

PythonでAWSのElastiCacheを操作する

こんにちは。RGAでインフラエンジニアをしている浅野です。
少し前にとある案件でElasiCache(Redis)を調べながらPythonで操作してみたので、実際にどのようなコードで操作したのか書いてみたいと思います。
なお、ElastiCacheを一言で言い表すと、リアルタイムなどデータ処理に向いたKey-Value型データベースのようなもの、という感じでしょうか。こちらにElasticCacheの概要がありますので合わせてご確認ください。
ElasticCacheのAWS上での設定
AWS上での作業の流れは以下のようになります。
1. AWS上でElastiCacheのクラスターを立ち上げセキュリティグループを作成
2. Lambda関数を作成する
3. その関数に付与されているIAMにポリシーをアタッチ
それぞれについて見ていきましょう。
ElasticCashのクラスターを立ち上げる
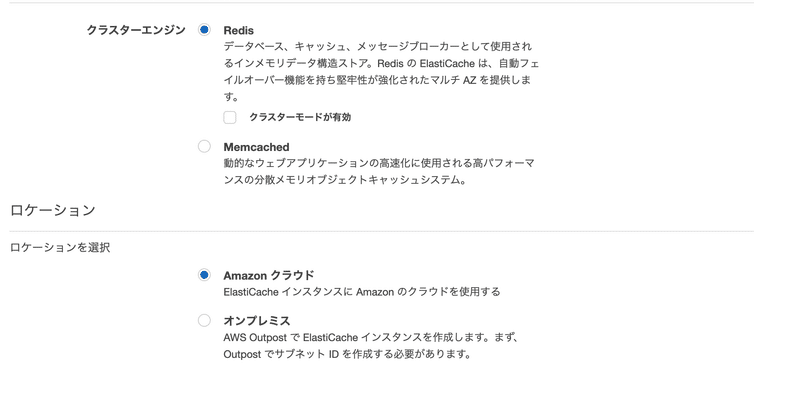
ElastiCacheページを開くと左側に(インメモリデータストアの)MemcachedとRedisの選択肢が現れますので、今回はRedisを選択して進めます。
「作成」ボタンを押して下の画像と同じように選択をしてください。
続いて名前の入力とノードのタイプの選択を行います。
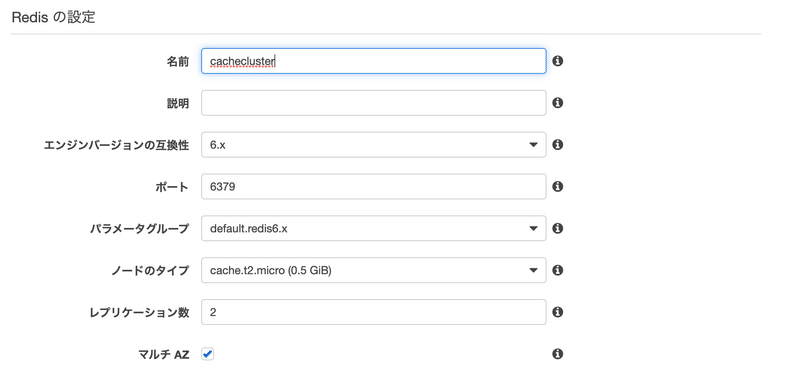
今回はテストのため、無料枠のt2.microを選択しました。
その下でセキュリティグループを選べるので、選択後そのセキュリティグループ名を覚えておいてください。
Lambdaでの設定
続いてLambdaで関数を作成します。
ファイル名は "lambda_function.py" として、Redisに接続して1つのKey(key1)に値をセットし、それを読み出すだけの簡単なElastiCacheを使うスクリプトを作成します。
import redis
def lambda_handler(event, context):
r = redis.StrictRedis(host='ここにエンドポイントを書く', port="ElastiCacheのポート番号", db=0)
r.set("key1", "value1")
print(r.get("key1"))
return "成功"ここのままzipにしてアップロードをしてもlambdaでredisのライブラリがなくてエラーになってしますので、以下のコマンドを先ほど作ったのと同じディレクトリで実行します。
pip3 install redis -t ./
zip -r upload.zip *作成されたzipをlambdaにアップロードします。
しかし、このままデプロイしテストをしてもエラーになってしまうので、lambda関数とElastiCacheに付与されているセキュリティグループにカスタムTCPでElastiCacheのポート番号を追加します。
それが終わったら「テスト」ボタンを押してreturnに書いてある『成功』が出れば問題なく動いていると判断できます。
タイムアウトになる場合は、おそらくポートが開いてないことが原因なので、セキュリティグループを確認してください。
ElasticCacheを操作してみる
さてここからコードを追加してElastiCacheを操作していくのですが、上記lambda関数の r= のラインから return の間に下のコードを追記していくことになります。
まずは、key "a" に「aの値をset」というコメントをElastiCacheに保存をするコード、およびそれを有効期限付きで行うコードです。
r.set("a", "aの値をset")
#有効期限(10s)をつける
r.set("a", "aの値をset", ex=10)上で保存した値を読み込んで表示させるコードは下のようになります。
print(r.get("a"))すでにsetされた値に後から有効期限を設けることもできます。
r.expire("a'", 10)これで最初に設定したaの値は10秒後に自然消滅します。
調べてみると下のように書くことでsetを実行する際に日時も設定できるようです。
r.set('a', datetime.datetime(2021, 4, 3, 12))このコードでは、aが2021/4/312時に消去されます。
リストの扱い方は以下の通りrpushで行います。
r.rpush('key01', 'A') # 1
r.rpush('key01', 'B') # 2
r.rpush('key01', 'C') # 3保存されたリストのデータを扱うには、以下のようにします。
#先頭から3つだからAとBとCが表示される
print(r.lrange('key01', 0, 2))
#typeがリストであることを確認
print(type(r.lrange('key01', 0, 2)))
#typeがリストだからforループでも問題なく使える
for i in r.lrange('key01', 0, 2):
print(i)データはリスト型で保存されているので取り出したあとは for や while でのループが可能です。
その他のデータの扱いかたはこちらを参照してください。
Keyを指定して保存する
実際の業務などではredisはユーザー毎などに保存することが多いのでKeyで保存してみます。
keyで保存するには、hmsetを使います。
key="キー名"
r.hmset(key, {
'user': "ユーザー名",
"email": "メールアドレス",
})Keyで保存した中身を表示する
Keyを指定して、hgetallをコールすると辞書で表示されます。
key="キー名"
data = r.hgetall(key)
print(data)辞書の中身がbyteなので文字列として表示するためstrに変換してみます。
def decode_str_dict(data):
#辞書.keys()
d = {}
for i in data.keys():
print(i)
key = i.decode()
d[str(key)] = data[i].decode()
print
print(d)
return d先ほど取れた辞書を引数に入れると中身の値がキーも含めてstrに変換されて帰ってきます。
参考サイト
https://ohke.hateblo.jp/entry/2018/06/09/230000
https://pypi.org/project/redis/
https://qiita.com/FukuharaYohei/items/48209d488bc7f412c3d7
__________________________________
執筆者プロフィール:浅野 裕紀
アメリカ留学中に労働ビザがないためネットでpythonを中心に知人等から仕事を数年請負。Web系のプログラミングを請負始めてからクラウドでのDjangoを使った開発をメインに活動。
現在はPython(Lambdaのスクリプト)、AWSのCloudFormationのテンプレート作成を中心に案件に参画。
個人ではDjangoのシングルサインオンのライブラリ(現在test用のpipからダウンロード可能)などをオープンソースとして開発しています。
【ご案内】
ITシステム開発やITインフラ運用の効率化、高速化、品質向上、その他、情シス部門の働き方改革など、IT自動化導入がもたらすメリットは様々ございます。
IT業務の自動化にご興味・ご関心ございましたら、まずは一度、IT自動化の専門家リアルグローブ・オートメーティッド(RGA)にご相談ください!
お問合せは以下の窓口までお願いいたします。
【お問い合わせ窓口】
代表窓口:info@rg-automated.jp
URL: https://rg-automated.jp
