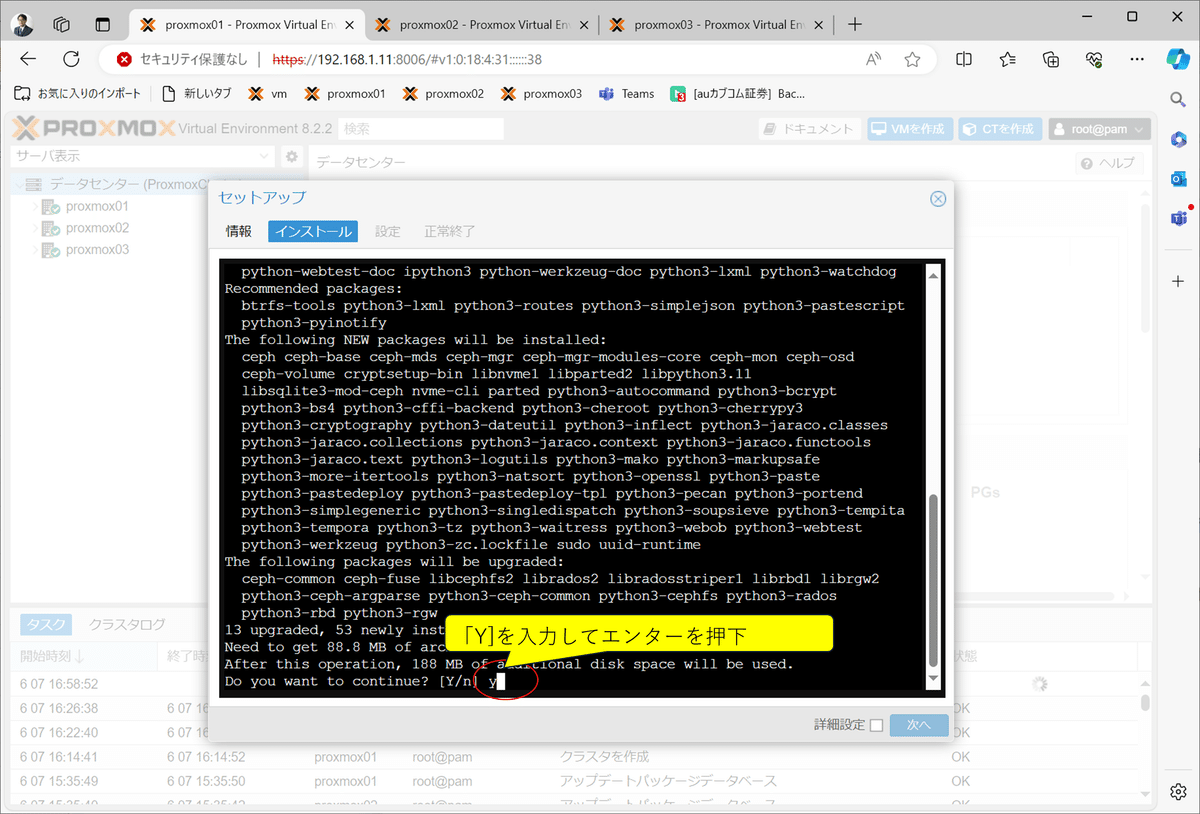
コンポーネント・インストールの了解
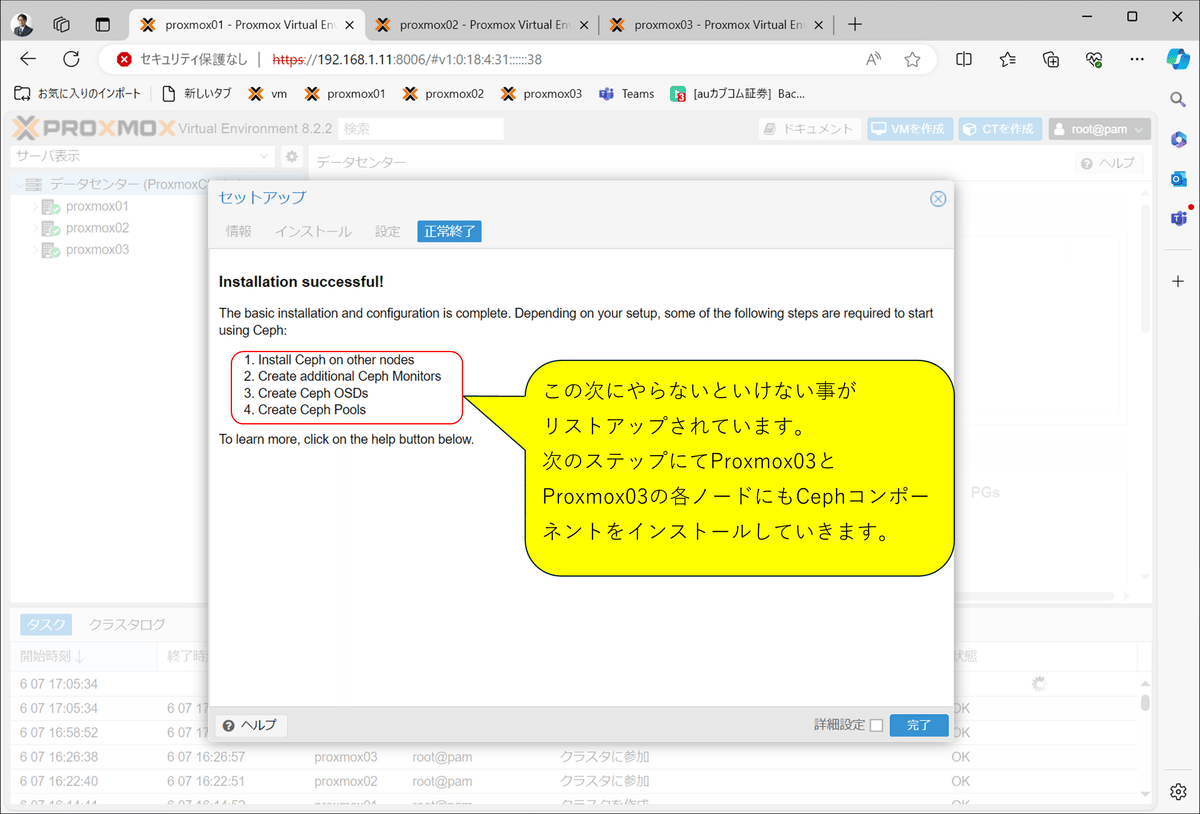
コンポーネント・インストール完了

ネットワークセグメント指定

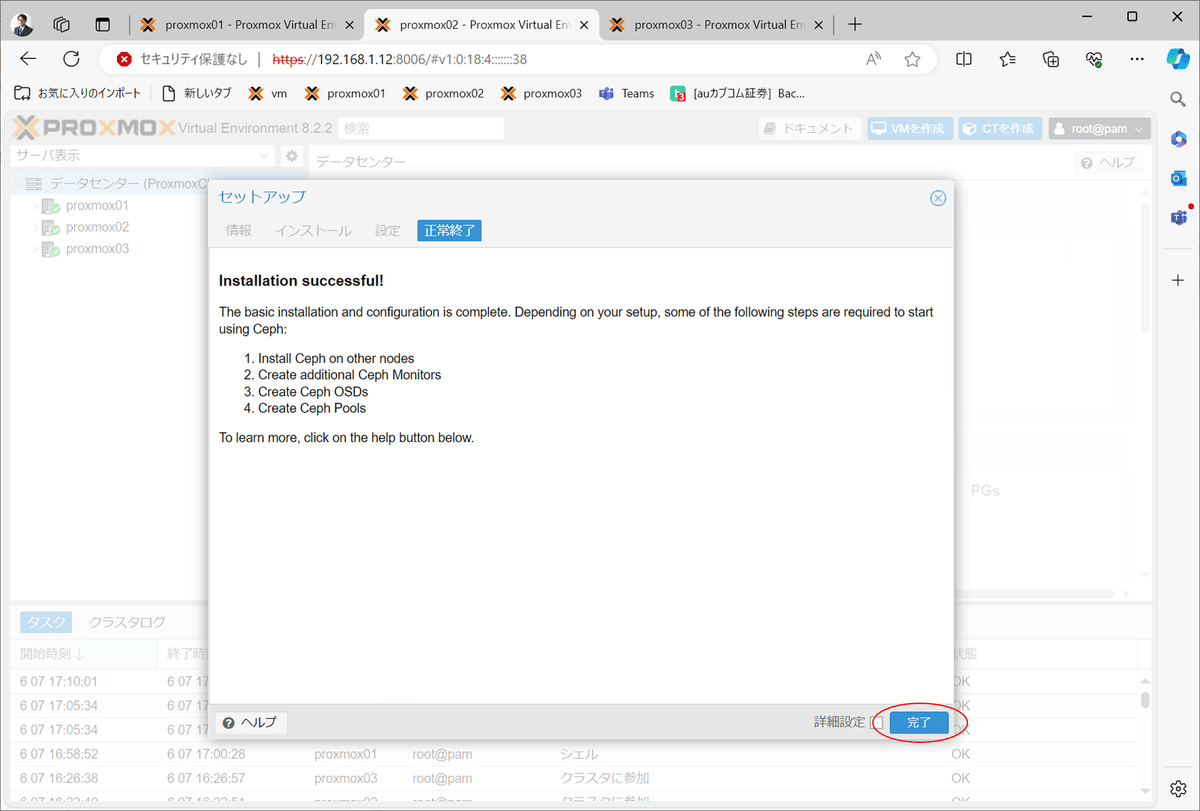
インストール完了
proxmox02ノードへのインストール開始
リポジトリ変更とインストール開始

ネットワーク設定をスキップ

インストール完了
proxmox03 ノードへの追加
上記のproxmox02ノードへのインストールと同様に、proxmox03ノードにCaphをインストールします。
2)OSDストレージの作成
仮想マシンを物理的に格納するOSDストレージを、各ノード毎に作成します。
「Ceph」メニューの「OSD」から「作成 OSD」を押下

OSDストレージ用に準備しておいた物理ディスクのデバイスを指定して作成

追加したOSDストレージを一覧で確認

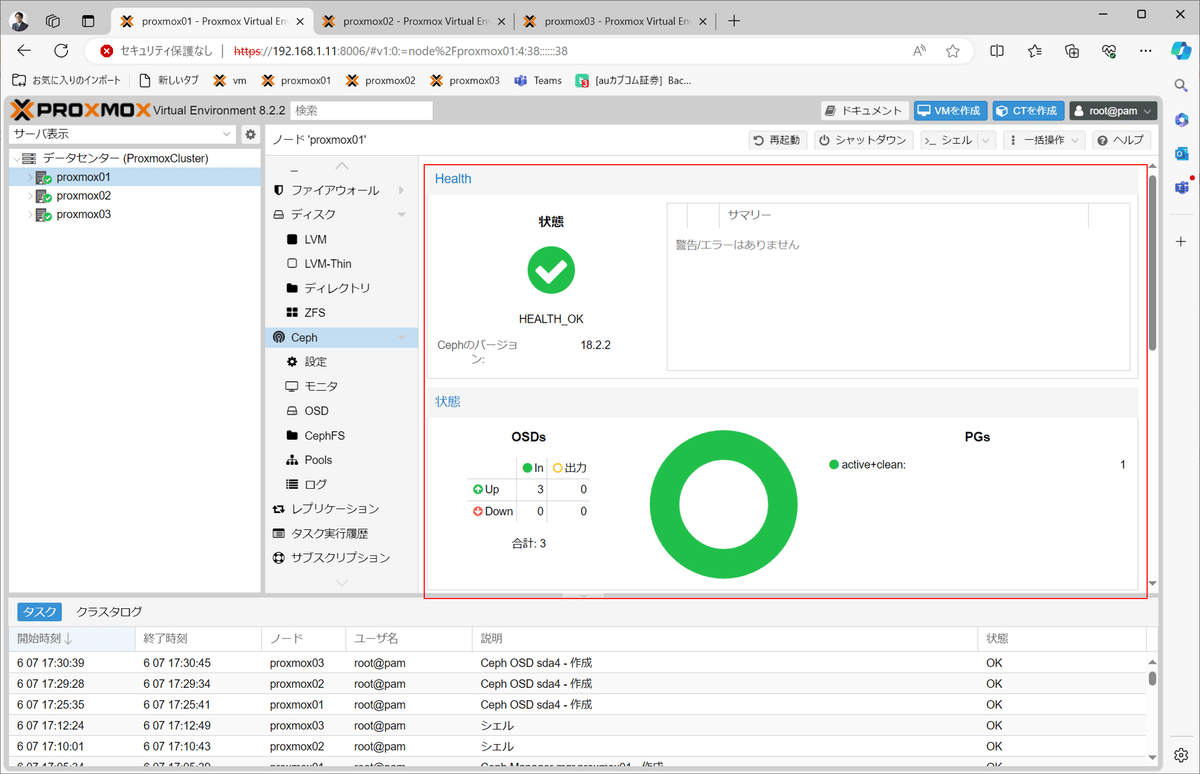
同様にproxmox02とproxmox03にもOSDストレージを追加後に確認

OSDストレージを追加すると、今までエラー表示だったCephヘルスチェックモニタが正常化
3)Poolの作成
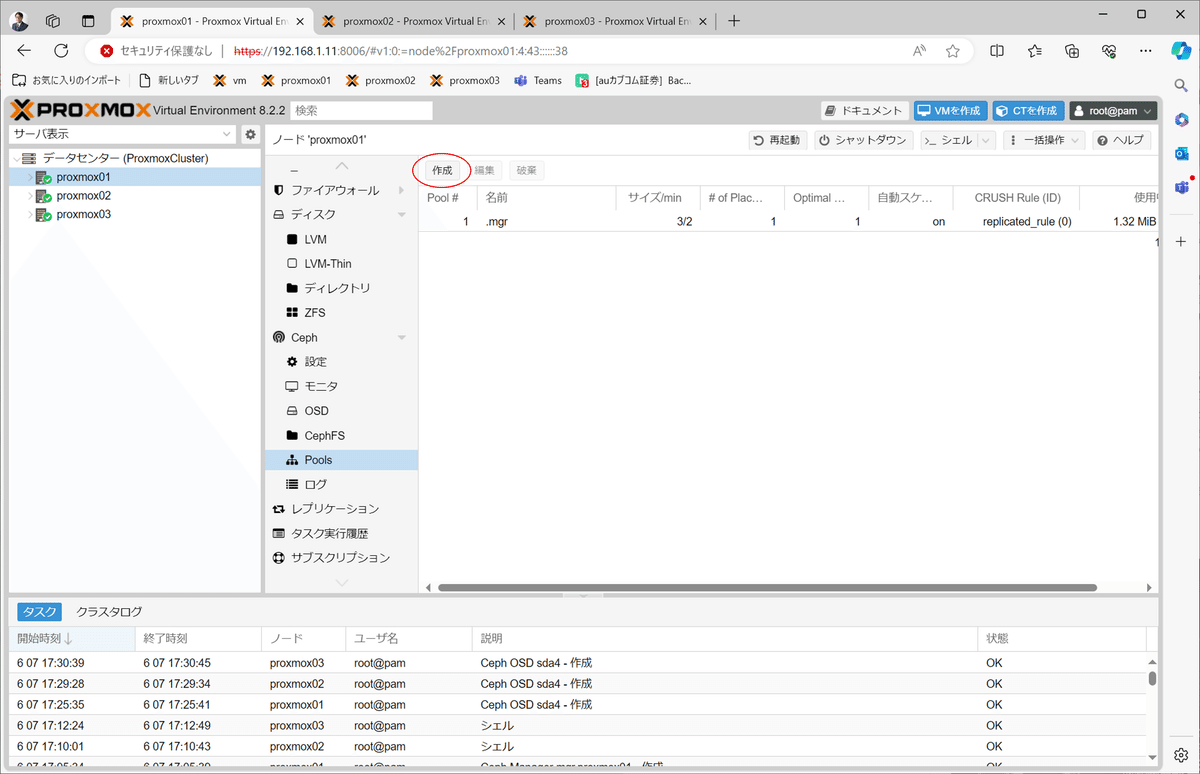
OSDストレージを各ノード間で同期する時に使用するPoolを作成します。
仮想マシンを作成する際に指定する保存先は、このPoolになります。
OSD Pool作成を開始
OSD Poolに名前を付けて作成

全てのノードにOSD Poolがあることを確認

4)モニターの追加
ノード障害を監視するためのモニターを登録します。 proxmox01はモニター登録済みのため、proxmox02とproxmox03を追加します。
proxmox02を追加開始

proxmox02を追加

結果の確認

同様にproxmox03も追加した後に確認

5)OSD Poolを利用する仮想マシンの作成
仮想マシンの作成方法は通常と変わらないので省略します。ポイントとなるのは、以下の図の通り、ストレージにOSD Poolを指定している部分です。

proxmox01上に「Linux01」という仮想マシンを作りました。
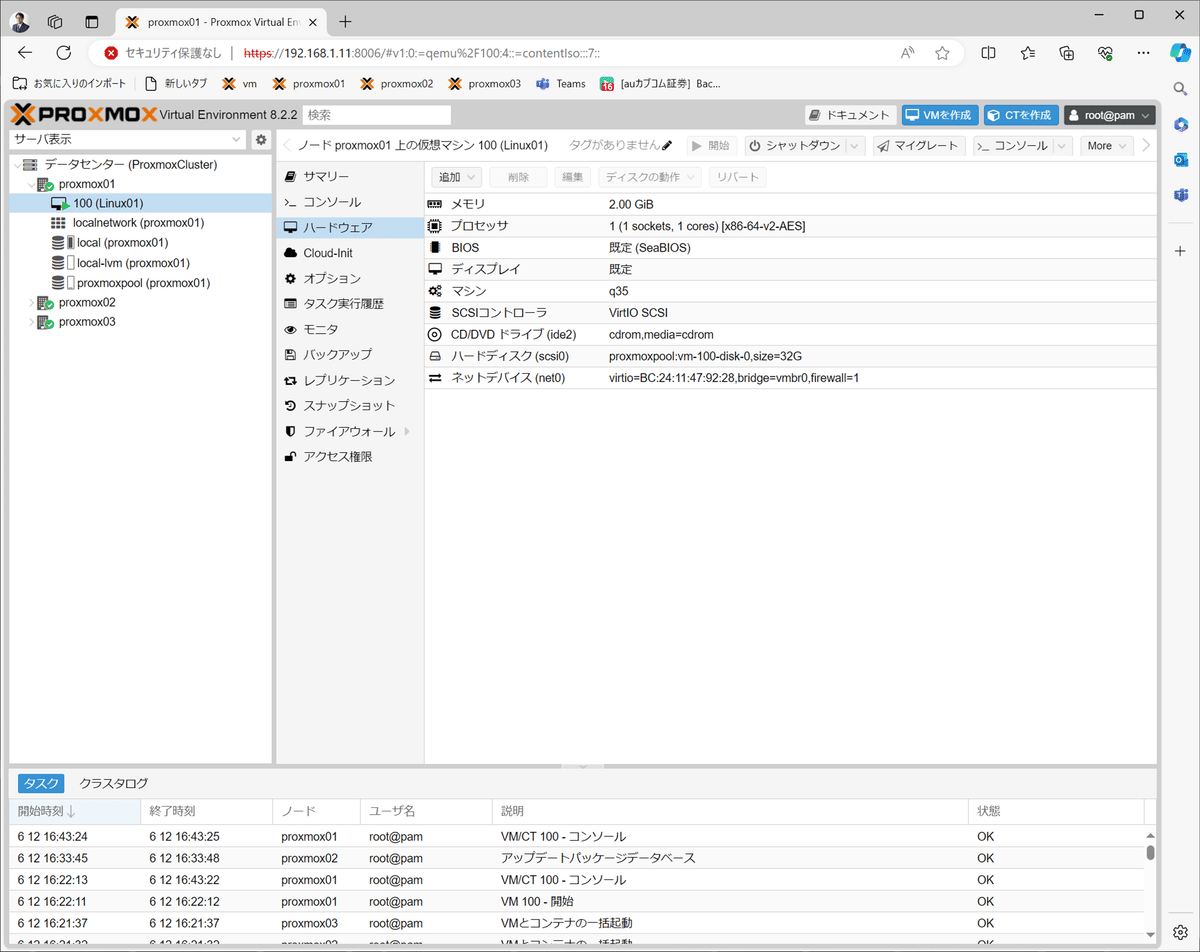
6)ライブマイグレーションを試す
以下の観点にて、ライブマイグレーションを実施してみました。
【確認観点】
仮想マシン上でアプリケーションが動作中に、その仮想マシン自体を移動(マイグレート)しても、移動先のProxmox VE上で、アプリケーションが動作し続けるか。
【確認結果】
想定通りの動きをしました。
マイグレート前

マイグレート実行
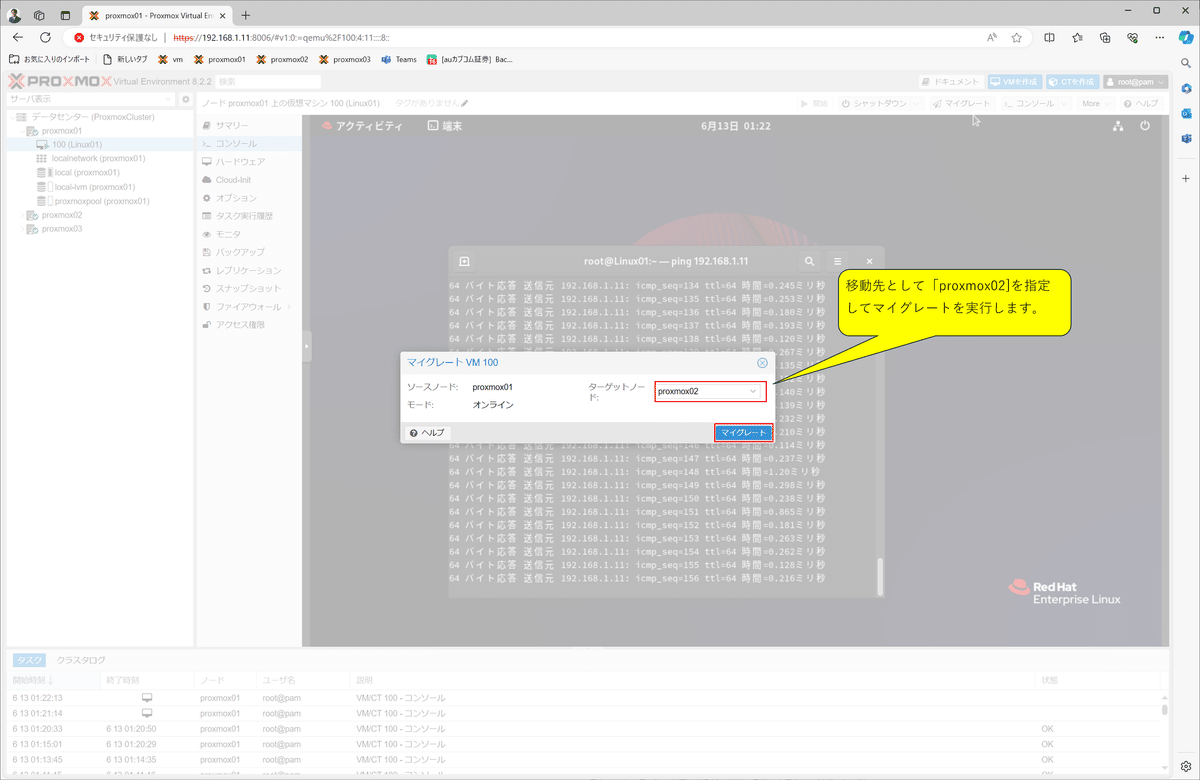
マイグレート後

6.仮想マシン設定後の状態
以下にクラスタ構成後の状態を示します。
Proxmox VEの操作および仮想マシンの操作は、「192.168.1.90」の「Windows PC」より行います。

7.HAの設定
HA(高可用性)とは何か?
Proxmox VEにおけるCephを使ったHA(高可用性)は、以下の観点を満たすことで実現出来ます。
■単一障害排除
複数台のホスト/ノードを準備し、それぞれローカルにOSDストレージを持ち、仮想マシンを同期することで単一障害を排除できます。稼働中ホスト/ノードで障害が発生した場合でも、クラスター内の別のホストで仮想マシンを実行できます。
■ダウンタイム削減
「ha-manager」と呼ばれるソフトウェアに、管理する仮想マシンを設定し、仮想マシンの稼働監視をします。稼働中ホスト/ノードで障害が発生した場合には、自動的に仮想マシンを別ホスト上のノードへフェールオーバーします。
なお、HA(高可用性)には代償が伴います。高品質のコンポーネントは高価であり、Proxmox VEにおいてCephで冗長化すると、コストが少なくとも3倍になります。したがって、メリットを慎重に計算し、コストを比較する必要があります。
1)HAグループの追加
Proxmox VEで、HA(高可用性)を設定する場合、まず始めに、HAグループを作成します。
HAグループ作成開始

HAグループ名設定

作成後の確認

2)HAリソースの追加
次に、「ha-manager」に対して、監視対象の仮想マシンを設定します。
リソースの指定開始

監視対象の仮想マシンIDを設定
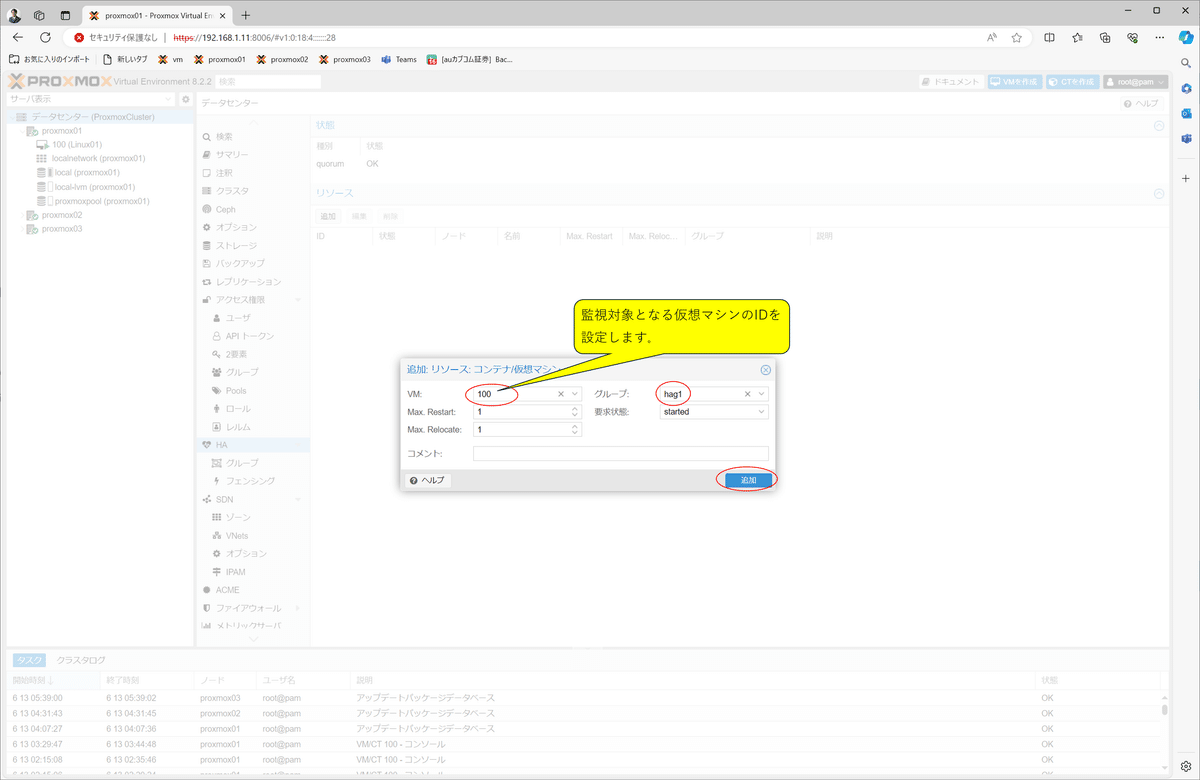
作成後の確認
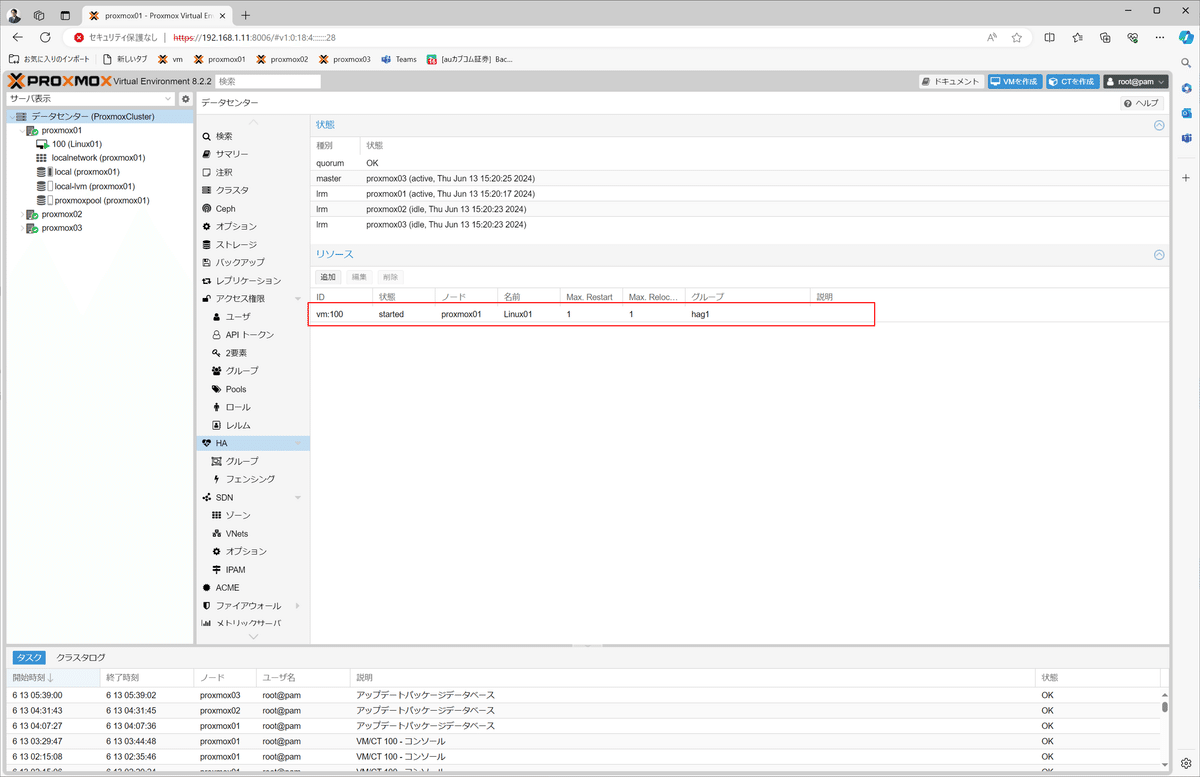
8.フェールオーバーを試す
ノード障害が発生した場合、他のノードで仮想マシンが自動的に立ち上がるか、確認します。
ノード停止前の状態

proxmox01ノードを強制停止
しばらくすると、優先順位が一番高いノードで仮想マシンが起動
ただし、ライブマイグレーションのように稼働状態を引き継ぐことは出来ません。起動しただけの状態です。

9.発生したトラブルなど
1)名前解決エラーの問題
Proxmox VEでクラスタを使う場合、全ノードの名前解決が必要です。 IPアドレスからホスト名、およびその逆が正しく出来るように、DNSまたはhostsファイルに記載する必要があります。
今回のクラスタの検証をするにあたって、3つのProxmox VEをインストールし環境構築しました。 名前解決が出来ていない(hostsに未設定)状態でCephをインストールしたら、Cephのモニターがぐるぐる回って、通信エラーになりました。 いったん、Cephをアンインストールし、hostsを設定してから再度Cephをインストールしたら、問題なく動きました。
2)ネットワークの負荷問題
クラスタのデータを各ノードと同期する場合、やはりネットワーク・セグメントを分けないと、仮想マシンの動作に影響があるようです。 応答が遅くなったり、反応が遅くなりました。 このため、バック側の専用セグメントで同期をとるようにしました。
3)ディスクの速度問題
やはり、高速なディスク(NVMe PCIe Gen4)を使わないと、仮想マシンの動作に時間が掛かりました。 Linuxだし、容量も小さいのでHDDでも良いかと思いましたが、ダメでした。
4)クラスタ構成上の問題
各ノードのCPUコア数、メモリ、ディスク容量を全て同じ(超過はOK)にしないと、たとえば、必要コマ数が足りないとか、必要メモリ数が足りないなどあると、マイグレート機能で移動した先のノードで、仮想マシンを動かすことが出来ません。 構築当初、CPUのコア数が違ったりメモリ容量が違う物理マシン環境でノード構築しており、仮想マシンをマイグレート機能で移動したら起動エラーになって気が付きました。 また、OSD用のディスクは、容量だけでなく、その物理ディスク構成/デバイス構成も同じにする必要がありました。
5)コスト削減効果?
HA構成を行う場合、別筐体で、同一のCPU、メモリ、ディスク構成を3セット準備する必要があります。 高品質のサーバ資源は高価ですし、それを2セット遊ばせているようなモノなので考えどころです。
ストレージ・レプリケーションを使った冗長化構成であれば、2セットを準備すれば、稼働系と待機系として運用できます。 障害時のリアルタイム性を必要としない工夫が出来れば、15分間隔(最小の設定値)の仮想マシン同期でも十分運用に耐えることができると思います。
執筆者プロフィール:尾﨑 英一
1995年より某System Integrator(SIer)にて、大小さまざまなプロジェクトに従事。
2000年まではUNIXとC、2000年以降はLinuxとJavaが中心だが、Windows ServerとC#.Netも経験。
ここ10年ぐらいは、マネージャとしての管理業務が多いが、自身で手を動かす案件も多数経験。
本人はアプリケーション系エンジニアのつもりだが、周りはインフラ系エンジニアと思っているらしい。
60歳定年が見えていた2023年に、70歳まで働けるSHIFTに入社。
趣味は、合気道、スキューバダイビング、ロードレーサ。2023年からクレー射撃をはじめた。
お問合せはお気軽に
https://service.shiftinc.jp/contact/
SHIFTについて(コーポレートサイト)
https://www.shiftinc.jp/
SHIFTのサービスについて(サービスサイト)
https://service.shiftinc.jp/
SHIFTの導入事例
https://service.shiftinc.jp/case/
お役立ち資料はこちら
https://service.shiftinc.jp/resources/
SHIFTの採用情報はこちら
https://recruit.shiftinc.jp/career/