
PICTを使い倒そう! ~ PICTが持つ便利な機能

こんにちは。自動化エンジニアの水谷です。
前回は、2因子間網羅でテストケースを削減する便利なツール“PICT”について、論文を参考にしてそのアルゴリズムを中心に記事を書きました(こちら)。そこでも書きましたように、その論文には、PICTに以下のような便利な機能があることと、それらについての解説も書かれています。
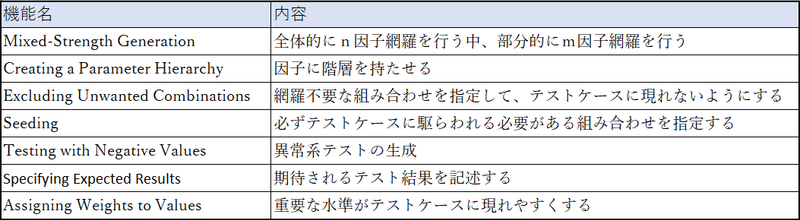
そこで、今回はこれらの機能について、それぞれがどのようなもので、そしてどのように使うのかを書いていきたいと思います。
Mixed-Strength Generation
PICTは2因子間網羅だけでなく、任意の因子数についてそれらを網羅するテストケースが生成できるのですが、この(網羅する)因子数を部分的に変えることができます。例えば、全体的に2因子間網羅でテストケースの生成を行うけど、ある3つの因子については3因子間網羅を行いたいような場合に、このMixed-Strength Generationが使えます。
具体的な例を挙げてみます。

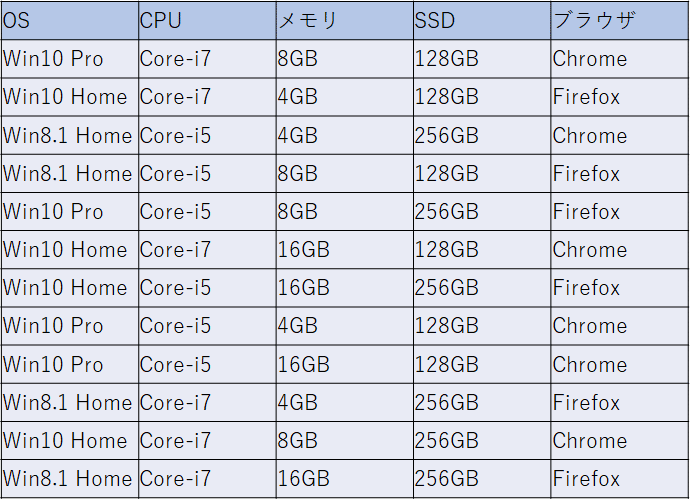
上の表のような因子と水準からテストケースを作る場合において、基本的に2因子間網羅でテストケースを作るのですが、CPU、メモリ、SSDの3つの因子については、3因子間全網羅を行いたいとします。このような場合、PICTの入力ファイルを次のように、3因子間全網羅を行いたい因子に“@3”を付けて記述することで、期待するテストケースが生成されます。
OS: Win10 Home, Win10 Pro, Win8.1 Home
CPU @ 3: Core i7, Core i5
メモリ @ 3: 4GB, 8GB, 16GB
SSD @ 3: 128GB, 256GB
ブラウザ: Chrome, Firefox, Edge下が生成された組み合わせです。確かにCPUとメモリとSSDの間については3因子間網羅されていますね。
Creating a Parameter Hierarchy
次の機能であるCreating a Parameter Hierarchyは、はその名の通り因子に階層を持たせる機能なのです。上と同じ因子と水準を例にして見ていきましょう。
この例では因子が5つありますが、その中のCPU、メモリ、SSDはハードウェア関連の因子であり、それ以外のOSとブラウザはソフトウェア関連の因子です。ソフトウェアは再インストールすることで比較的短時間にその水準を満たすことができるのですが、ハードウェアについては調達に時間がかかったり、費用が発生したりするため、できるだけ種類を少なく抑えたい場合があります。
このような場合に、ハードウェア関連の因子はひとまとめにして、先に2因子間網羅を行っておき、できた組み合わせを新たな水準として使用すれば、ハードウェア関連については少ない組み合わせになりますよね。
PICTのモデルファイルでこれを記述するには以下のようにします。
OS: Win10 Home、Win10 Pro、Win8.1 Home
CPU: Core-i7, Core-i5
メモリ: 4GB, 8GB, 16GB
SSD: 128GB, 256GB
ブラウザ: Chrome, Firefox
{ CPU, メモリ, SSD } @ 2最後の行が、これら3つの因子を先に2因子間網羅することを表しています。
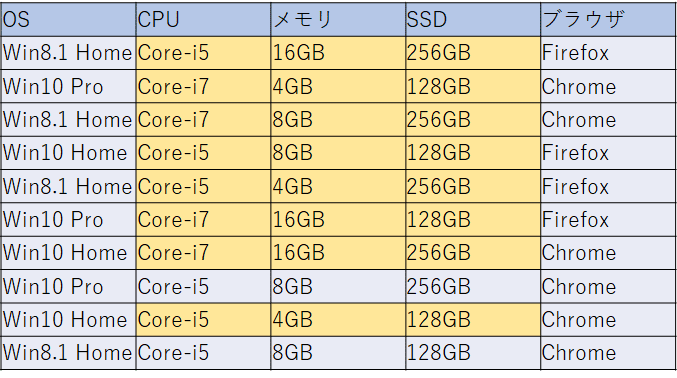
その結果は下のようになりました(いずれも/r:1でランダムシードを1にした場合)。まず、階層を使わない通常のモデルでは、下の表でオレンジ色にハイライトしたように7つのハードウェア構成が組み合わせに出てきます。
これに対して、階層を指定して実行した場合は、下のようにハードウェア構成は6つに下がりました。
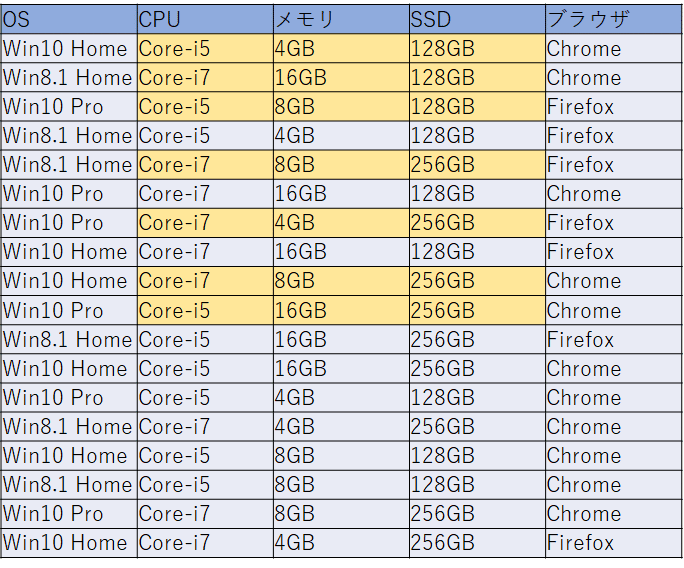
7つが6つに下がっただけでは大きなメリットが無いようにも見えますし、組み合わせ数は逆に増えてしまっています。もしもう少し階層化する因子数や水準数が多くなれば、そのメリットは大幅に大きくなる可能性がありますので、試してみる価値はあると思います。なお、もしハードウェア構成を完全に固定したいのであれば、次に紹介する”Excluding Unwanted Combinations”を使うほうが良いかもしれません。
また、このPICTの論文では、この機能のもう1つのメリットとして、関数のユニットテストを行う場合において、その引数の1つに配列が含まれている場合などには、この階層を使うことが有用だと書かれています。
Excluding Unwanted Combinations
続いての機能は、テストケースとして表れてほしくない組み合わせを指定して排除する機能です。例えば、OSの水準が変わって、Ubuntu 18.04LTSでのテストも行うことになったとします。この時、Ubuntu用のEdgeは今(2020年7月初旬現在)のところまだリリースされていないので、OSがUbuntuの場合はEdgeが選ばれないようにしたいところです。
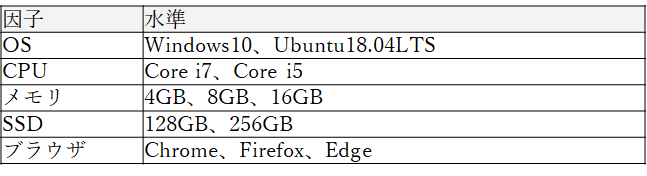
このような場合は、下の用にモデルファイルを記述します。
OS: Windows10, Ubuntu18.04
CPU: Core-i7, Core-i5
メモリ: 4GB, 8GB, 16GB
SSD: 128GB, 256GB
ブラウザ: Chrome, Firefox, Edge
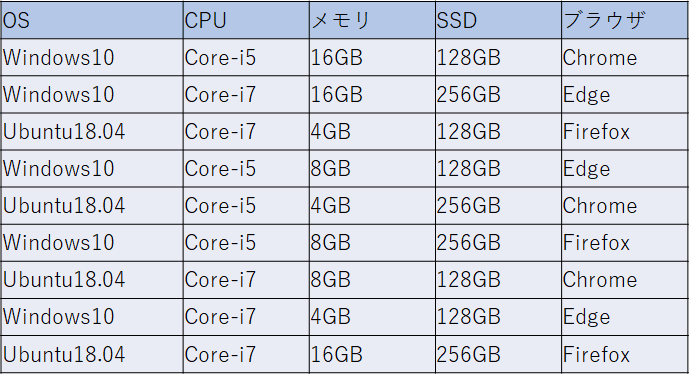
IF [OS] = "Ubuntu18.04" THEN [ブラウザ] <> "Edge";最後のIF文の記述によって、OSがUbuntuの場合はブラウザにはEdge以外からしか選ばれない、つまりEdgeは選ばれないようになります。実際にPICTを実行した結果も下のように、UbuntuとEdgeの組み合わせは現れませんでした。
Seeding
Pairwiseにおいては、テストケースに必ず現れさせたい組み合わせを“Seeds”と呼ぶことがあります。PICTにも、このSeedsを記述する方法が用意されていますので、紹介します。
Seedsを記述することで達成できる事柄は2つあり、1つ目は、重要なテストケースをSeedsに記述しておくことで、これが必ずカバーできることであり、2つ目は、因子や水準の小さな変更によって、テストケース全体が大幅に変わってしまうことを防ぐことです。1つ目は明らかで、例えば過去のテストでバグが発見された組み合わせは必ず網羅しておきたい場合などがこれに当てはまります。2つ目はややわかりにくいで、具体例を見てみましょう。
以下のような因子と水準があったとします。

これをPICTで2因子間網羅テストケースを作るとこのようになります。
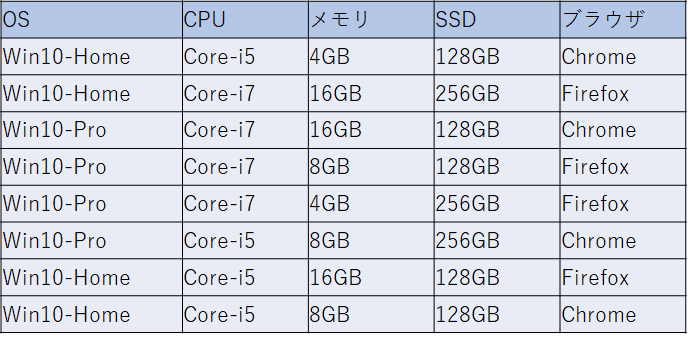
これに従ってテストを実行していたところ、テスト要求に変更が入り、ブラウザとしてChromeとFirefox以外にEdgeでもテストを行わなければいけなくなったとします。
モデルファイルを変更して、再度PICTを実行したところ、下のような組み合わせが生成されてしまいました。
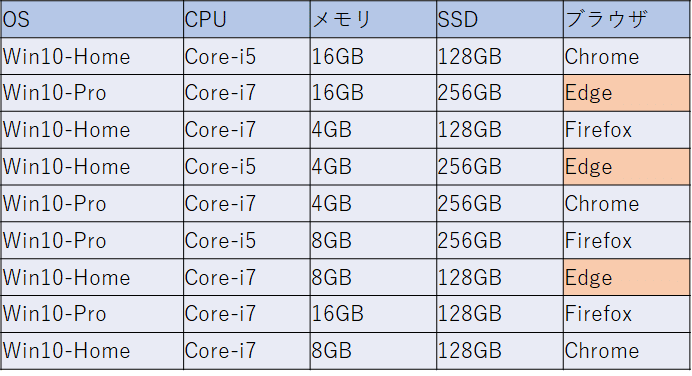
2つの表を比べてみると、後者は明らかにこれまでテストしてきた組み合わせ(前者)とは異なってしまっています。もし、テストがかなり進んでいた場合、それらを捨てて新しい組み合わせでテストを再度行うのは大きな時間とコストのロスになるでしょう。
そこで、テキストファイルを1つ用意し、そこに前回の(Edgeがなかった時の)PICTの出力をそのまま記入しておきます。そして、これをSeedsとしてPICTを “/e:<Seedsファイル名>” のオプションで実行します。すると、Seedsに記入した組み合わせをそのまま含んだ、以下のような組み合わせが得られます。
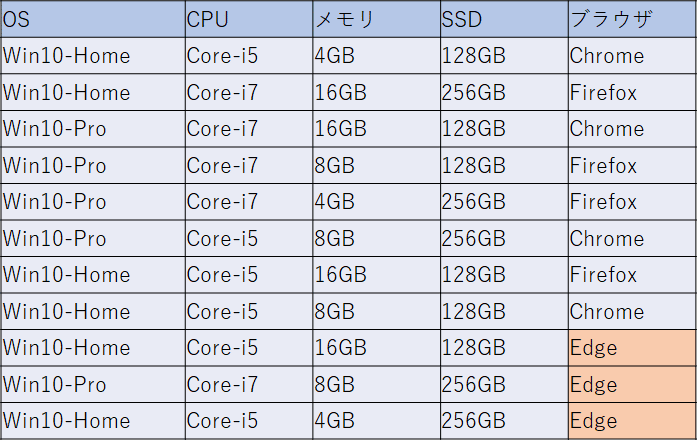
これにより、これまでのテスト結果を捨てることなく、追加されたEdgeが含まれる組み合わせのみを追加で実行すればテストが完了することになります。
なお、(この例のように)Seedsを使わずにPICTに組み合わせを作らせた場合に対して、組み合わせ数が増える可能性があることには注意が必要です。
Testing with Negative Values
PICTには異常系のテストを含んだ組み合わせを出力する機能もあります。例えば、引数が2つのある関数のテストを行う場合において、以下のような値でテストを行いたい場合を考えます(正常値も異常値もたくさんがんが得られますが簡単のため2個ずつとします)。

ここで、異常値も含めてそのままモデルファイルに記述してしまうと、異常値が両方に現れる組み合わせも生成されてしまいます。たとえば0と123の組み合わせがそれにあたりますが、この組み合わせでテストを行った場合に結果がFAILとなっても、どちらの変数の影響でFAILとなったのかはわかりません。異常系のテストを行う場合は、異常なパラメーターは1つだけに限定する必要があるのです。
PICTでは異常系の因子には”~”を先頭に記述するというルールがあり、こうしておくことで、その異常系の因子が複数含まれたテストケースが生成されないようになります(論文では"~"ではなく"*"を使う、となっていますが、現在のバージョンのPICTでは"~"を使うように変更されました)。
この例ではモデルファイルは以下のように記述すればOKです。
Param1: ~0, 1, 10, ~11
Param2: AAA, ZZZ, ~123, ~A1BこれをPICTで処理すると、以下のようなテストケースが生成されます。
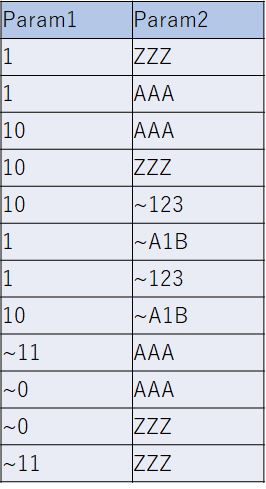
上の4つは正常系で、それ以下は異常系となり、異常系では異常なパラメーターはそれぞれ1つしか現れないことがわかります。
Specifying Expected Results
上のように異常系のテストも含めて生成できるようになると、そのテストケースの期待値(Passするのかが期待されているのか、Failするのが期待されているのか、またFailするのであればどのようなエラーが表示されるか等)も記述しておかないとテスターが混乱する可能性がでてきます。例えば下の例を見てみましょう。

Param1に異常系としての0と11、Param2にも異常系として”123”を含めています(実際にはもっと異常系の水準を入れるべきでしょうが、ここでは簡単のためこれだけにしています)。この場合の期待されるテスト結果としては、どちらも正常系であれば”Pass”、Param1が範囲外であれば”OutOfRange”、Param2が3文字のアルファベットでなければ“Invalid”と、テストケース中に記述したい場合、下のようなモデルファイルを記述すれば、これらの文字列も含んだテストケースを生成してくれます。
Param1: ~0 ,1, 10, ~11
Param2: AAA, BBB, ~123
$Result: Pass, OutOfRange, Invalid
IF [Param1] >= 1 AND [Param1] <= 10 AND
[Param2] IN { "AAA", "BBB" }
THEN [$Result] = "Pass";
IF [Param1] < 1 OR [Param1] > 10
THEN [$Result] = "OutOfRange";
IF [Param2] = "123"
THEN [$Result] = "Invalid";ポイントは“$Result”という特殊なパラメーターを定義しておき、IF文で判定して適当な値を代入するようにしている点です。これによって、下のようにテストケースに期待される結果も含まれた組み合わせが作成されます。
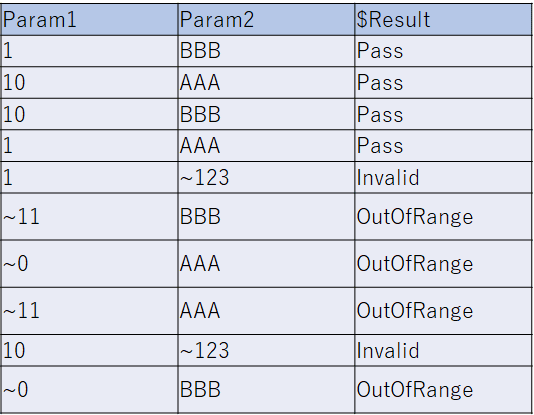
この例では簡単すぎるので、期待値は不要かもしれませんが、因子1つだけでは異常系のテストと判断できない異常系を含む場合(複数の正常な因子の組み合わせでも異常系となる場合、例えば因子1と因子2それぞれにおいて正常系の水準が選択されているが、因子1と因子2の値が同じであることは許容されないような場合)などにおいて便利な機能と言えるでしょう。
Assigning Weights to Values
最後の機能は水準への重み付けです。経験的にある水準が他のものより重要だと知っている場合がありますよね。通常PICTではすべての水準を同等に扱っており、選択可能な水準が複数ある場合はランダムに選ばれます。ここで、水準に重み付けをしておき、その重要だと考えている水準がより選択されやすくすることができます。
下の因子と水準において、赤字で書いてある水準がより重要という場合を考えてみましょう。

これら赤字の因子が優先的に選ばれるようにしたい場合には、モデルファイルを例えば以下のように記述できます。
OS: Win10Home (1), Win10Pro (2)
CPU: Core-i7, Core-i5
メモリ: 4GB (1), 8GB (5), 16GB (1)
SSD: 128GB (2), 256GB (1)
ブラウザ: Chrome(10), Firefox(1), Edge(1)このように因子の後に括弧を書きその中に数字を書くのですが、選択されてほしい因子には大きな数字を記述しておきます。あくまで複数の候補があった場合に、その中から数字が一番大きいものが選択される、ということなので、数字がどれだけ大きいか、という点は考慮されません。
これをPICTで処理すると、以下のような組み合わせが生成されました。よく見ていくと、わずかではありますが、赤字の因子が他と同じか、より多く現れていることがわかります。
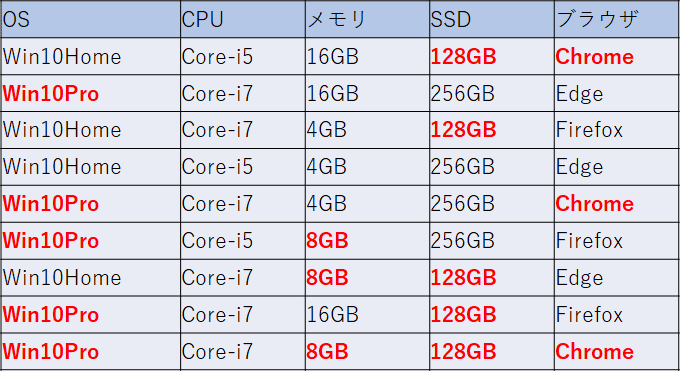
なお、PICTにおけるこのWeight機能は、数字が大きい因子が必ず多く出ることは保証されていません。先ほども書きましたように、複数の因子が選択できる状態になった場合のみ、(ランダムではなく)この数字をもとに選択するということになので、場合によっては大きい数字を書いておいても、テストケース中に現れる回数が少ない、という可能性も0ではありません。
まとめ
PICTが持っている機能を見てきましたが、思ったより多くの機能があるんだな、と思われたのではないでしょうか?
PICTを2因子間網羅テストケースの生成だけでも十分に有用なツールですが、これらの豊富な機能を活用することで、より効率的な、より自分の望むものに近いテストケースの生成が可能になりますので、いろいろ試しながら活用してみてはいかがでしょうか。
――――――――――――――――――――――――――――――――――
執筆者プロフィール:水谷裕一
大手外資系IT企業で15年間テストエンジニアとして、多数のプロジェクトでテストの自動化作業を経験。その後画像処理系ベンチャーを経てSHIFTに入社。
SHIFTでは、テストの自動化案件を2件こなした後、株式会社リアルグローブ・オートメーティッド(RGA)にPMとして出向中。RGAでは主にAnsibleに関する案件をプレーイングマネジャーとして担当している。
お問合せはお気軽に
https://service.shiftinc.jp/contact/
SHIFTについて(コーポレートサイト)
https://www.shiftinc.jp/
SHIFTのサービスについて(サービスサイト)
https://service.shiftinc.jp/
SHIFTの導入事例
https://service.shiftinc.jp/case/
お役立ち資料はこちら
https://service.shiftinc.jp/resources/
SHIFTの採用情報はこちら
https://recruit.shiftinc.jp/career/